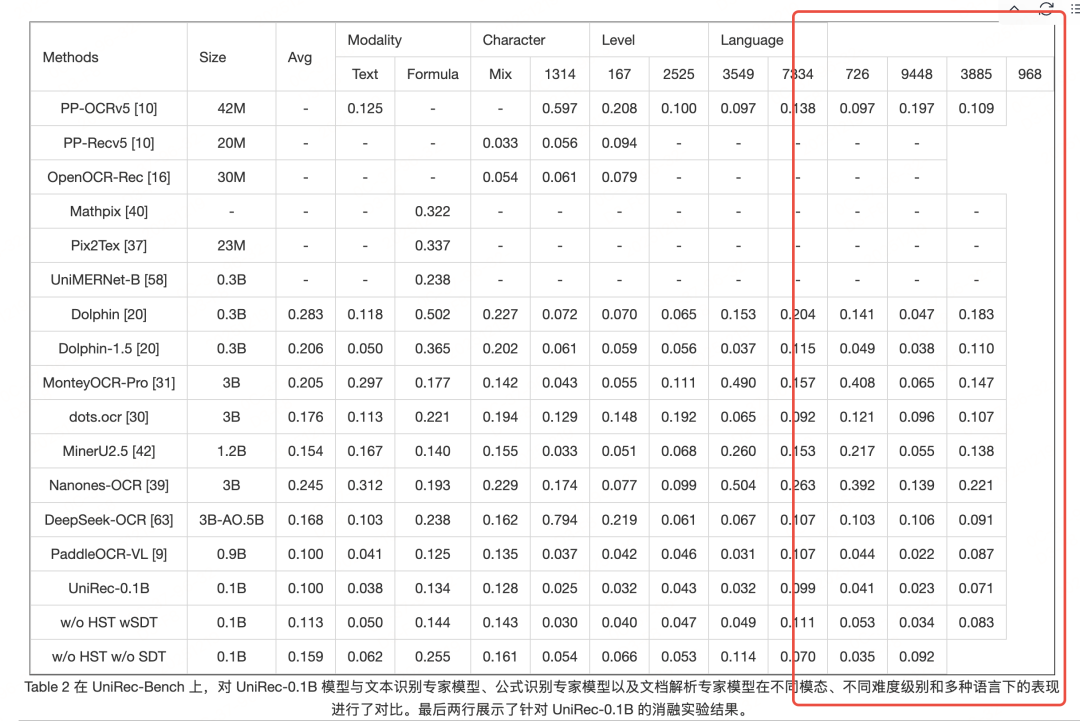
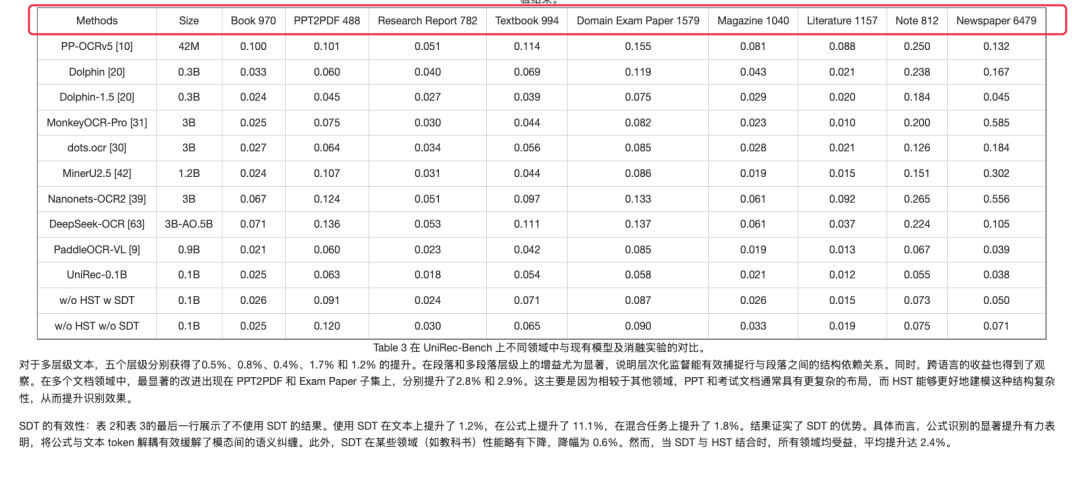
UNIREC是一个0.1B参数量的模型,整体pipline遵循layout(直接拿的paddleocr的layout模型)+ VLM OCR(UNIREC-0.1B)。