就是满怀期待的把资料“投喂”进知识库后,以为大模型能把所有资料完整“消化吸收”了。结果一测试发现问答效果不尽如人意。
咱们得先明白,RAG它不是银弹,不是全能的,它也有局限性,并不适合所有场景。
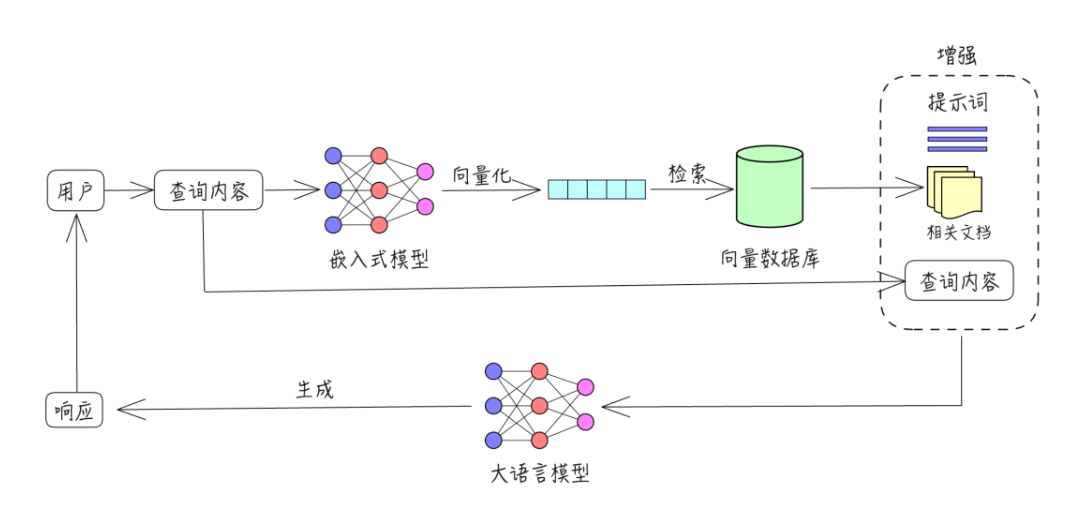
RAG的原理其实网上已经有非常多的资料了,这里就不详细赘述了。
1.文件分片:文件分片本身不是局限性,但是分片导致原本连贯的内容被分割,就会导致后期检索到的内容信息缺失。
2.检索不精确:因为RAG是使用向量比对的方式(数学的维度)来查询语义相近的内容,但是这也会导致有时候匹配的内容可能并不是我们想要的信息。
3.没有全局概念:由于知识库里面的文件都是分片存储,每次回答只会检索部分内容,所以,很难准确回答一些全局性的问题(或者说统计型的问题),比如知识库中的老师一共有多少位,一季度有多少个订单等等。
第一个问题(文件分片导致上下文丢失)其实在我之前的一篇文章里面已经给出了一个解决方案。
就是大力出奇迹:使用超长上下文的模型,把相关的不相关的内容出来都检索丢进去,给大模型自己判别,所以这个模型还必须有超强的"大海捞针"能力。感兴趣的朋友可以看看。
超长上下文开源模型minimax-01,支持400万tokens
dify%20v1.1.0%E6%8E%A5%E5%85%A5%E8%BF%99%E4%B8%AA%E5%BC%80%E6%BA%90LLM%EF%BC%8C%E7%9F%A5%E8%AF%86%E5%BA%93%E6%95%88%E6%9E%9C%E7%9B%B4%E6%8E%A5%E8%B5%B7%E9%A3%9E%EF%BC%8C%E7%9C%9F%E5%8F%AF%E4%BB%A5%E5%B0%81%E7%A5%9E%E4%BA%86%EF%BC%81%E3%80%90%E5%96%82%E9%A5%AD%E7%BA%A7%E6%95%99%E7%A8%8B%E3%80%91%22%2C%22url%22%3A%22https%3A%2F%2Fmp.weixin.qq.com%2Fs%2F7y6ep0UJkZLvcvaowrilog%22%2C%22nickname%22%3A%22%E8%A2%8B%E9%BC%A0%E5%B8%9DAI%E5%AE%A2%E6%A0%88%22%2C%22authorName%22%3A%22%E8%A2%8B%E9%BC%A0%E5%B8%9D%22%7D%7D">袋鼠帝,公众号:袋鼠帝AI客栈dify v1.1.0接入这个开源LLM,知识库效果直接起飞,真可以封神了!【喂饭级教程】
但是,那时候,我觉得这个方案还没有很成熟,而且操作起来较为繁琐,所以就一直没有分享。
直到最近MCP的大火,至少让AI大模型接入数据库的门槛又降低不少。
以及我平时最最喜欢用的字节旗下的AI IDE神器:Trae,终于终于支持MCP了!
