

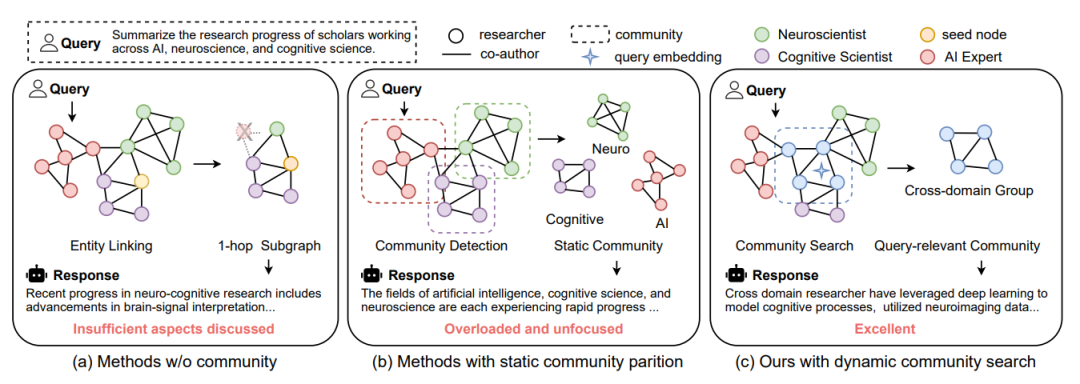
当前主流的GraphRAG(如微软GraphRAG、ArchRAG)存在一个致命缺陷:它们依赖离线预计算的静态社区划分。就像把图书馆的书籍提前分好类贴上标签,当用户问"某跨部门项目的人员协作情况"时,系统只能机械地返回预设的"部门A"或"部门B"信息,而无法动态整合跨边界的关键内容。
更基础的G-RAG方法(如LightRAG、HippoRAG)则陷入另一极端——仅利用低阶图结构(1跳邻居、简单路径),如同只看书籍的目录和相邻章节,无法捕捉知识间的高阶关联。
DA-RAG的破局之道
中山大学与香港理工大学团队提出的DA-RAG(Dynamic Attributed Community Search for RAG),首次将图分析领域的"属性社区搜索(ACS)"技术引入RAG系统,实现了查询驱动的动态子图检索。本文已收录到WWW 2026。
三层索引+粗到细检索
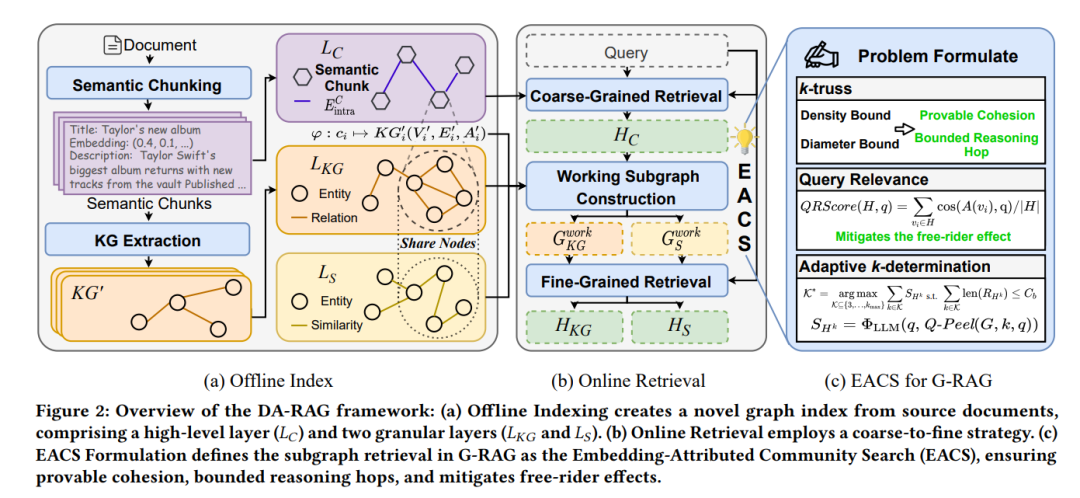
离线构建"块导向图索引"
-
语义块层(LC):将文档切分为语义连贯的文本块作为高层节点,保留叙事逻辑 -
知识图谱层(LKG):提取实体关系,保留结构化语义 -
相似度层(LS):基于向量相似度补充语义边,缓解图谱稀疏性
三层通过跨层链接形成"双层级、多视角"索引,彻底规避昂贵的图聚类计算。
在线"粗到细"检索
-
粗检索:在语义块层运行EACS算法,快速定位高层语境社区HC -
工作子图构建:利用跨层链接,从HC映射到LKG和LS层的相关实体 -
细检索:在工作子图上再次执行EACS,获取精细化的知识社区HKG和HS
EACS:嵌入感知的社区搜索
核心创新在于将子图检索形式化为嵌入属性社区搜索(EACS)问题,要求检索的子图同时满足:
-
结构凝聚性:必须是连通k-truss(每条边至少参与k-2个三角形),确保主题一致性并限制推理跳数 -
查询相关性:最大化QRScore(社区节点与查询的嵌入相似度均值),规避"搭便车效应"(引入无关但结构紧密的节点) -
最大性:无法在不破坏上述条件的前提下扩展
针对该NP难问题,团队设计了Q-Peel启发式算法(算法1),通过迭代剥离低相关性节点,在多项式时间内逼近最优解。