从这个模型可以看一个趋势,VLM-OCR正在朝参数小进化。下面来看简单看下模型架构、数据情况、实际测试,性能实际测下来一般,仅供参考。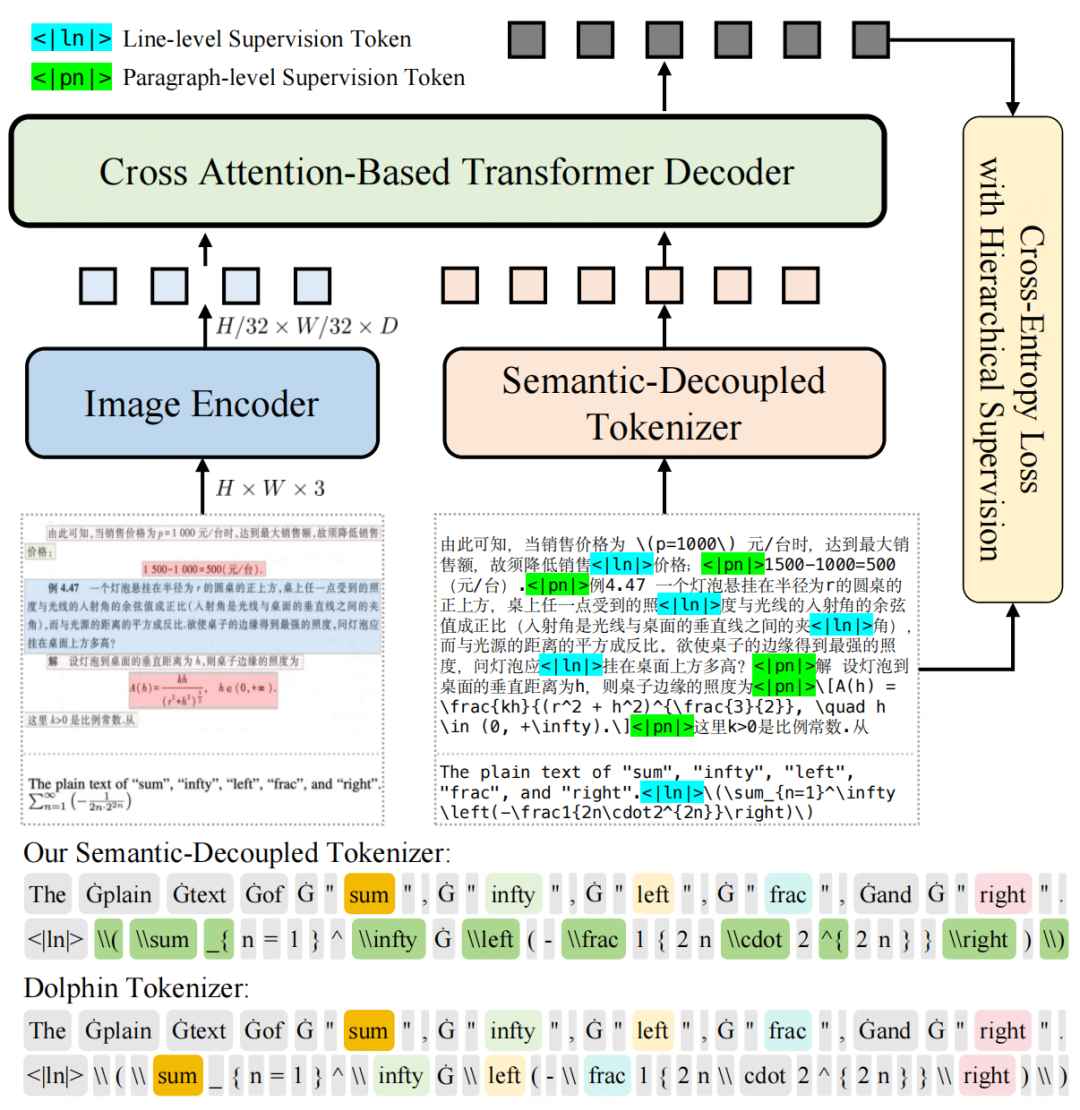
文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
