
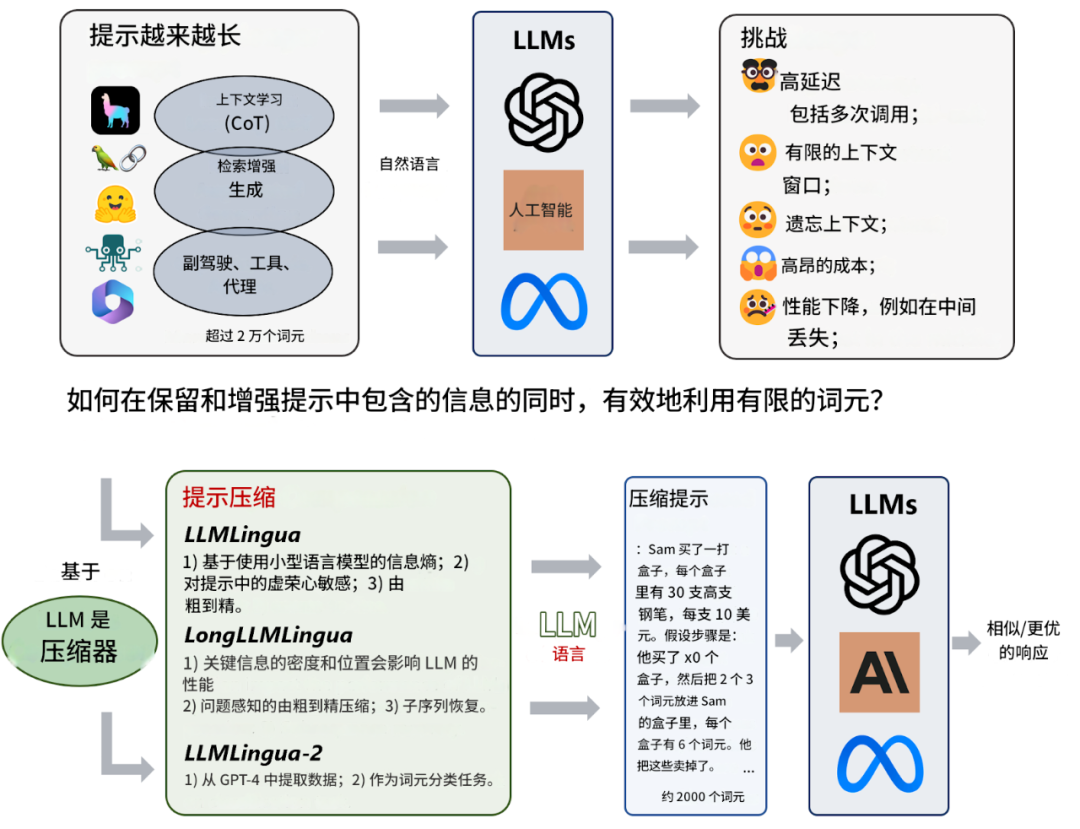
什么是 LLMLingua
-
从冗长的 prompt 中提取关键语义信息; -
去掉不重要或冗余内容; -
将压缩后的 prompt 输入到大模型(如 GPT-4)里; -
在多种任务中,实现 显著减少 tokens 数量、加速推理、保持准确性。

LLMLingua系列技术演进
-
使用小型语言模型(如LLaMA-7B)计算每个token的困惑度,困惑度低的token被认为是冗余的,可以删除 -
采用三步压缩策略:①预算控制器分配压缩比例 ②粗粒度筛选段落/示例 ③细粒度迭代删除token -
通过指令微调使压缩模型与目标大模型的语言分布对齐,确保压缩后的文本仍能被目标模型理解
-
问题感知压缩:根据用户问题动态调整压缩策略,与问题相关的部分保留更多内容 -
文档重排序:将重要信息移动到开头和结尾位置,避免被模型忽略 -
动态预算分配:不再均匀压缩,而是根据内容重要性动态分配压缩率 -
仍使用因果语言模型计算重要性,但加入了更智能的压缩策略
-
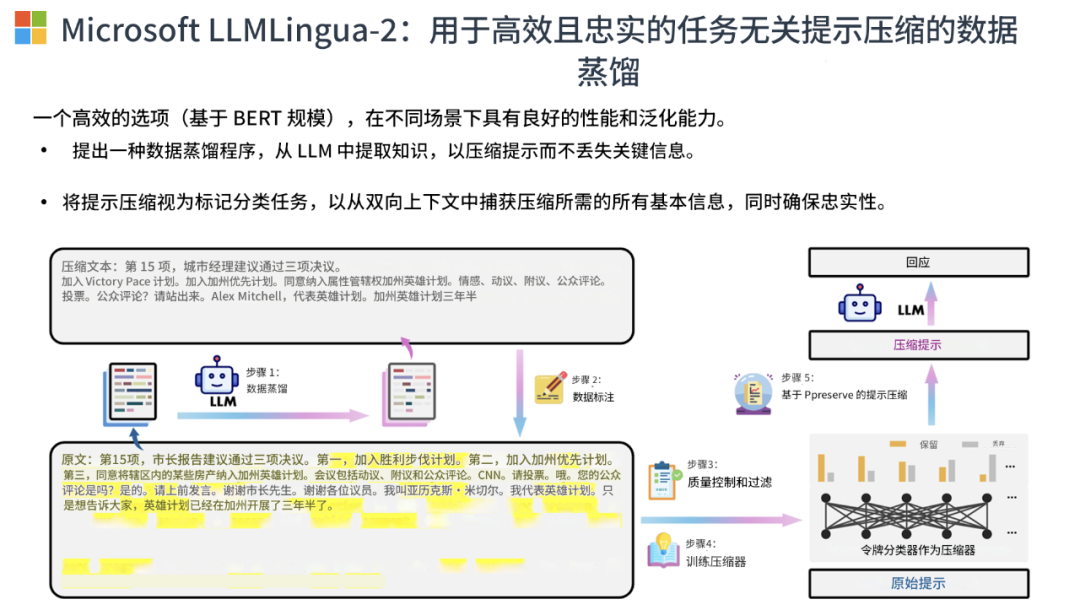
范式转变:不再用语言模型计算困惑度,而是训练一个专门的分类器来判断每个token是否应该保留 -
数据蒸馏:使用GPT-4压缩大量文本作为训练数据,让小模型学习GPT-4的压缩能力 -
双向理解:使用BERT类编码器(如XLM-RoBERTa)替代单向的因果语言模型,可以同时看到token的前后文信息 -
效率提升:模型参数量从7B降至340M(缩小20倍),压缩速度提升3-6倍,但压缩效果相当甚至更好 -
任务无关:一个模型可以处理各种不同类型的压缩任务,无需针对特定场景调优
-
核心洞察:越狱提示包含大量噪声token来混淆模型 -
压缩效果:通过压缩可以剥离这些噪声,暴露真实意图 -
双路输出: -
原始提示保持不变(用户体验一致) -
