


PART 01
-
命令:作为快捷入口,只做预检和委托两件事,硬约束是小于100行指令。
-
技能:作为专业知识包,采用渐进式披露架构。核心文档少于2000个Token进入主对话上下文,详细内容分割到资源目录。
-
子代理:作为独立上下文中的专业合作,硬约束是返回内容少于2000个Token,严禁调用。
PART 02
-
内存缓存:重复访问的查询结果被缓存在内存中,TTL设置为300秒。
-
文件缓存:笔记向量被驻留在内存中,避免重复读取文件。
-
嵌入缓存:查询嵌入结果被缓存,相同查询无需重复计算。
PART 03
PART 04
PART 05
-
确定核心需求:您需要处理什么类型的文档?需要多快的搜索响应? -
选择技术栈:本地嵌入模型选哪个?向量维度选多大? -
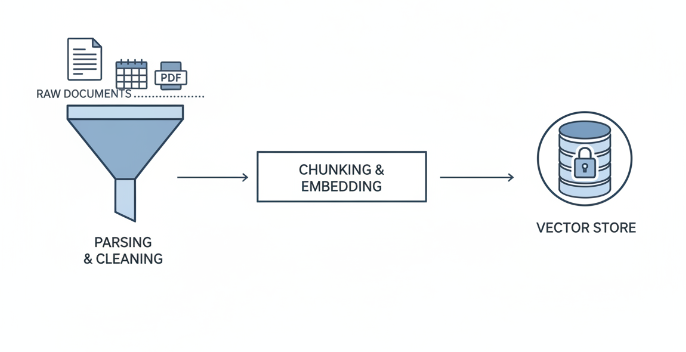
设计数据流:如何从原始文档到向量存储?如何处理错误? -
实现缓存策略:可以缓存哪些结果?缓存多长时间? -
测试性能:搜索响应时间是多少?缓存命中率如何? -
迭代优化:根据实际使用情况调整参数和算法。