-
再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法 -
如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法 -
端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法…
模型架构
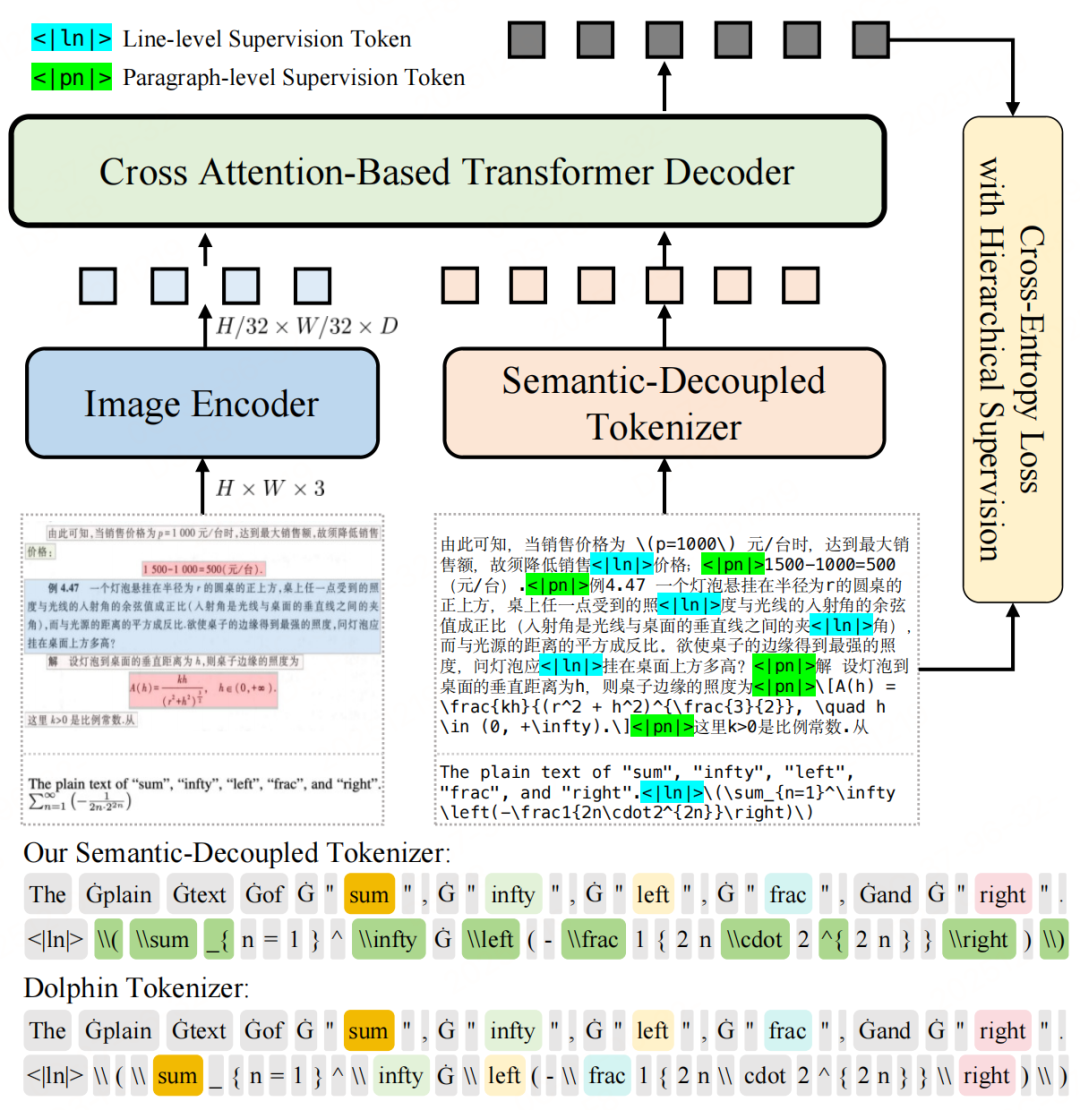
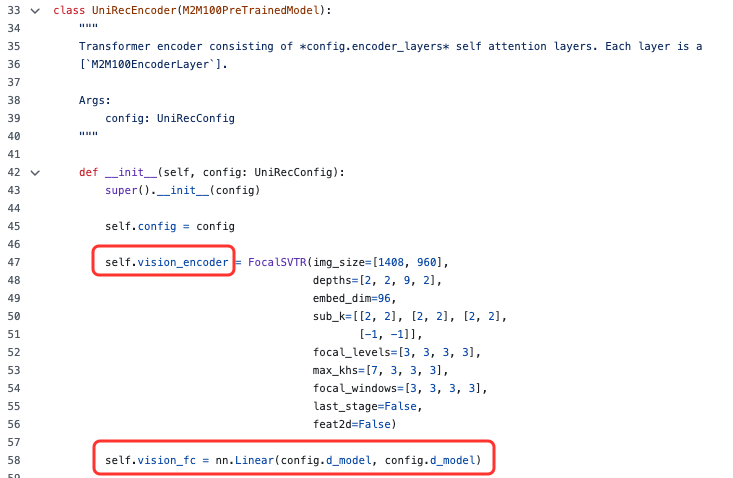
-
视觉编码器:FocalSVTR -
连接器:线性层 -
语言模型:M2M100
特别的:最大宽度和高度分别限制在 960 和1408 像素。
数据
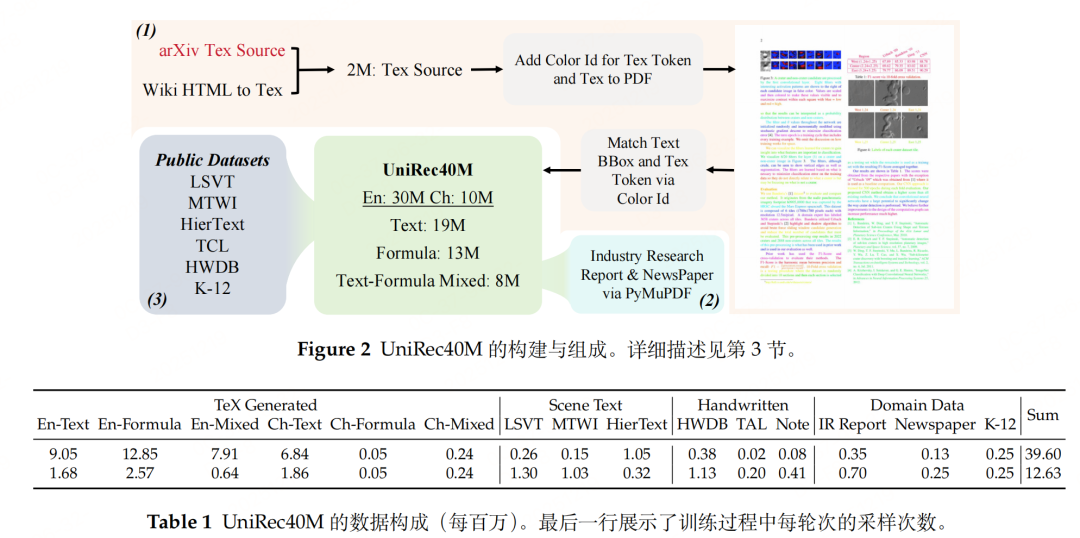
与paddleocr-vl、mineru等一样,训练UNIREC-0.1B时构造相关block(文本、公式、表格等)数据-UniRec40M(数据未开源)。
实验性能
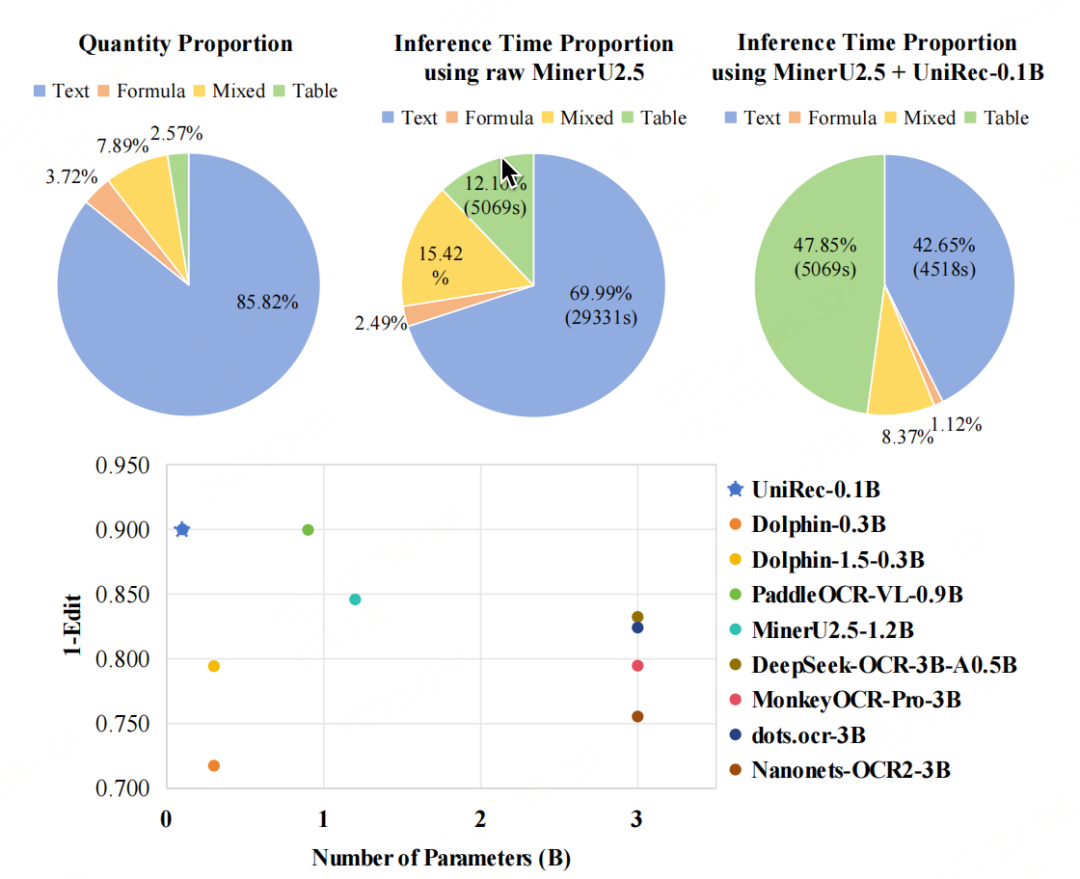
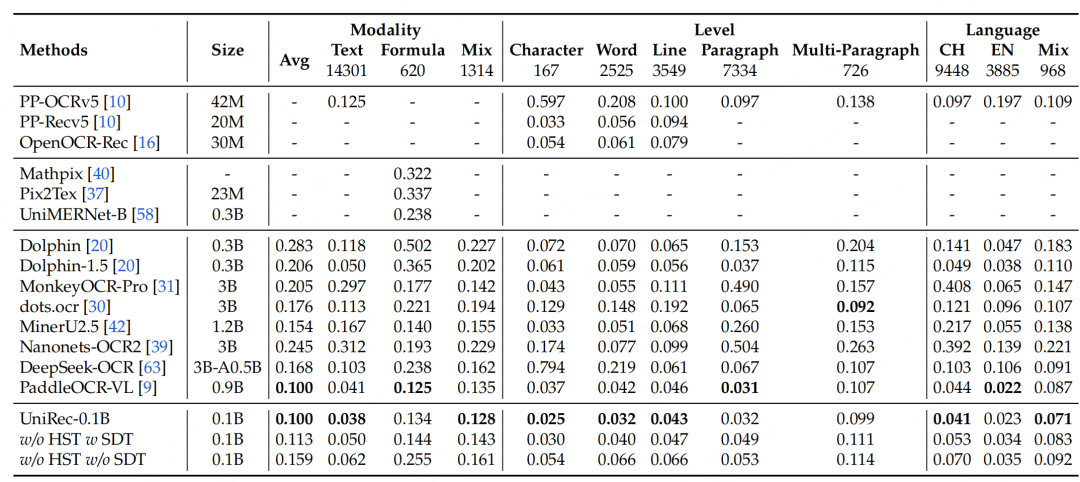
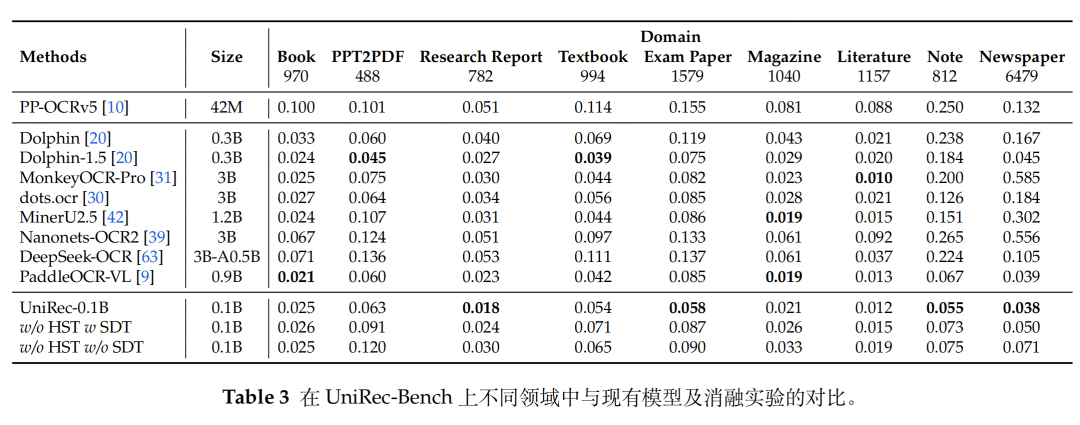