它直接就内置了数据库的MCP-Server,这意味着我们可以通过MCP把数据库一键接入大模型。
本期将主要以PostgreSQL这个简单、轻量的关系型数据库为例,带大家接入(同时它应该也能满足大部分的使用场景了)。
声明,数据库方案更适合表格类型的数据,文本建议参考“大力出奇迹方案“
另外使用Trae的MCP能力,也需要先在本地安装Python环境、Node环境(这块网上资料很多),也可以问AI~
https://www.postgresql.org/download/
下载地址:https://dbeaver.io/download/
打开dbeaver,点击右上角的小+号,选中PostgreSQL添加
其他 默认配置即可,在下图,我们只需要填上安装PostgreSQL过程中的自己设置的密码,点击完成
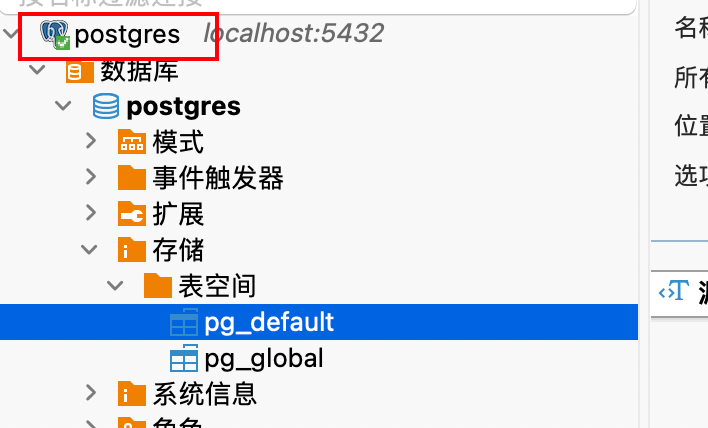
添加好本地的PostgreSQL之后,左边会出现一个小图标,双击一下连接数据库。
可能会要求安装连接数据库的相关驱动,跟着步骤安装即可
驱动安装成功之后,可以看到数据库大象图标那里有个小勾。
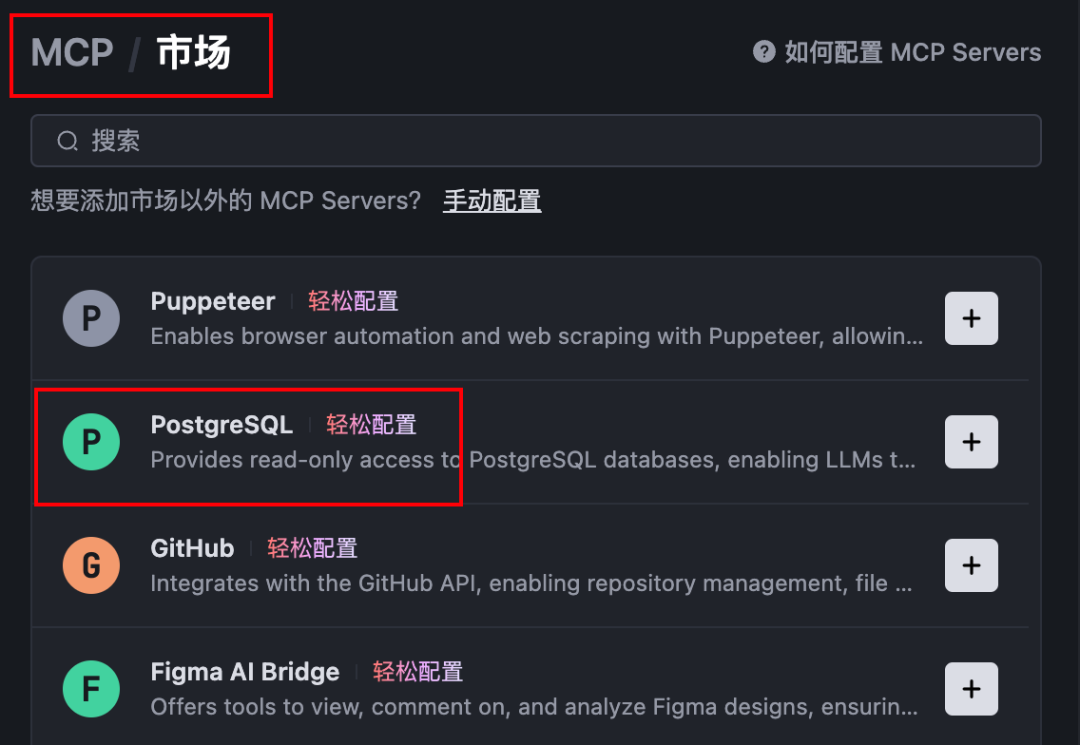