实验结果
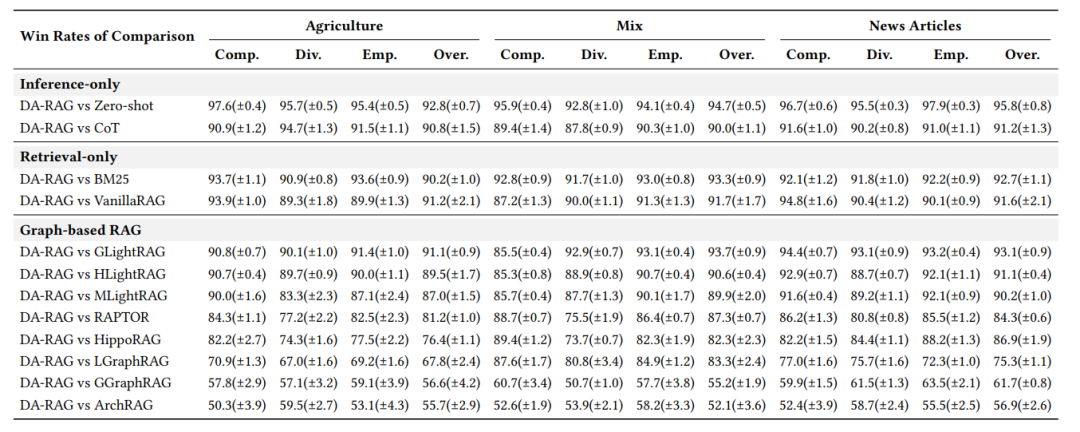
效果碾压:
-
相比微软GraphRAG-Global,在综合性、多样性、赋能性、整体效果上分别取得**59.5%、60.1%、57.3%、56.9%**的胜率 -
相比LightRAG系列,平均胜率超90% -
在农业、混合、新闻三个数据集上全面领先,最高胜率达**97.6%**(vs Zero-shot)
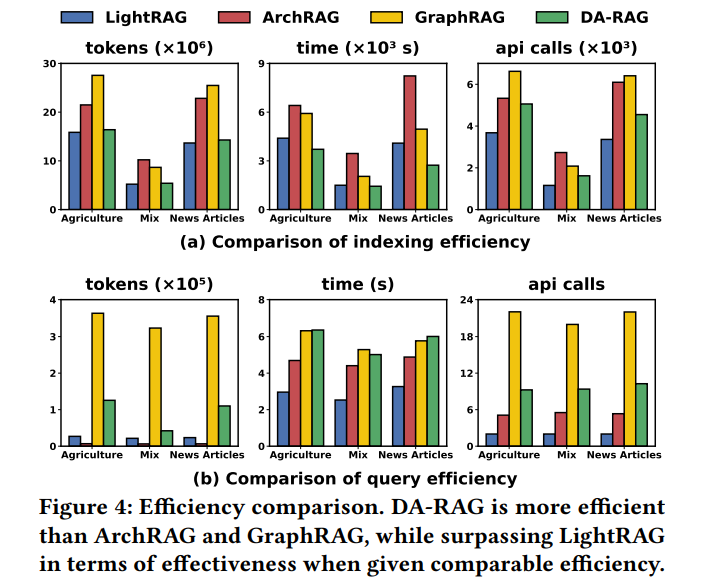
效率革命:
-
索引构建时间降低**37%,Token消耗减少41%**(对比GraphRAG) -
在线查询Token消耗仅为GraphRAG的**26%**(平均9.3次API调用 vs 21.3次)
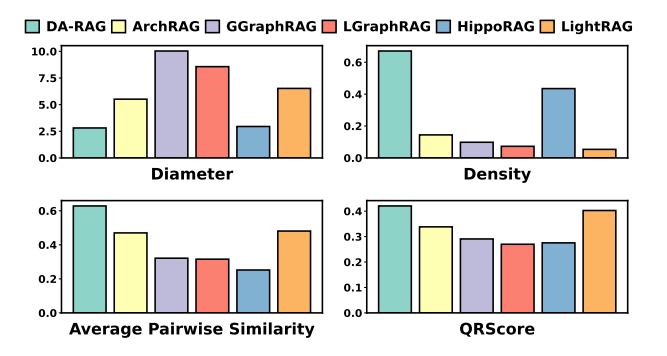
子图质量验证:
DA-RAG检索的子图在密度、直径、QRScore、节点相似度四项指标上全面优于基线,证明其能同时保证结构紧密性与语义相关性。
案例对比:动态vs静态社区
查询:名人代言如何影响消费者购买决策?
DA-RAG返回:
-
"泰勒·斯威夫特效应":特拉维斯·凯尔斯球衣销量飙升400% -
名人代言的品牌可见性原理 -
粉丝群体参与机制
GraphRAG返回:
-
FTX交易所的代言丑闻(与查询无关) -
针对Z世代的政治营销(偏离主题)
静态社区划分导致GraphRAG返回大量预计算社区的"噪音"信息,而DA-RAG的动态检索精准聚焦查询意图。
技术启示
DA-RAG的成功揭示了RAG系统进化的关键方向:**从"静态索引+向量匹配"转向"动态图分析+语义结构融合"**。通过将图挖掘中的高阶结构感知(k-truss社区)与大模型的语义理解能力结合,实现了知识检索的"因材施教"——每个查询都能获得量身定制的知识子图,而非从预设的"知识罐头"中取用。
DA-RAG: Dynamic Attributed Community Search for Retrieval-Augmented Generation
https://arxiv.org/pdf/2602.08545
https://doi.org/10.5281/zenodo.18296495