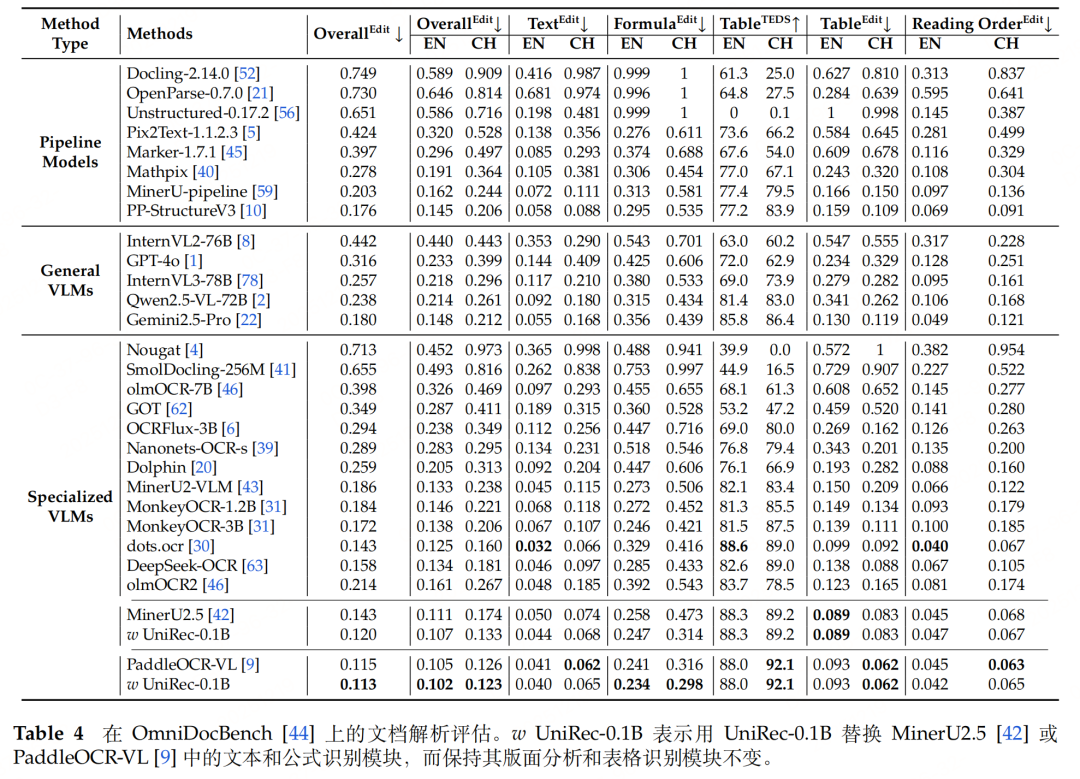
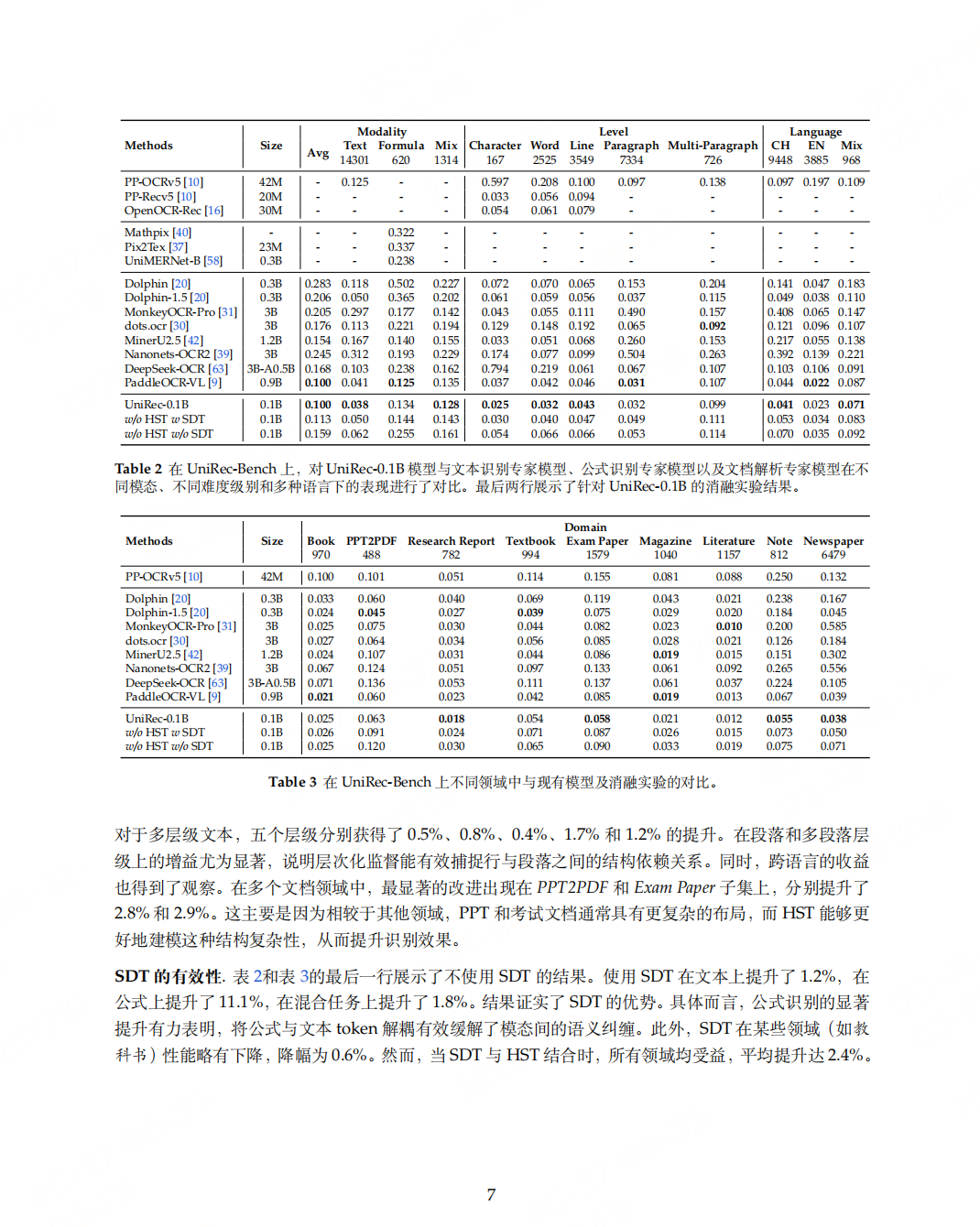
实际测试case
测试链接:https://modelscope.cn/studios/topdktu/OpenDoc-0.1B-Demo 