

OpenAI 终于推出Prompt Caching 给开发者省钱了。
OpenAI最新推出的Prompt Caching功能,一下子就让API调用成本腰斩,速度翻倍。这下,AI应用开发者们该笑醒了。
让我们来看看这个新功能:
成本砍半,速度飙升
-
成本直接减半:长提示词的API调用成本降低了50% -
速度提升惊人:延迟降低了80%
这意味着什么?
简单来说,开发者可以用更少的钱,做更多的事。
适用范围广,自动生效
这可不是什么小打小闹的实验性功能。OpenAI直接把它应用到了主力模型上:
-
GPT-4o -
GPT-4o mini -
o1-preview -
o1-mini
最爽的是,这个功能是自动应用的。开发者们不需要修改一行代码,就能享受到这个福利。
缓存机制详解
-
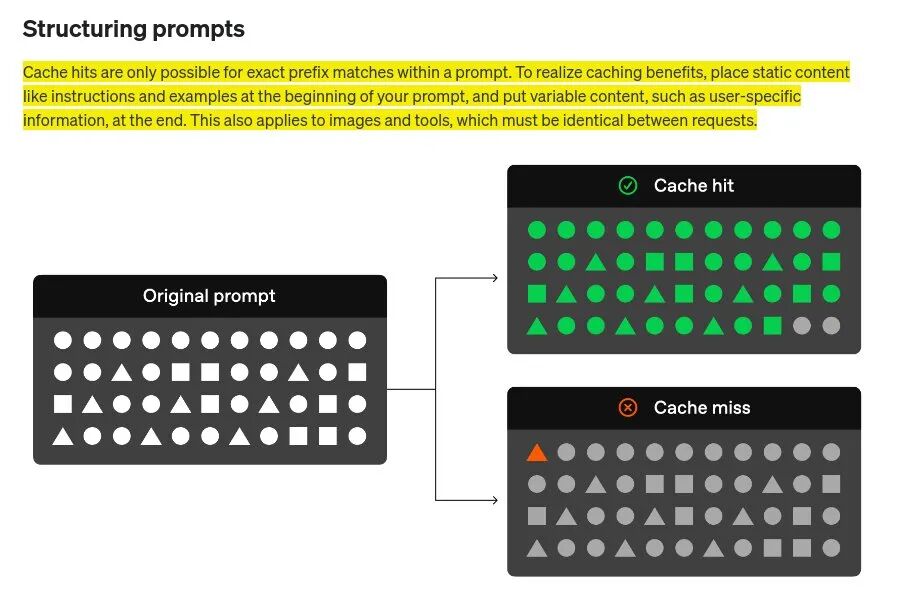
缓存触发条件:提示词超过1,024个token -
缓存增量:以128个token为单位递增 -
缓存匹配:需要完全匹配前缀才能命中缓存 -
缓存保留时间:5-10分钟无活动后清除,最长保留1小时 -
监控方式:通过API响应中的'cached_tokens'字段查看
开发者优化建议
-
将静态内容放在提示词开头,这样更容易命中缓存 -
缓存的输入token价格是未缓存token的一半 -
无需任何代码修改,系统会自动应用缓存
@bidhanxyz( @bagel_network 的创始人)甚至预测:
有人会在API上实现模糊缓存,将成本再降低50%。
这话说的,OpenAI的工程师们怕是要加班了。
@ShenHuang_(Google Travel Ads的技术主管)也表示:
这可以节省我大量的API调用成本?
看来,不只是小开发者,连大公司都对这个功能垂涎三尺啊。
AI开发的春天来了?
这个功能早有呼声,@AI_GPT42说到:
我一直在等这个功能?
OpenAI这一次,终于回应了开发者的需求。可以说是跟上了其他厂商(如deepseed, claude等),为AI应用开发铺平了道路。
成本降低,速度提升,用同样的钱能干更多的事,这也意味着更多的创新可能性。
