

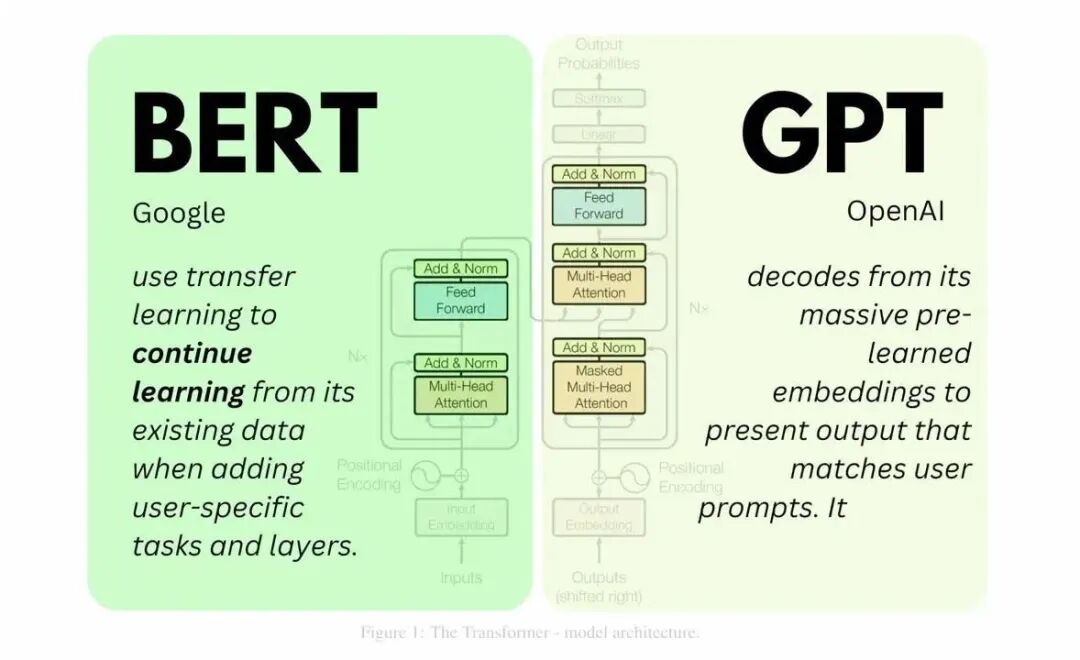
一、BERT(MLM + NSP)
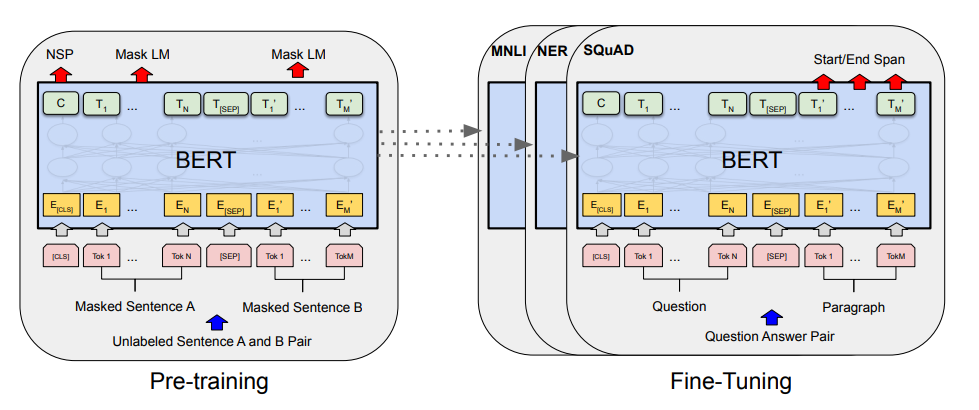
一、MLM(Masked Language Modeling)
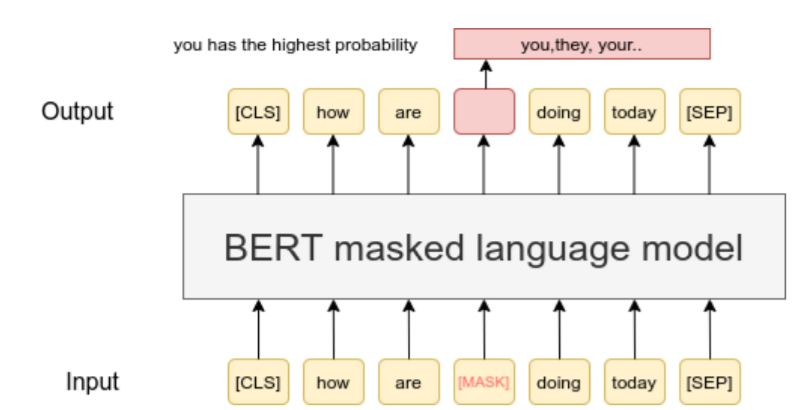
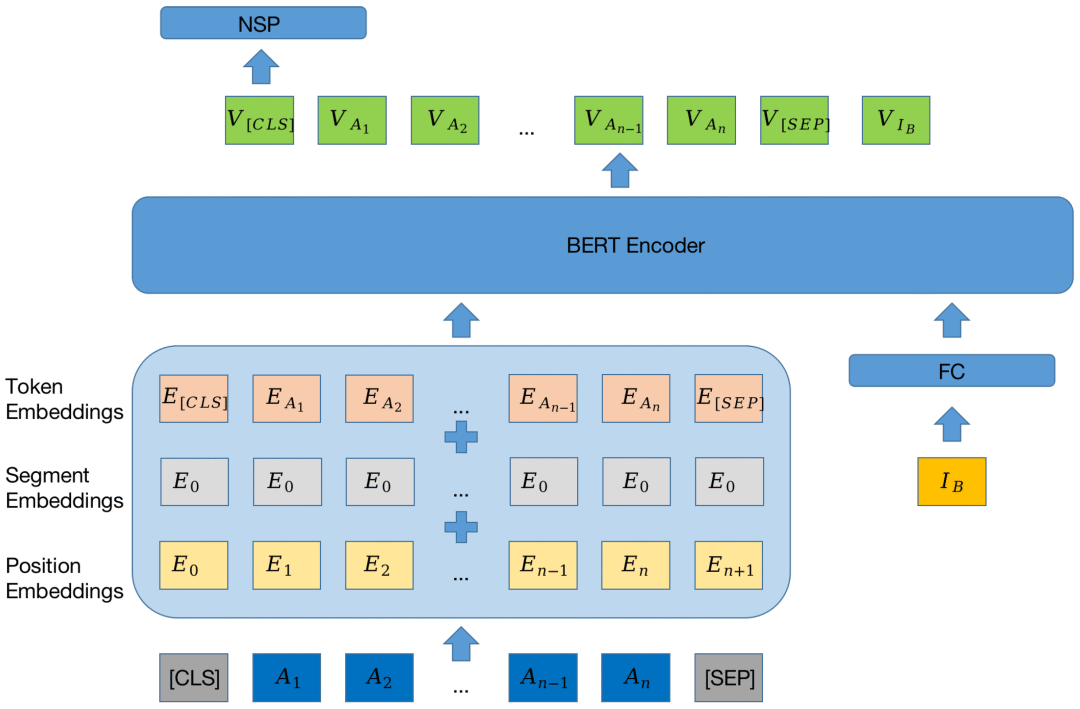
(1)目的:理解MLM和NSP的设计动机与核心逻辑。
from transformers import BertTokenizer, BertForMaskedLM, BertForNextSentencePrediction, Trainer, TrainingArgumentsimport torch# 加载预训练模型和tokenizertokenizer = BertTokenizer.from_pretrained("bert-base-uncased")model_mlm = BertForMaskedLM.from_pretrained("bert-base-uncased") # MLM专用model_nsp = BertForNextSentencePrediction.from_pretrained("bert-base-uncased") # NSP专用(旧版BERT支持)# 示例输入(MLM)text = "The cat sits on the [MASK]."inputs = tokenizer(text, return_tensors="pt")outputs = model_mlm(**inputs)predicted_token_id = torch.argmax(outputs.logits[0, -1]).item()print(tokenizer.decode(predicted_token_id)) # 输出预测的词(如"mat")# 示例输入(NSP)sentence1 = "I like cats."sentence2 = "They are cute."sentence3 = "The sky is blue."inputs_nsp = tokenizer(sentence1 + " [SEP] " + sentence2, return_tensors="pt") # 正例inputs_nsp_neg = tokenizer(sentence1 + " [SEP] " + sentence3, return_tensors="pt") # 负例model_nsp = BertForNextSentencePrediction.from_pretrained("bert-base-uncased") # 注意:新版本BERT已合并MLM+NSP
二、GPT(CLM)
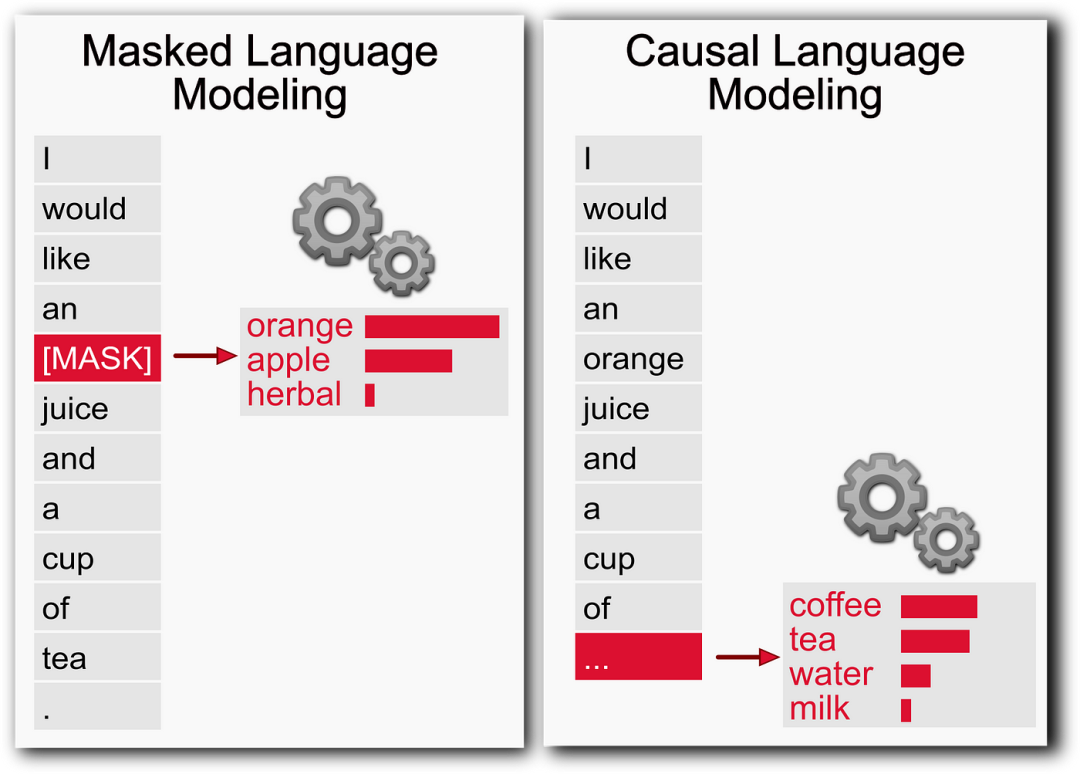
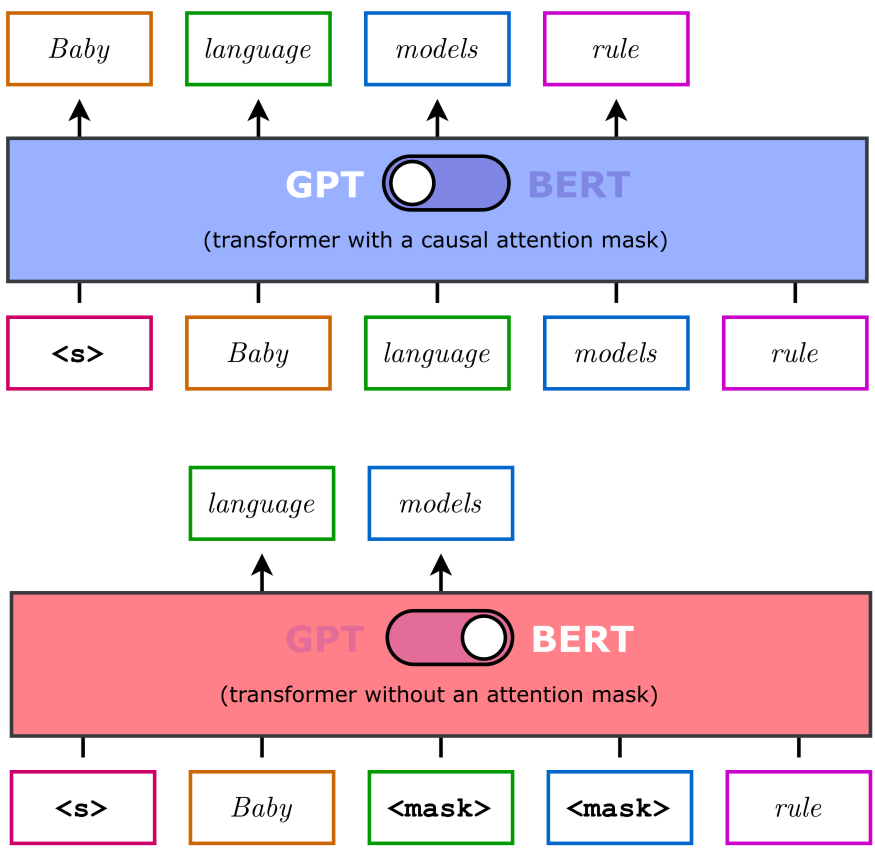
(1)目的:理解CLM的核心概念、数学原理及其与GPT的关系。
from transformers import GPT2LMHeadModel, GPT2Tokenizerimport torch# 加载预训练模型和tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")model = GPT2LMHeadModel.from_pretrained("gpt2")# 输入文本(CLM任务)input_text = "The cat sits on the"inputs = tokenizer(input_text, return_tensors="pt")# 生成下一个词outputs = model.generate(**inputs, max_length=20, num_return_sequences=1)print(tokenizer.decode(outputs[0])) # 输出完整句子(如"The cat sits on the mat and sleeps.")