提取的意图通过系统提示传递给LLM
使用方法及效果
pip install llmlingua
from llmlingua import PromptCompressor# Initialize the compressorllm_lingua = PromptCompressor()# Compress the promptprompt = "Sam bought a dozen boxes, each with 30 highlighter pens inside, for $10 each box..."compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)print(compressed_prompt)
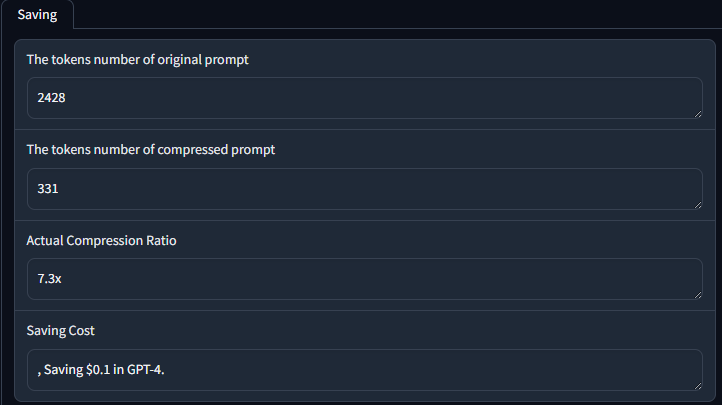
{ 'compressed_prompt': 'Question: Sam bought a dozen boxes each with 30 highlighter pens...', 'origin_tokens': 2365, 'compressed_tokens': 211, 'ratio': '11.2x', 'saving': 'Saving $0.1 in GPT-4.'}
# Use a more powerful compression modelllm_lingua = PromptCompressor("microsoft/phi-2")# Or use a quantized model for GPUs with limited memory# Requires: pip install optimum auto-gptqllm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
小结
END