笔者随便截取了tech report中的几页,效果如下(由于版式分析模型是使用的paddleocr的layout模型,测试主要关注下block的ocr format能力,测了两张不是特别好,就未压测):
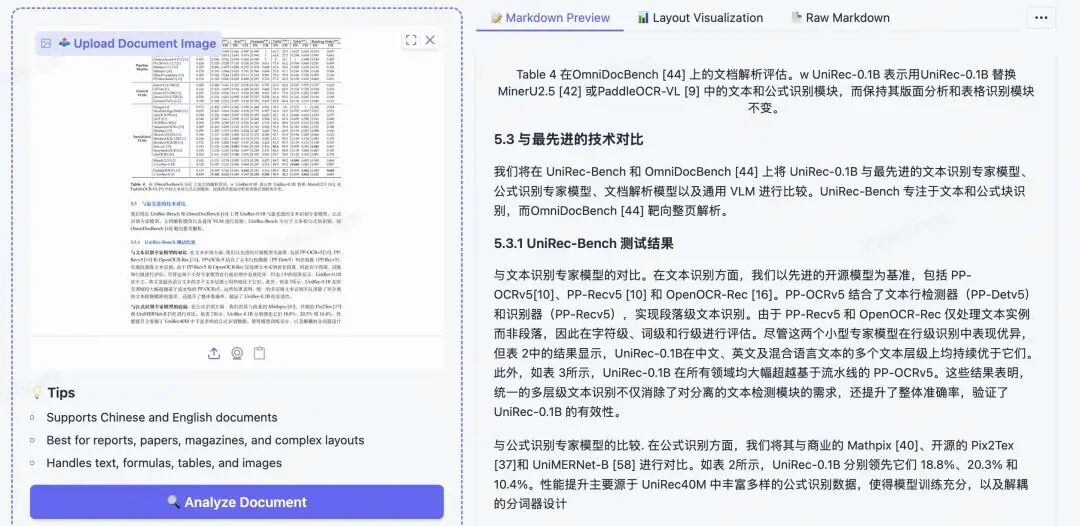
识别如下: