

一、Text Embedding Models(文本嵌入模型)
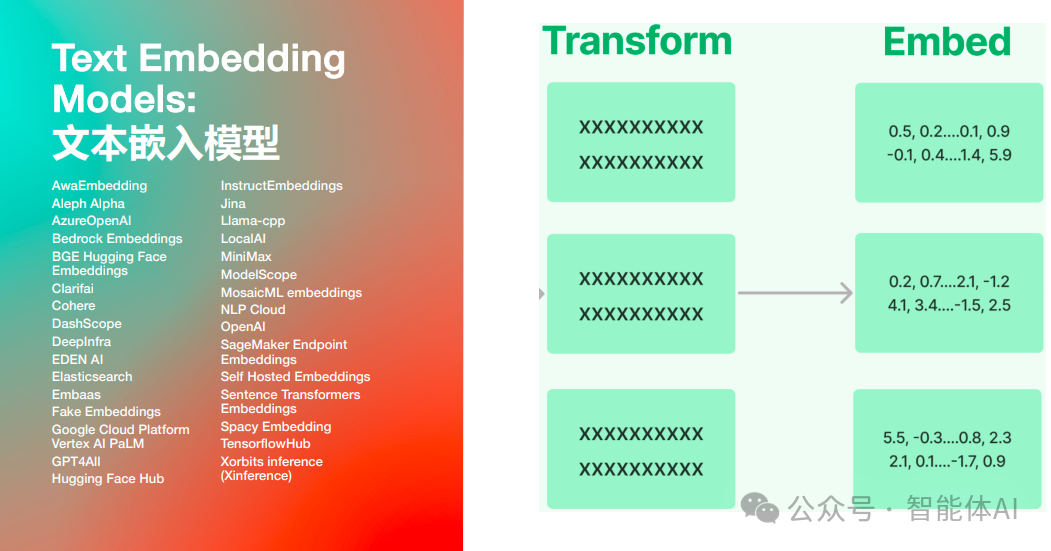
1. 使用 OpenAIEmbeddings 调用 OpenAI 嵌入模型
from langchain.embeddings import OpenAIEmbeddings# 初始化 OpenAIEmbeddingsopenai_embeddings = OpenAIEmbeddings(api_key="your_openai_api_key")# 示例文本texts = ["LangChain 是一个强大的框架", "文本嵌入模型可以将文本转换为向量"]# 嵌入文本embedded_texts = openai_embeddings.embed_documents(texts)print(embedded_texts)
2. 使用 embed_documents 方法嵌入文本列表
# 示例文本列表documents = ["什么是LangChain?","LangChain有哪些核心模块?","如何使用LangChain进行文本嵌入?"]# 嵌入文本列表embedded_documents = openai_embeddings.embed_documents(documents)print(embedded_documents)
3. 使用 embed_query 方法嵌入问题
# 示例查询query = "如何使用LangChain进行文本嵌入?"# 嵌入查询embedded_query = openai_embeddings.embed_query(query)print(embedded_query)
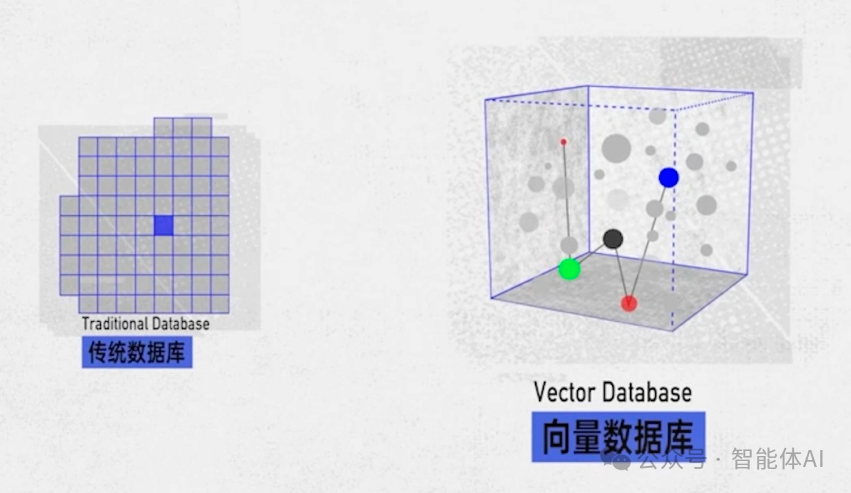
二、Vector Stores(向量数据库)
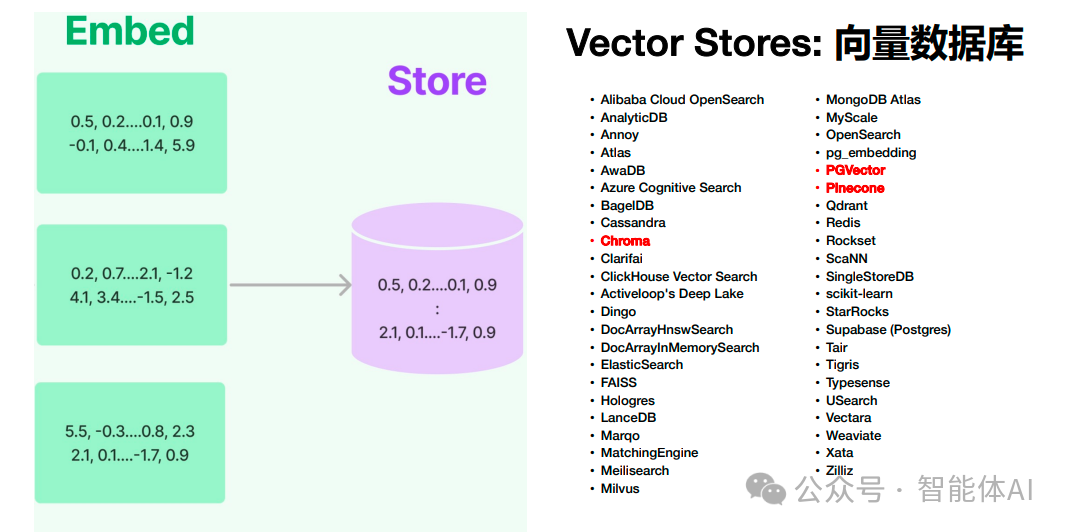
1. 使用 Chroma 作为向量数据库,实现语义搜索
from langchain.vectorstores import Chromafrom langchain.embeddings import OpenAIEmbeddings# 初始化 OpenAIEmbeddings 和 Chromaopenai_embeddings = OpenAIEmbeddings(api_key="your_openai_api_key")chroma_store = Chroma(collection_name="example_collection", embedding_function=openai_embeddings)# 示例文本documents = ["LangChain 是一个强大的框架","文本嵌入模型可以将文本转换为向量","向量数据库可以实现高效的语义搜索"]# 将文本嵌入并存储到 Chromachroma_store.add_texts(documents)# 查询示例query = "如何进行语义搜索?"results = chroma_store.similarity_search(query)print(results)
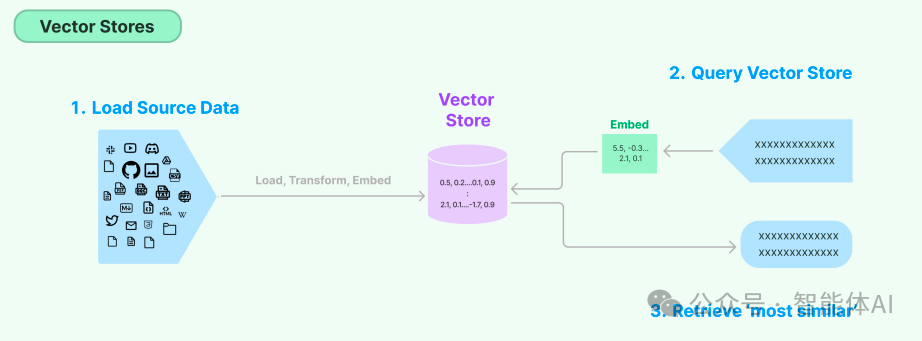
2. Retrieves: 数据检索器:使用嵌入向量进行语义相似度搜索
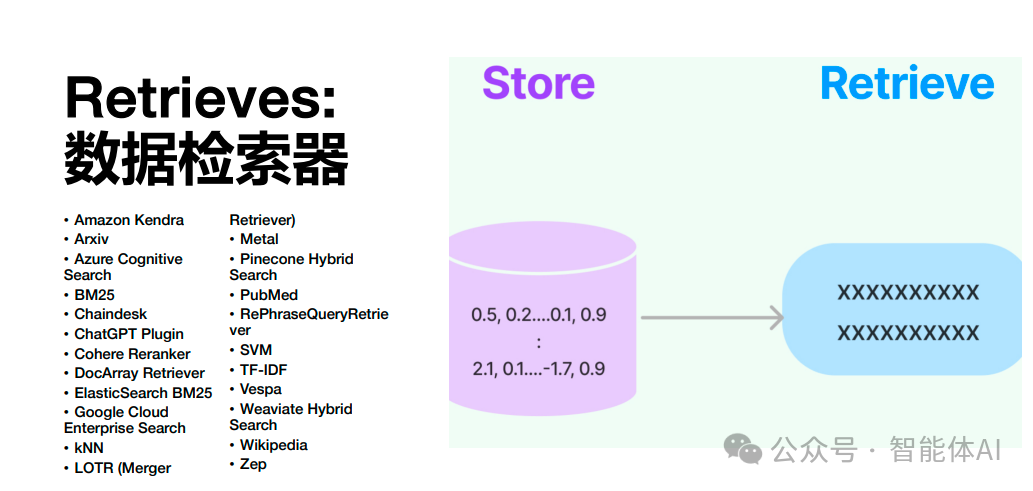
# 示例查询query = "如何使用LangChain进行文本嵌入?"# 嵌入查询并进行语义相似度搜索embedded_query = openai_embeddings.embed_query(query)results = chroma_store.similarity_search_vector(embedded_query)print(results)
3、完整代码案例
import openaiimport osimport jsonfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom icecream import icimport numpy as npfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import Chromafrom langchain.document_loaders import TextLoader# 加载 .env 文件from dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())# 从环境变量中获得你的 OpenAI Key和配置URLopenai.api_key = os.getenv('OPENAI_API_KEY')openai.api_base = os.getenv('OPENAI_API_URL')model = os.getenv('OPENAI_API_MODEL')def serch_4doc():# 加载长文本raw_documents = TextLoader('state_of_the_union.txt',encoding='UTF-8').load()# 实例化文本分割器text_splitter = CharacterTextSplitter(chunk_size=10000, chunk_overlap=0) #为了节省调用次数把200设置成10000,如果切分太大效果不太好# 分割文本documents = text_splitter.split_documents(raw_documents)embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002",base_url=os.getenv('OPENAI_API_URL'),api_key=os.getenv('OPENAI_API_KEY')) #如果直接使用OpenAI的GPT服# 将分割后的文本,使用 OpenAI 嵌入模型获取嵌入向量,并存储在 Chroma 中db = Chroma.from_documents(documents, embeddings_model)#使用文本进行语义相似度搜索query = "What did the president say about Ketanji Brown Jackson"docs = db.similarity_search(query)print(docs[0].page_content)#使用嵌入向量进行语义相似度搜索embedding_vector = embeddings_model.embed_query(query)docs = db.similarity_search_by_vector(embedding_vector)print(docs[0].page_content)#python 入口函数if __name__ == '__main__':serch_4doc()
三、不同语言模型的嵌入向量互换问题
1、不能直接互换使用的原因
-
嵌入维度不同:不同模型生成的嵌入向量可能具有不同的维度。例如,OpenAI 的嵌入模型可能生成 1024 维的向量,而 Hugging Face 的模型可能生成 768 维的向量。这会导致直接比较或结合这些嵌入向量时出现问题。
-
语义空间不同:不同模型训练时使用的数据和方法不同,即使生成相同维度的嵌入向量,这些向量也可能处于不同的语义空间。简单地说,两个模型生成的向量在数学上可能没有可比性。
-
预处理方式不同:不同模型可能对输入文本进行了不同的预处理(如分词、归一化等),导致生成的嵌入向量不具有直接可比性。
2、如何在实际应用中处理嵌入向量
-
统一使用一个嵌入模型:在整个系统中统一使用一个嵌入模型来生成所有文本的嵌入向量,这样可以确保所有嵌入向量在相同的语义空间中。
from langchain.embeddings import OpenAIEmbeddings# 使用 OpenAIEmbeddings 生成嵌入向量openai_embeddings = OpenAIEmbeddings(api_key="your_openai_api_key")# 示例文本texts = ["示例文本1", "示例文本2"]embedded_texts = openai_embeddings.embed_documents(texts)
-
使用转换模型:如果必须使用不同的嵌入模型,可以考虑使用一种转换模型将一个模型的嵌入向量映射到另一个模型的语义空间。这需要大量的数据和训练工作,但在某些情况下是可行的。
-
独立处理不同任务:在一些应用中,不同的任务可以使用不同的嵌入模型。例如,一个任务使用 OpenAI 模型生成的嵌入向量,另一个任务使用 Hugging Face 模型生成的嵌入向量,然后分别处理这些任务的结果,而不是尝试将它们直接结合。
-
多模型集成:对于某些复杂的应用,可以使用多种嵌入模型并结合它们的结果。例如,可以生成多种嵌入向量,并在后续的模型中结合这些向量进行决策。这种方法需要设计合适的集成策略。
示例:使用统一的嵌入模型
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Chroma# 初始化 OpenAIEmbeddings 和 Chromaopenai_embeddings = OpenAIEmbeddings(api_key="your_openai_api_key")chroma_store = Chroma(collection_name="example_collection", embedding_function=openai_embeddings)# 示例文本documents = ["LangChain 是一个强大的框架","文本嵌入模型可以将文本转换为向量","向量数据库可以实现高效的语义搜索"]# 将文本嵌入并存储到 Chromachroma_store.add_texts(documents)# 查询示例query = "如何进行语义搜索?"results = chroma_store.similarity_search(query)print(results)
四、总结