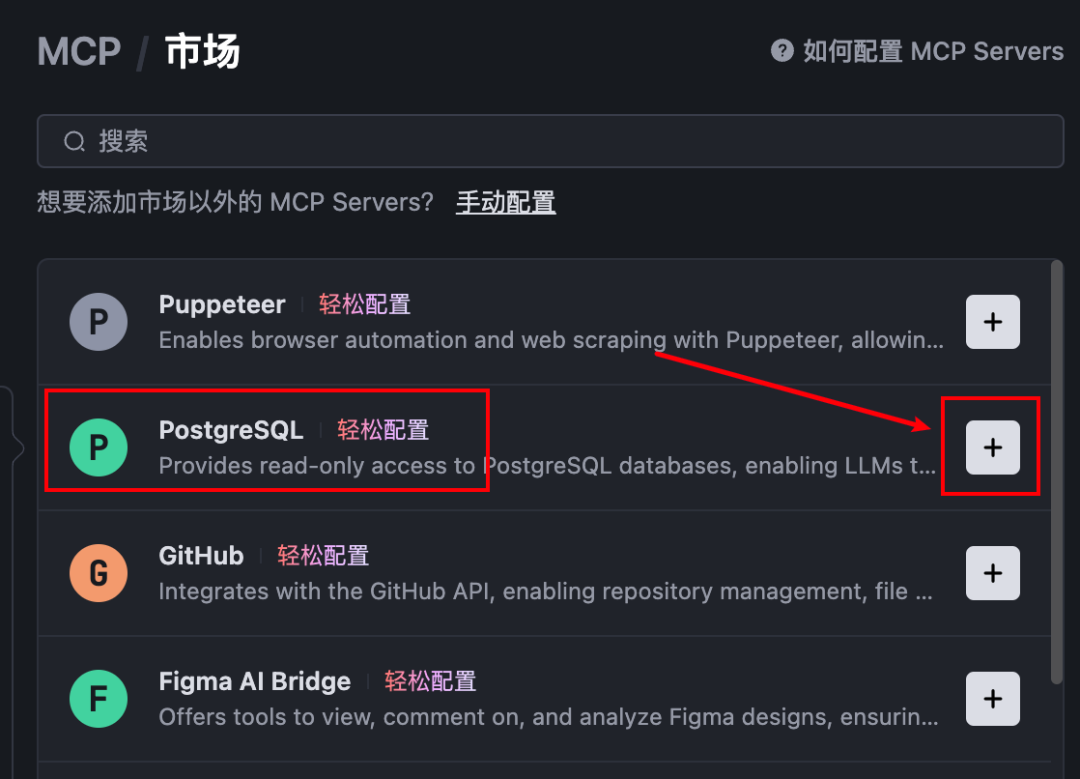
打开Trae,按照下图方式,如果第一次没有MCP,会提示需要添加MCP
接着就进入到MCP市场了,添加PostgreSQL
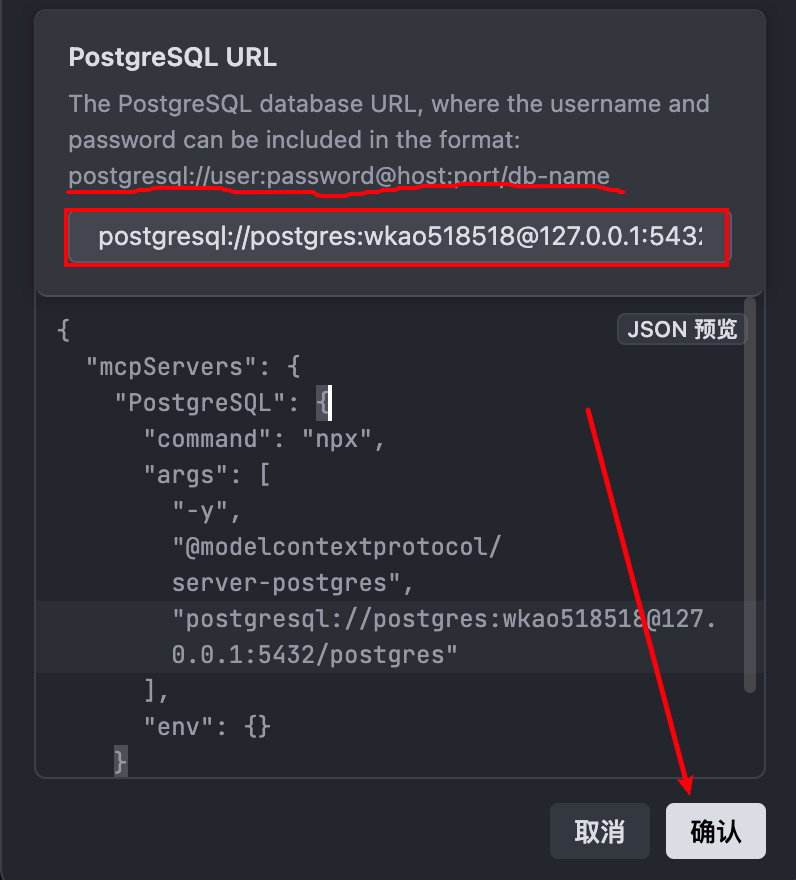
上面复制的PostgreSQL url不能直接粘贴使用,需要参考它给出的格式调整一下
postgresql://postgres:密码@127.0.0.1:5432/postgres
使用mac的朋友如果报这种错,说明相关路径没有权限
sudochown-R $(whoami) ~/.npm
PS:其他任何报错都可以丢给Trae,让AI帮你解决
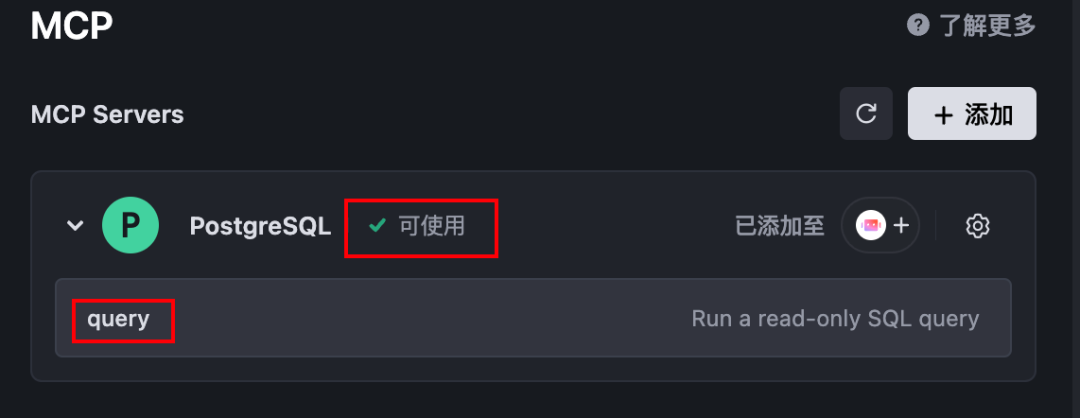
直到PostgreSQL MCP变为可使用状态,就代表配置好了
并且,为了安全,只提供了查询功能,无法进行增、删、改。
接下来我们需要把测试数据导入PostgreSQL中
是我之前在某宝爬取的一些内存条商品信息,一共135行
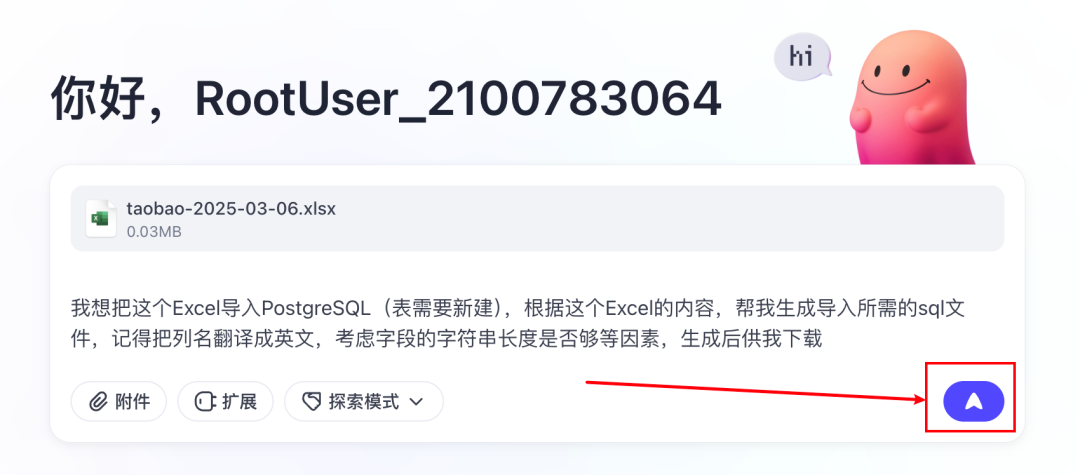
咱们直接用前两天刚刚发布的「扣子空间」,让它把这个表格转为可直接导入PostgreSQL的sql文件。
提示词:
我想把这个Excel导入PostgreSQL(表需要新建),根据这个Excel的内容,帮我生成导入所需的sql文件,记得把列名翻译成英文,考虑字段的字符串长度是否够等因素,生成后供我下载。
如果是在以前,估计得写代码,或者用Excel表达式吭哧吭哧搞半天
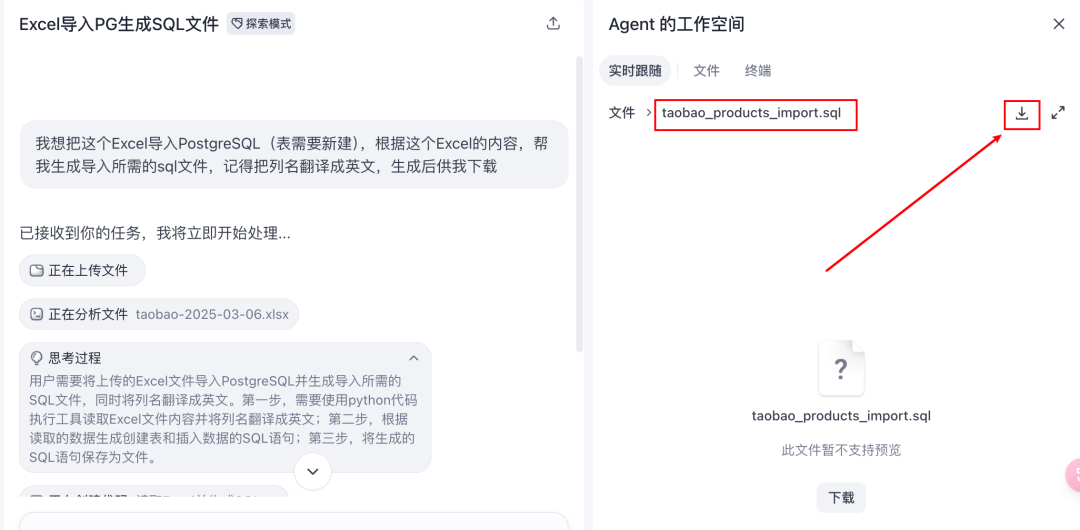
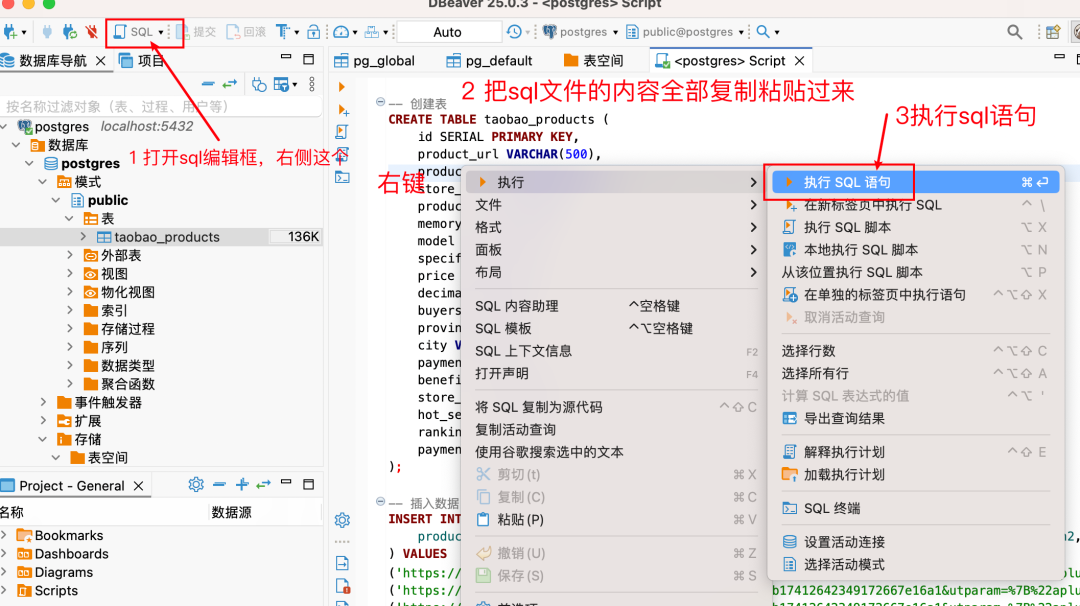
按照下图的步骤,把数据导入PostgreSQL数据库中
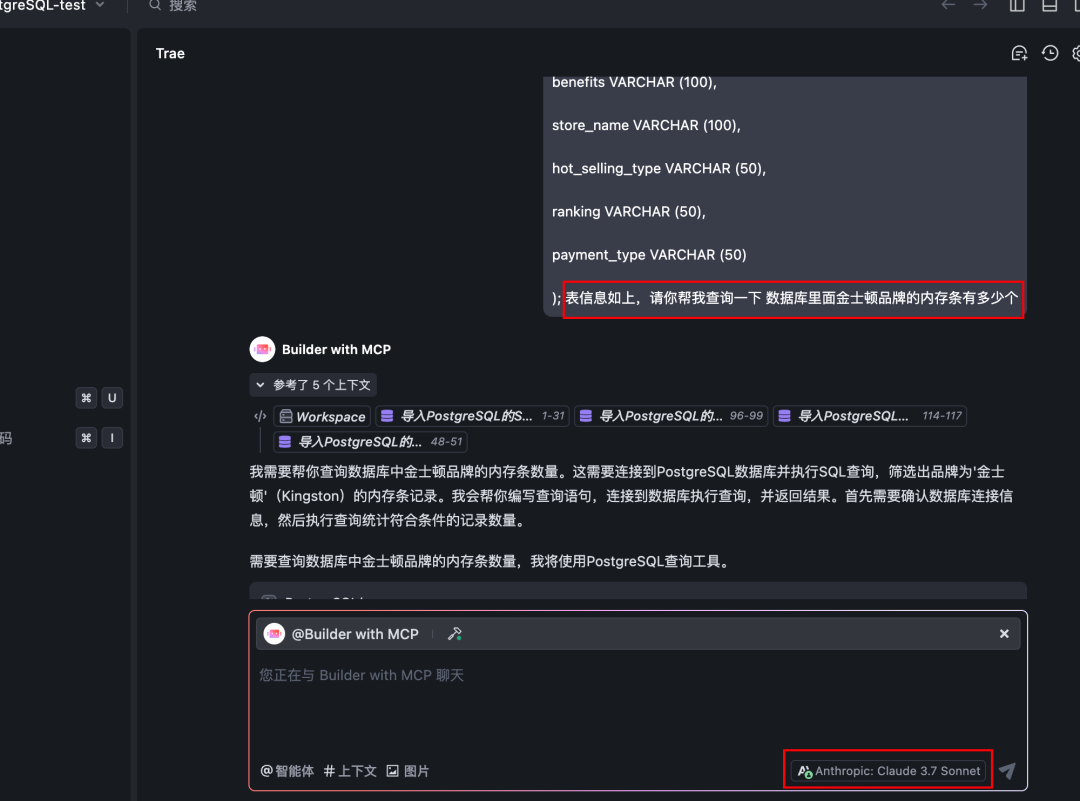
注意:由于大模型并不知道表格的结构和信息,我们需要把表格结构连同问题一起发过去(如果是智能体就可以把表格结构放到系统提示词中)
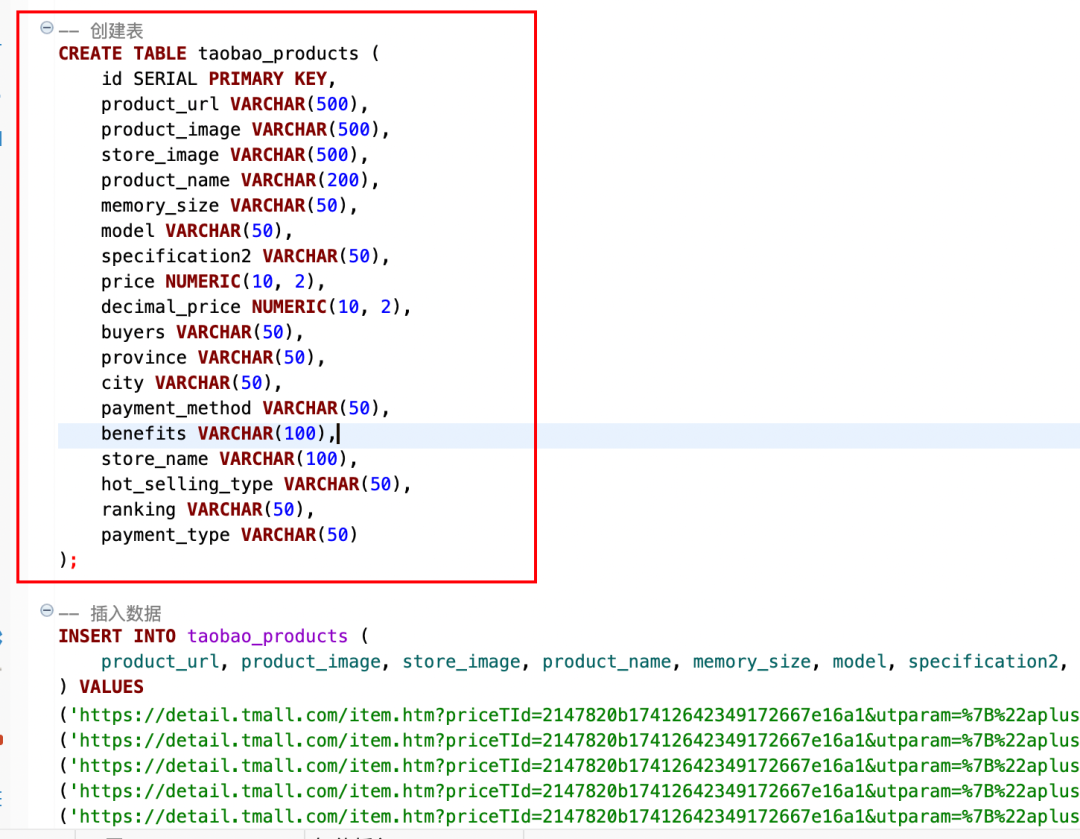
表格结构在之前生成的sql文件里面可以找到(如下图红框中这段)
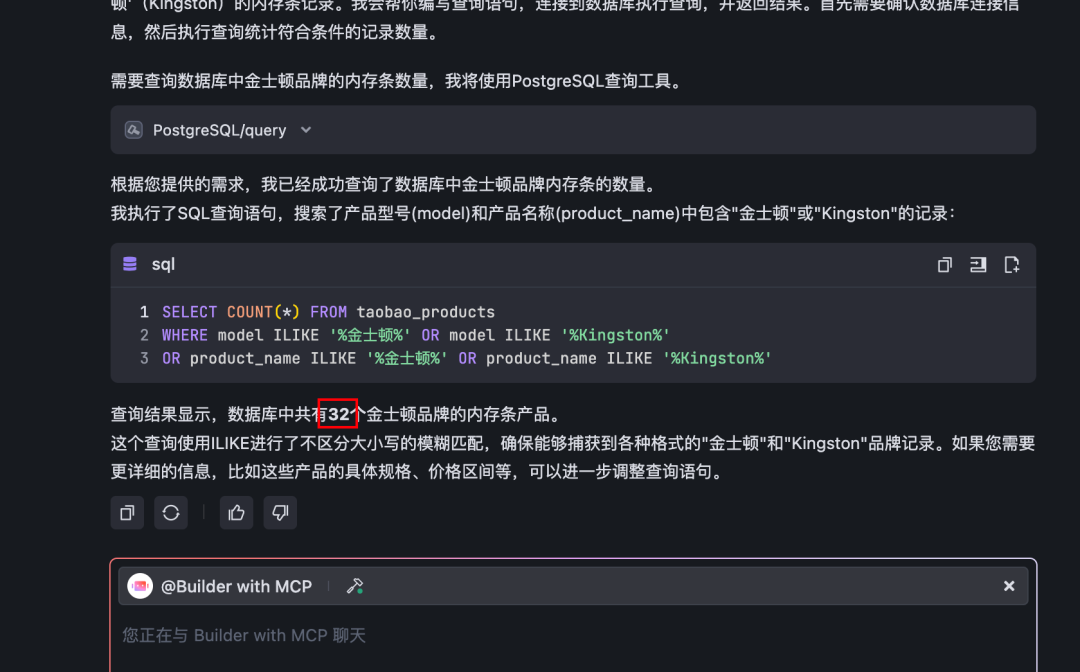
这个方案是由大模型写sql语句来进行查询,所以,查询精度是可以保证的。
亲测,Claude3.7还是比新版DeepSeek好用。。。至少sql语句写的更符合要求。
这个方案还可以结合RAG一起用:比如做一个工作流,搞一个大模型在最前面判断,用户问题如果是全局,或者统计性质的,就走数据库。否则就走RAG,这样结合起来,将会极大的提升整个知识库的检索精度。
写到这里,我不经想起当年刚做程序员的时候,有几个月每天都写各种复杂的sql,从生疏,到炉火纯青,现在看来好像没有多大用处了,因为AI完全可以秒出。
不经感叹,技术发展的真快,而我们,好像只能不断紧跟时代的步伐,才不至于被淘汰。