上一篇用纯代码手搓了一个RAG本地知识问答系统,使用过程中发现:
如果本地文档文档质量比较高的情况下,答案还是相当不错的
一旦知识库文件质量本身不好,或者知识库文件过多,相似的知识被分散在了不同的块,回答就会出现偏差。
那如何对输出的结果进行测试呢?一种方法是你本身对知识很熟悉,可以人工进行测评;还有一种方法就是,通过AI大模型,让其自己进行自动测评。
本篇将介绍使用ragas框架,自动对RAG系统的回答结果进行测评。
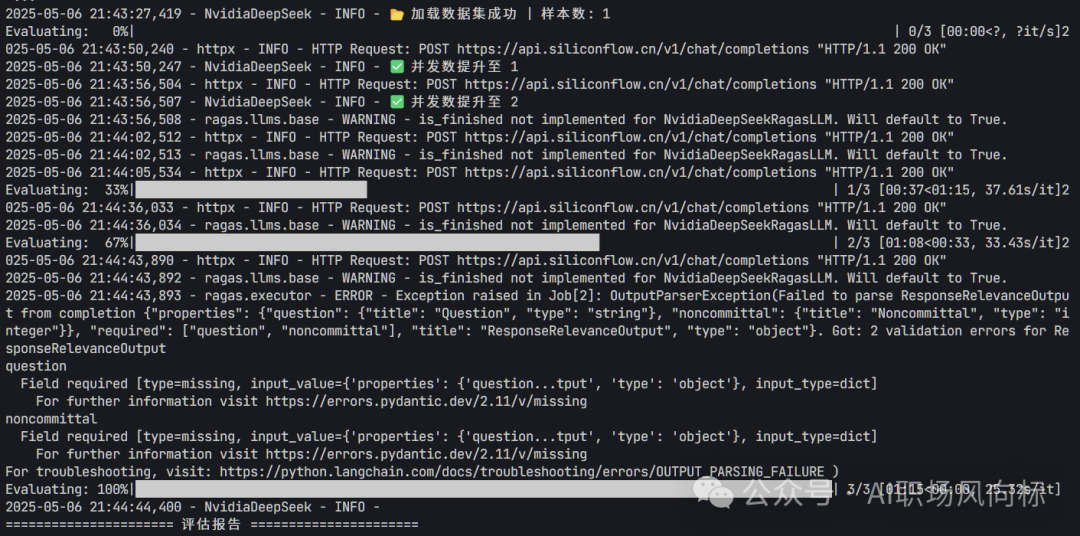
老规矩,先看最终效果。
挑选了上一篇文章中已经训练好的“信贷业务”这个知识库进行测评,测评的问题集可以自定义;
网上介绍ragas框架的文章有很多,就不在这里赘述,只介绍几个重要的概念,以便我们能实践使用。
ragas官方介绍文档(https://docs.ragas.io/en/stable/concepts/)
2. 检索阶段的指标包括:上下文相关性(Context Relevance)、上下文召回率(Context Recall);通俗点讲,就是要“找得准”。
3.生成环节的指标包括:忠实度(Faithfulness)、答案相关性(Answer Relevance);通俗点讲,就是要“不跑题”、“不瞎编”。
这一步也很重要,0.2+的版本和之前的版本,写法有很大的区别。要看清自己的版本。
1)测评数据内容:主要有用户问题、大模型生成的答案、检索上下文和真实答案(人工给出的答案,可以省略)。
2)测评数据获取:可以根据之前咱们手搓的程序重磅更新,开箱即用!RAG打造个人本地知识问答系统,职场人的外挂助手,对硬件无要求!后台的日志获取、前端的聊天框获取。也可以通过程序获取,建议保存到本地,可以重复使用。
eval_questions=[],可以设置多个问题;
answers = [],每个问题,大模型给出的答案,也就是问答界面给出的结果,通过rag返回的response.content获得。
contexts = [],这个是检索上下文,通过rag返回的response.source_nodes获得。
# ================== 数据集函数 ==================def prepare_eval_dataset(): """准备评估数据集(首次运行需取消注释)""" knowledge_base_id = "信贷业务" embedding_model_id = "huggingface_bge-large-zh-v1.5" eval_questions = ["信贷审批的特殊情形有哪些?"] answers, contexts = [], [] for q in eval_questions: try: query_engine = utils.load_vector_index( knowledge_base_id, embedding_model_id ).as_query_engine(llm=DeepSeek_llm) response = query_engine.query(q) answers.append(response.response.strip()) contexts.append([node.text for node in response.source_nodes]) except Exception as e: logger.error(f"生成答案失败: {str(e)}") answers.append("") contexts.append([]) eval_dataset = Dataset.from_dict({ "question": eval_questions, "answer": answers, "contexts": contexts }) eval_dataset.save_to_disk("eval_dataset") logger.info("? 评估数据集已保存")
ContextRelevance – 上下文相关性
LLMContextPrecisionWithoutReference – 用户不给出参考答案的情况下,评估内容精确度
metrics = [ ContextRelevance(llm=ragas_llm), Faithfulness(llm=ragas_llm), AnswerRelevancy(llm=ragas_llm)]
准备好上述一切之后,只需要调用ragas的evaluate方法即可。
# 加载数据集 try: eval_dataset = load_from_disk("eval_dataset") logger.info(f"? 加载数据集成功 | 样本数: {len(eval_dataset)}") except Exception as e: logger.error(f"数据集加载失败: {str(e)}") exit(1) # 执行评估 try: result = evaluate( eval_dataset, metrics=metrics, llm=ragas_llm, raise_exceptions=False #,timeout=300 ) except Exception as e: logger.critical(f"评估流程异常终止: {str(e)}") exit(1)
# 结果安全处理 logger.info("n" + " 评估报告 ".center(50, "=")) score_map = { 'context_relevance': 0.0, 'faithfulness': 0.0, 'answer_relevancy': 0.0 } for key in score_map.keys(): if key in result: score_map[key] = result[key].mean(skipna=True) logger.info(f"上下文相关性: {score_map['context_relevance']:.2%}") logger.info(f"回答忠实度: {score_map['faithfulness']:.2%}") logger.info(f"答案相关度: {score_map['answer_relevancy']:.2%}") logger.info("n详细结果:") print(result.to_pandas().to_markdown(index=False))
好了,今天ragas自动测评就到这里了,虽然简单、但很重要!就像任何一个系统投产之前需要进行测试一样重要!希望对你有用~