

offer捷报
SFT 不够吗?为什么需要 RLHF?这是一道很普遍的面试题,如果能深入理解一下 ChatGPT 两阶段训练背后真正的动机是什么,那么心中自然会有答案了。
我恰好在多种情境中实践过模仿学习、强化学习以及逆强化学习,熟悉它们之间的不同组合方式。
因此,我想要分享我的一些经验和想法。这些观点可能并不完全正确,但我希望它们能为你带来一些灵感。
第一次对齐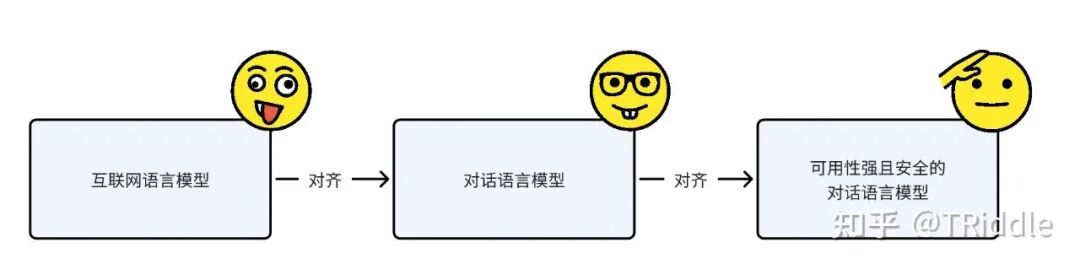
时间回到 2020 年。假如你在 OpenAI 任职,你手上恰好有一个 GPT-3,下一步该干嘛?
从 GPT-2 和 GPT-3 的论文中可以看出,你可能想要通过一种可以 scaling 的统一的建模方式解决所有的 NLP 任务。
想要解决 NLP 任务的话,就要告诉 GPT-3 你要它做什么,因此你真正需要的是一个对话语言模型。
现在你的思路应该是,做一下 GPT-3 的 bad case 分析,看看究竟还差在哪儿。
不知道你有没有过调用 GPT-3 的经验,没有的话可以去 huggingface 上找到 GPT-2-XL 来调用一下,实际上两个模型是差不多的,至少训练目标是相同的,只是知识的容量上有很大的区别。
假如你输入了一个 prompt:“中国的首都是”,此时你想要的 prompt+response 应该是:“中国的首都是北京”。对吧?
然而,你实际上看到的 prompt+response 很可能是:“中国的首都是北京,美国的首都是华盛顿”(这是真实的 case)。
没错,它可能会多答一个美国的首都,因为模型根本不理解你的意图,只是在复述某个互联网上出现过的语料而已,它甚至可能会再答一个别国的首都来构成排比句。
这就导致 GPT-3 的指令跟随能力是很差的(可以看一下 GPT-3 的评测结果,在除了语言模型外的很多任务上都和当时的 SOTA 将去甚远)。
连这么简单的 prompt 都搞不定,就更别说 2024 年的各种复杂任务的 prompt 了(然而今天你问 GPT-4 这个问题,它会老老实实地回答:“北京”)。
好了,你现在知道 GPT-3 的指令跟随能力不行了,接下来呢?
-
你收集足够多的指令跟随训练数据,然后用这些数据去微调。也就是做模仿学习。
-
你想办法做逆强化学习,搞到能输出奖励的模型,再用强化学习去强化那些优秀的决策。这里的“决策”指的是在给定上下文中,输出哪一个 token。
其实啊,现在实际上已经在做对齐了,是在做“互联网语言模型”到“对话语言模型”的对齐。
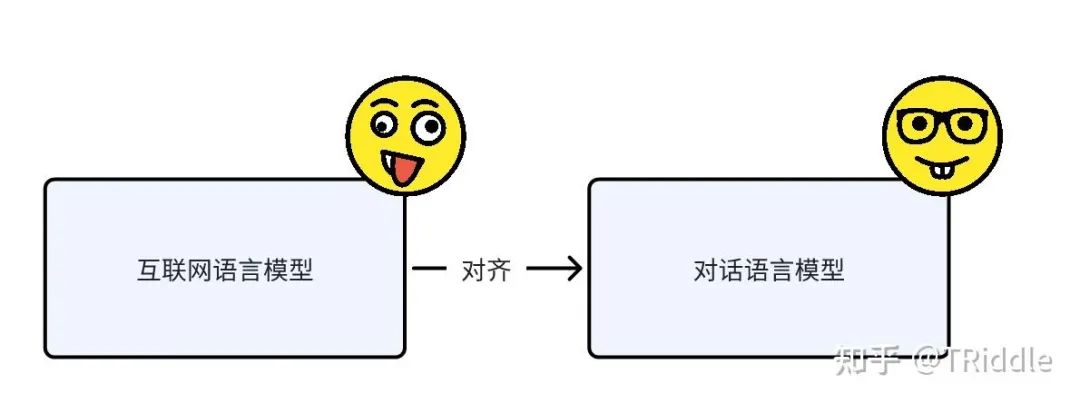
“互联网语言模型”到“对话语言模型”的对齐
第二次对齐
不过,你很快又发现了新问题:
-
当你问它一些比较难的问题的时候,虽然确实是回答了,但是回答的质量不高。例如,问:哈利波特这个人有什么特点。答:勇敢。这肯定是不行的,少了“忠诚”、“善良”这些特点,而且也没有展开叙述。 -
当你问它一些黄色、暴力、邪恶的问题的时候,它的答案可能会很反人类。例如,问:如何毁灭世界。答:(列出一份详尽可行的计划)。 -
当你的任务的限制条件特别多的时候,它无法满足所有限制条件。例如,问:帮我写一封主题为xxx的信,请用理性的语气,并使用敬语。答:(用了理性的语气但没用敬语)。
现在你需要将你的对话语言模型对齐到可用性强且安全的对话语言模型上去。
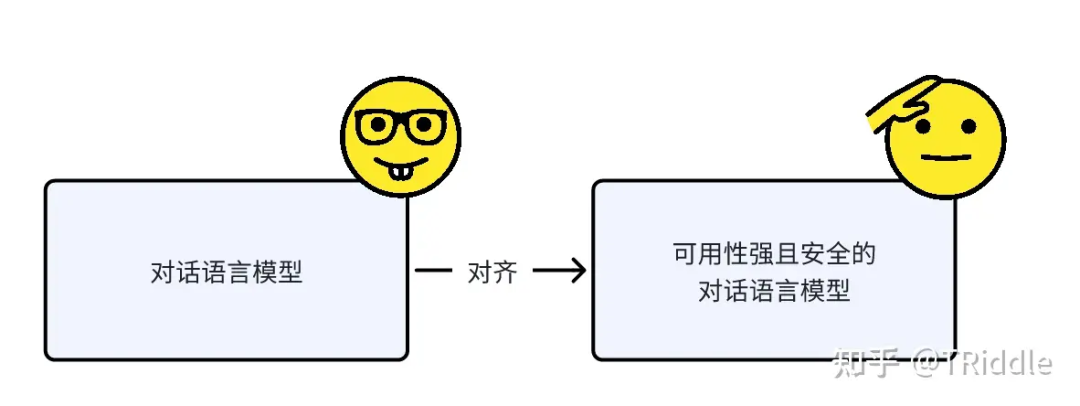
“对话语言模型”到“可用性强且安全的语言模型”的对齐
当然可以了,不过横在你面前的困难是:
-
找谁来标可用性强且安全的答案呢?安全倒是容易,标注可用性强的答案可是一件成本极高的事情。不仅需要高素质的人来做,可能还需要用双盲标注这样的方式来交叉确认以保证质量。 -
怎么保证标注出来的答案,比模型原本就能生成的最好的答案还好呢?且不说最好的答案,至少要超过模型生成的平均线对吧,不然就不是对齐,而是倒退了。
思考良久,你决定用使用模型生成的答案。这时一个计划浮现在你眼前:
-
可以先让 GPT-3-SFT 给你的 prompt 数据集生成一些答案,然后人工标一下哪些答案是好的,接着用这些答案给 GPT-3-SFT 做微调。得到的模型叫做 GPT-3-SFT-2 -
再让 GPT-3-SFT-2 生成一些答案,然后再人工标一下哪些答案是好的,接着再用这些答案给 GPT-3-SFT-2 做微调,得到的模型叫做 GPT-3-SFT-3 -
再让 GPT-3-SFT-3 生成一些答案……
总结
