

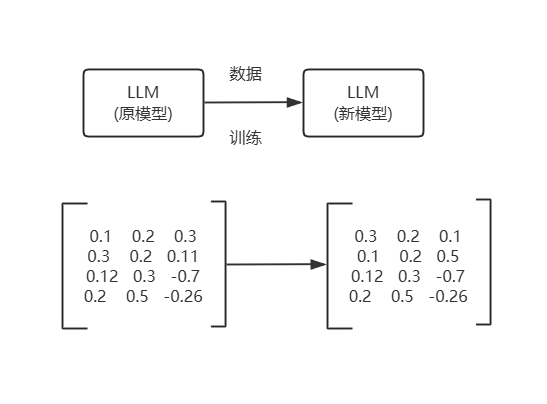
全量微调
- 定义:全量微调指的是在特定任务上,对预训练模型的所有参数进行更新。
-
特点: - 灵活性高:模型能够针对新任务进行全方位调整,通常能获得更好的性能。
- 计算资源要求高:因为涉及到整个模型参数的更新,所以需要更多的内存和计算资源。
- 风险:如果数据量较少或任务与预训练任务差异较大,可能导致过拟合或遗忘预训练知识。
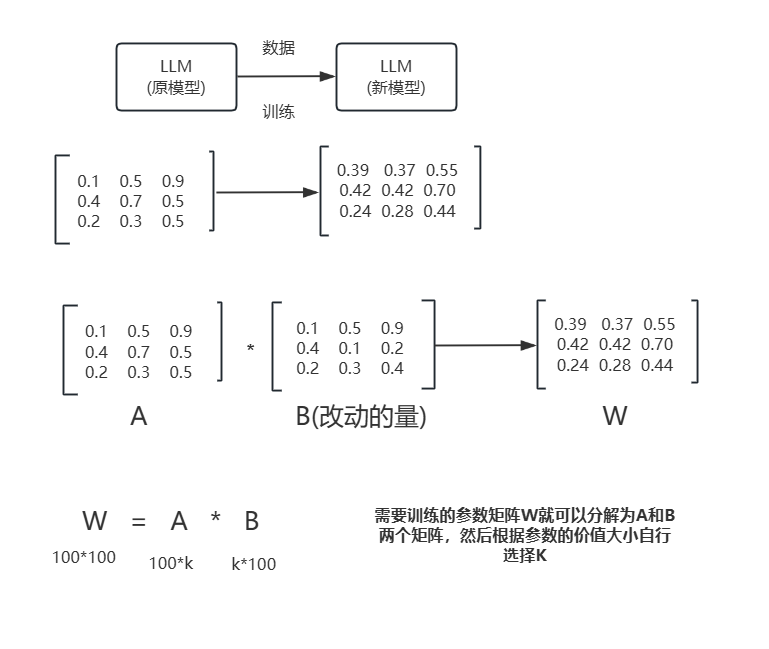
LoRA微调(Low-Rank Adaptation 微调)
- 定义:LoRA微调是一种参数高效的微调方法,它通过在模型中的权重矩阵上添加低秩分解的可训练模块来实现任务适配,而保持原有预训练参数不变或很少改变。
-
特点: - 参数量较少:只需训练附加的低秩矩阵,极大降低了微调时需要更新的参数量。
- 计算资源要求低:由于更新的参数量大大减少,对内存和计算资源的需求也相对较低。
- 保留预训练知识:保持原有模型权重不变,有助于防止在小样本任务中发生灾难性遗忘。
总结
- 全量微调
适合于有充足计算资源且数据充足的场景,可以通过对整个模型进行细致调整来获得最佳性能。 - LoRA微调
则更适合资源受限或者数据量较小的情况,通过只更新少量的低秩参数,既能有效适应新任务,又能大大降低计算和存储成本。
这两种方法各有优缺点,选择哪种方法取决于具体任务需求、数据量和可用计算资源、成本等因素。现实当中对于大模型的微调,大多数的企业都是采用Lora微调为主,毕竟大多数企业都没有办法承担得起这么昂贵的算力成本,通常只有建大模型基座的公司才有这么强大的算力资源。
