

来自多所大学的研究人员提出了一种新的训练方法——发散式思维链(Divergent Chain of Thought, DCoT),让AI模型在单次推理中生成多条思维链,从而显著提升了推理能力。
这项研究不仅让AI模型的表现更上一层楼,更重要的是,它让AI具备了自我纠错的能力。
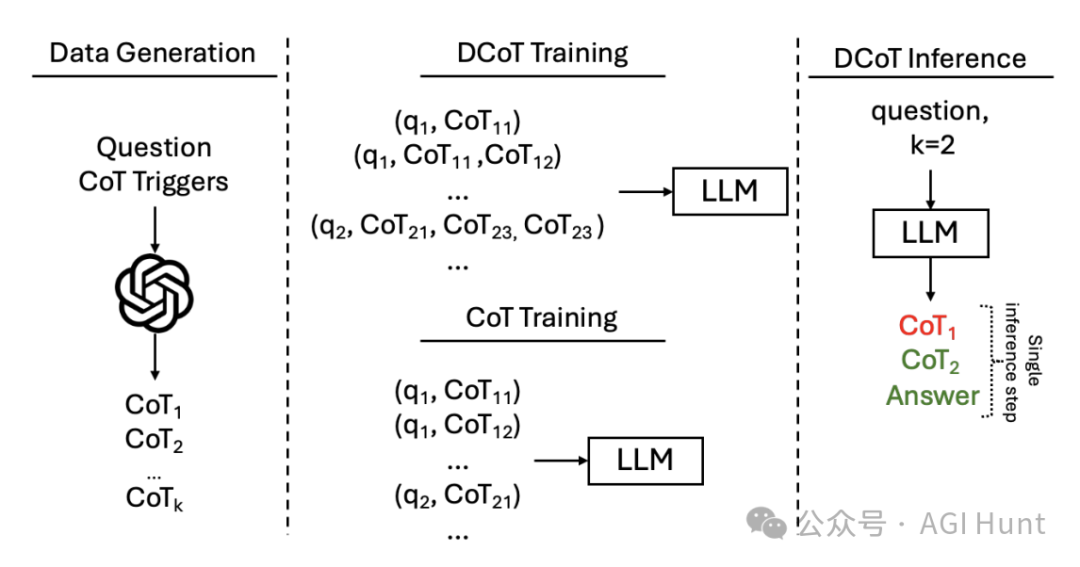
DCoT:一石三鸟的训练方法
-
提升小型模型性能:即使是规模较小、更易获取的语言模型,经过DCoT训练后也能显著提升表现。 -
全面超越CoT基线:从1.3B到70B参数的各种规模模型中,DCoT都展现出了优于传统思维链(Chain of Thought, CoT)的性能。 -
激发自我纠错能力:经过DCoT训练的模型能够在单次推理中生成多条思维链,并从中选择最佳答案,实现了自我纠错。
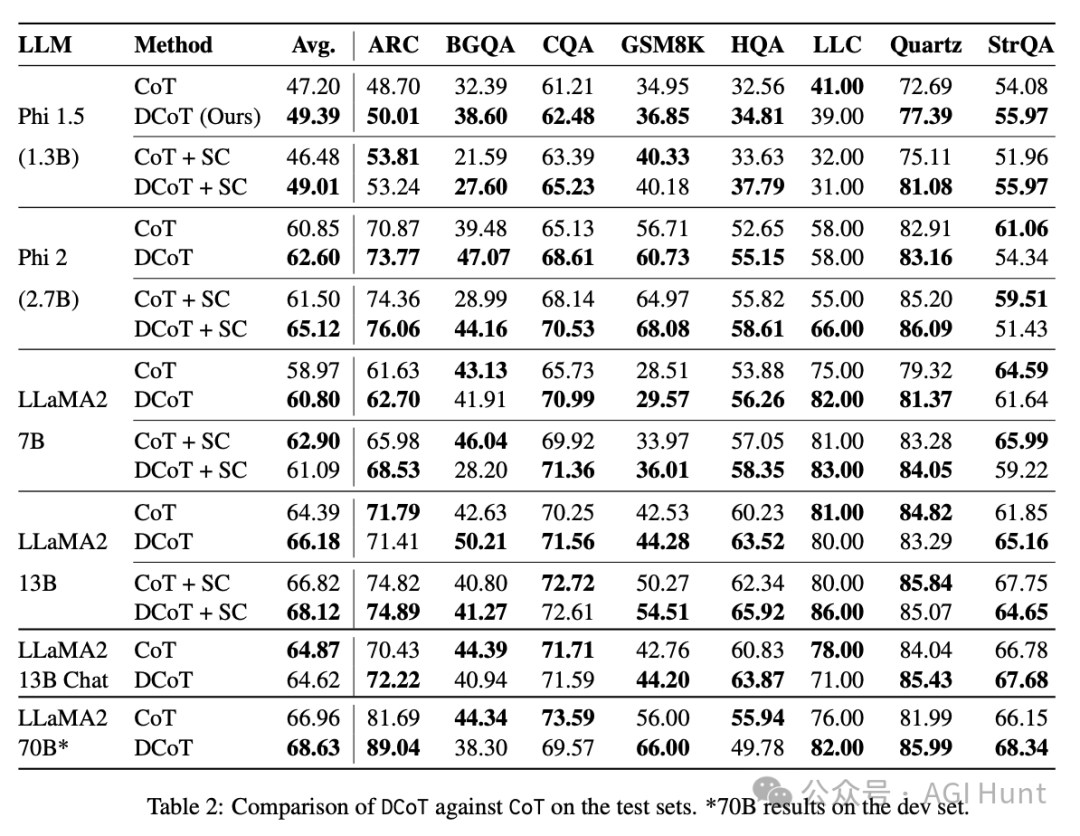
实验结果:DCoT的全面胜利
-
一致性提升:DCoT在各种模型家族和规模上都取得了持续的性能提升。 -
多样化思维链:通过实证和人工评估,确认模型能生成多条不同的推理链。
这意味着,DCoT不仅提高了模型的推理能力,还让模型具备了"多角度思考"的能力。
DCoT vs 传统CoT:谁更胜一筹?
-
领域内任务:DCoT在训练涉及的任务上表现优异。 -
未见过的任务:在全新的任务上,DCoT仍然保持优势。 -
困难任务:即使在CoT可能有害的任务上,DCoT也展现出了稳健性。 -
兼容性:DCoT还能与现有的CoT扩展方法(如自洽性解码)兼容,进一步提升性能。
自我纠错:AI的新技能
-
无需外部反馈:模型能够在单次推理中生成多条思维链,并从中选择最佳答案。 -
显著提升:仅生成两条思维链就能带来明显的性能提升,证实了自我纠错的存在。 -
人工验证:通过人工分析,确认了模型确实在进行自我纠错,而非简单的自我集成。
提示词工程的终结?
DCoT的成功引发了一个有趣的问题:
随着AI模型变得越来越智能,我们是否还需要那么多"技巧"来与之沟通?
虽然现在断言提示词工程已经走到尽头为时尚早,但DCoT的出现无疑为AI与人类的交互开辟了新的可能性。
未来,我们可能需要重新学习如何与这些"高智商"模型对话。
