

有很多个TXT文档,里面有很多换行,要全部去掉:
在deepseek中输入提示词:
写一个Python脚本,完成任务如下:
读取文件:"F:OneDrive桌面新建 文本文档 (3).txt"
识别所有的换行符,
如果换行符前面是文字,那么就删掉这个换行符;
如果换行符前面是句号、问号、感叹号等标点符号,那么就保留这个换行符。
注意:每一步都要输出信息到屏幕上
文件中包含了一些无法被UTF-8编码解析的字符。为了处理这种情况,我们可以尝试使用不同的编码方式来读取文件,例如 'gbk' 或 'latin1'。如果这些编码方式仍然无法解析文件内容,我们可以尝试忽略无法解析的字符
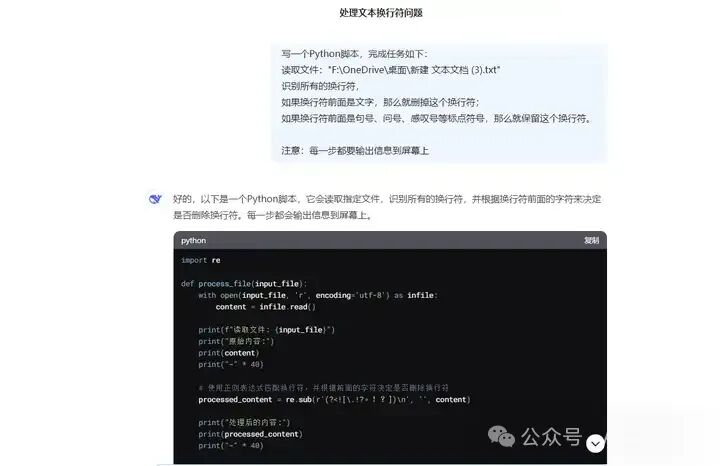
Deepseek生成的源代码:
import re
def process_file(input_file):
try:
with open(input_file, 'r', encoding='utf-8') as infile:
content = infile.read()
except UnicodeDecodeError:
try:
with open(input_file, 'r', encoding='gbk') as infile:
content = infile.read()
except UnicodeDecodeError:
with open(input_file, 'r', encoding='latin1') as infile:
content = infile.read()
print(f"读取文件: {input_file}")
print("原始内容:")
print(content)
print("-" * 40)
# 使用正则表达式匹配换行符,并根据前面的字符决定是否删除换行符
processed_content = re.sub(r'(?<![.!?。!?])n', '', content)
print("处理后的内容:")
print(processed_content)
print("-" * 40)
# 将处理后的内容写回文件
with open(input_file, 'w', encoding='utf-8') as outfile:
outfile.write(processed_content)
print(f"处理后的内容已写回文件: {input_file}")
# 示例用法
input_file = r"F:OneDrive桌面新建 文本文档 (3).txt" # 输入文件路径
process_file(input_file)
代码解释:
try…except 块: 尝试使用 utf-8 编码读取文件,如果失败则尝试使用 gbk 编码,如果仍然失败则尝试使用 latin1 编码。
re.sub(r'(?<![.!?。!?])n', '', content): 这个正则表达式会匹配换行符,并检查换行符前面是否不是句号、问号、感叹号等标点符号。如果是,则删除换行符;如果不是,则保留换行符。
with open(input_file, 'w', encoding='utf-8') as outfile:: 将处理后的内容写回文件,使用 utf-8 编码。
使用方法:
将你的文本内容保存到 F:OneDrive桌面新建 文本文档 (3).txt 文件中。
运行上述代码,脚本会读取文件内容,处理换行符,并将处理后的内容写回文件。每一步都会输出信息到屏幕上。
注意事项:
如果文件中包含无法解析的字符,脚本会尝试使用不同的编码方式来读取文件。如果所有编码方式都无法解析文件内容,可能需要手动检查文件内容并修复编码问题。

运行程序,txt文档处理好了:

