

Clawdbot已经彻底疯狂了,github达到79.5k star,以至于火到被迫改名了moltbot
分享两篇Claude Skills最新论文,有3个核心结论
Clawdbot 的独特之处在于它能够自主处理现实世界的任务:管理电子邮件、安排日历事件、处理航班值机以及按计划运行后台任务。但真正引起人注意的是它的持久记忆系统,该系统保持 24/7 的上下文保留,无限期地记住对话并建立在前一次互动的基础上。Google实锤:测试时扩展或是最大幻觉,SoT是R1强推理的根因
Clawdbot 采用了一种根本不同的方法:它不是基于云端、由公司控制的记忆,而是将一切都保留在本地,让用户完全拥有自己的上下文和技能。
上下文是如何构建的
在深入探讨记忆之前,让我们先了解一下模型在每个请求中看到的内容:
[0] 系统提示(静态 + 条件指令)
[1] 项目上下文(引导文件:AgentS.md、SOUL.md 等)
[2] 对话历史(消息、工具调用、压缩摘要)
[3] 当前消息
系统提示定义了代理的功能和可用工具。与记忆相关的是项目上下文,其中包括注入到每个请求中的用户可编辑的 Markdown 文件:
|
|
|
|---|---|
AGENTS.md |
|
SOUL.md |
|
USER.md |
|
TOOLS.md |
|
这些文件与记忆文件一起存在于代理的工作区中,使整个代理配置透明且可编辑。
上下文与记忆
理解上下文和记忆之间的区别是理解 Clawdbot 的基础。
上下文是模型对单个请求所看到的一切:
上下文 = 系统提示 + 对话历史 + 工具结果 + 附件
上下文是:
-
短暂的 – 仅在此请求期间存在 -
有界的 – 受模型的上下文窗口限制(例如,200K 个 token) -
昂贵的 – 每个 token 都计入 API 费用和速度
记忆是存储在磁盘上的内容:
记忆 = MEMORY.md + memory/*.md + 会话记录
记忆是:
-
持久的 – 即使重启、数天、数月也能存活 -
无界的 – 可以无限增长 -
廉价的 – 存储无需 API 费用 -
可搜索的 – 为语义检索建立索引
代理通过两个专门的工具访问记忆:
memory_search
用途:在所有文件中查找相关记忆

返回结果

memory_get
用途:在找到后读取特定内容

返回结果:
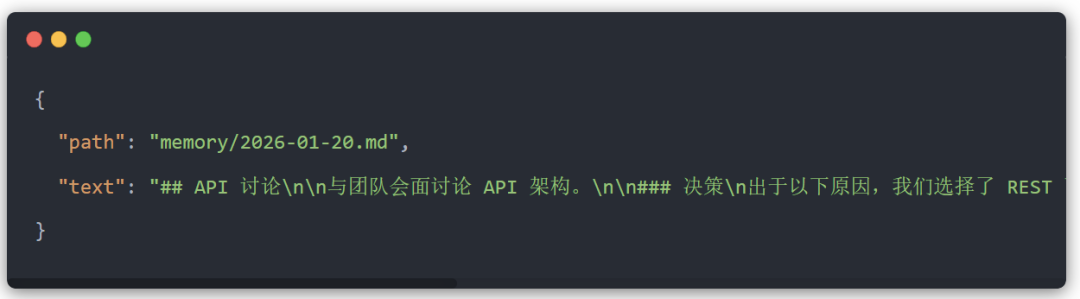
写入记忆
没有专门的 memory_write 工具。代理使用标准的 write 和 edit 工具写入记忆,它将这些工具用于任何文件。由于记忆只是 Markdown,你也可以手动编辑这些文件(它们会自动重新索引)。
写入位置的决定是通过 AGENTS.md 提示驱动的:
|
|
|
|---|---|
|
|
memory/YYYY-MM-DD.md |
|
|
MEMORY.md |
|
|
AGENTS.md
TOOLS.md |
在预压缩刷新和会话结束时也会发生自动写入(在后面的部分中介绍)。
记忆存储
Clawdbot 的记忆系统建立在“记忆是代理工作区中的纯 Markdown”的原则之上。
两层记忆系统
记忆存在于代理的工作区中(默认:~/clawd/):
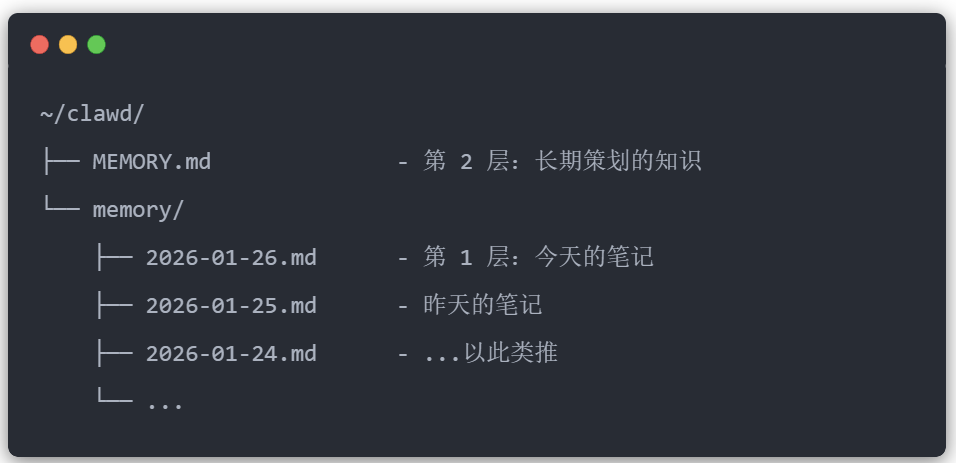
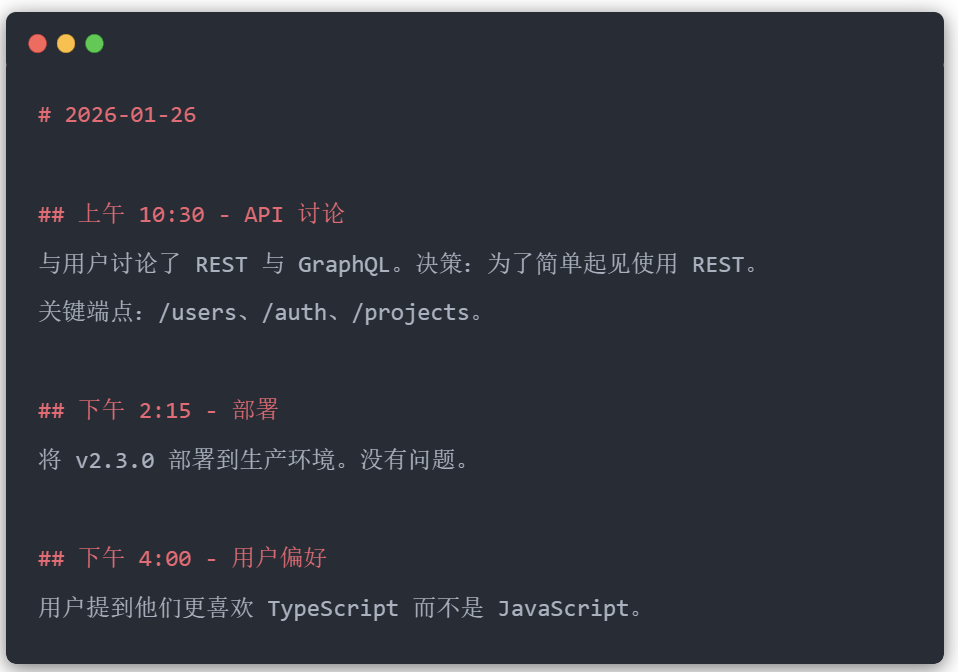
第 1 层:每日日志(memory/YYYY-MM-DD.md)
这些是仅追加的每日笔记,代理全天都会在这里写入。当代理想要记住某事或被明确告知记住某事时,代理会写入此处。
第 2 层:长期记忆(MEMORY.md)
这是经过策划的、持久的知识。当重要事件、想法、决策、意见和经验教训被学习时,代理会写入此处。
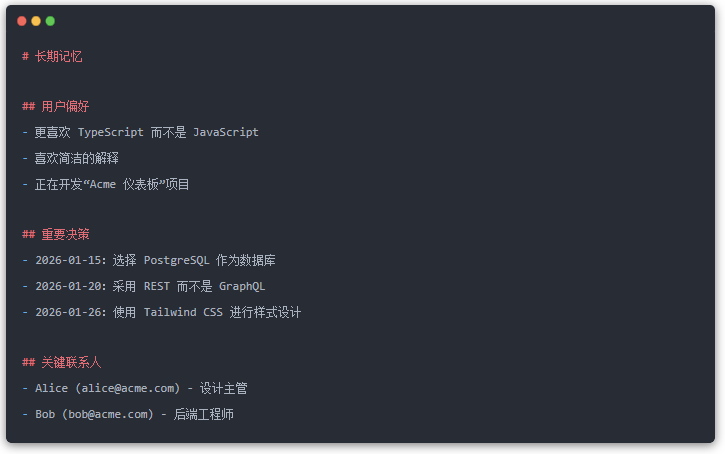
代理如何知道读取记忆
AGENTS.md 文件(自动加载)包含指令:

记忆如何被索引
当你保存一个记忆文件时,幕后会发生以下情况:


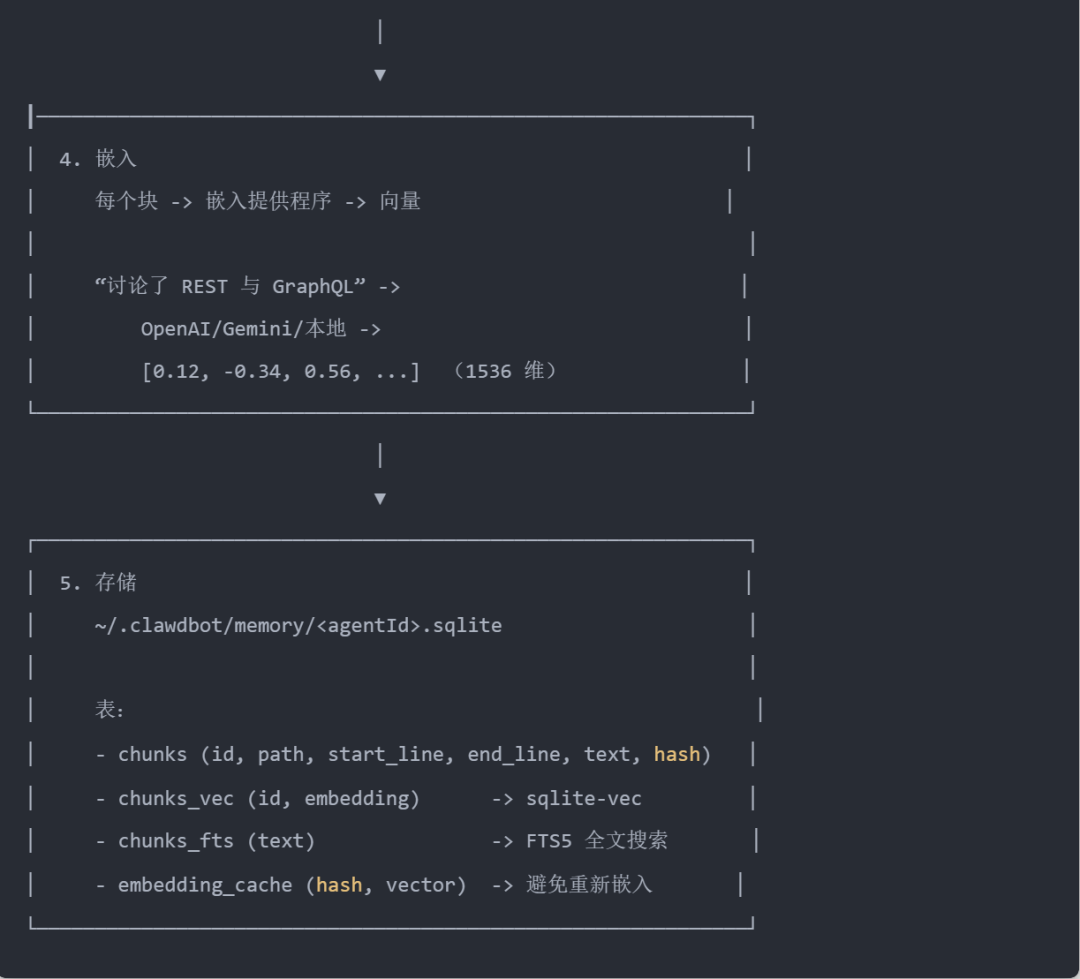
sqlite-vec 是一个 SQLite 扩展,可直接在 SQLite 中启用向量相似性搜索,无需外部向量数据库。
FTS5 是 SQLite 内置的全文搜索引擎,支持 BM25 关键字匹配。它们一起允许 Clawdbot 从单个轻量级数据库文件运行混合搜索(语义 + 关键字)。
如何搜索记忆
当你搜索记忆时,Clawdbot 会并行运行两种搜索策略。向量搜索(语义)查找含义相同的内容,BM25 搜索(关键字)查找具有确切标记的内容。
结果通过加权评分组合:
finalScore = (0.7 * vectorScore) + (0.3 * textScore)
为什么是 70/30?语义相似性是记忆回忆的主要信号,但 BM25 关键字匹配可以捕获向量可能遗漏的确切术语(名称、ID、日期)。低于 minScore 阈值(默认 0.35)的结果将被过滤掉。所有这些值都是可配置的。
这可确保无论你是在搜索概念(“那个数据库东西”)还是具体内容(“POSTGRES_URL”),都能获得良好的结果。
多代理记忆
Clawdbot 支持多个代理,每个代理都具有完整的记忆隔离:

Markdown 文件(真实来源)存在于每个工作区中,而 SQLite 索引(派生数据)存在于状态目录中。每个代理都有自己的工作区和索引。记忆管理器由 agentId + workspaceDir 键控,因此不会自动发生跨代理记忆搜索。
代理可以读取彼此的记忆吗? 默认情况下不可以。每个代理只能看到自己的工作区。然而,工作区是一个软沙箱(默认工作目录),而不是硬边界。除非你启用严格的沙箱,否则代理理论上可以使用绝对路径访问另一个工作区。
这种隔离对于分离上下文很有用。一个用于 WhatsApp 的“个人”代理和一个用于 Slack 的“工作”代理,每个代理都有不同的记忆和个性。
压缩
每个 AI 模型都有上下文窗口限制。Claude 有 200K 个 token,GPT-5.1 有 1M 个。长时间的对话最终会触及这个上限。
发生这种情况时,Clawdbot 会使用压缩:将较旧的对话总结为一个紧凑的条目,同时保持最近的消息不变。
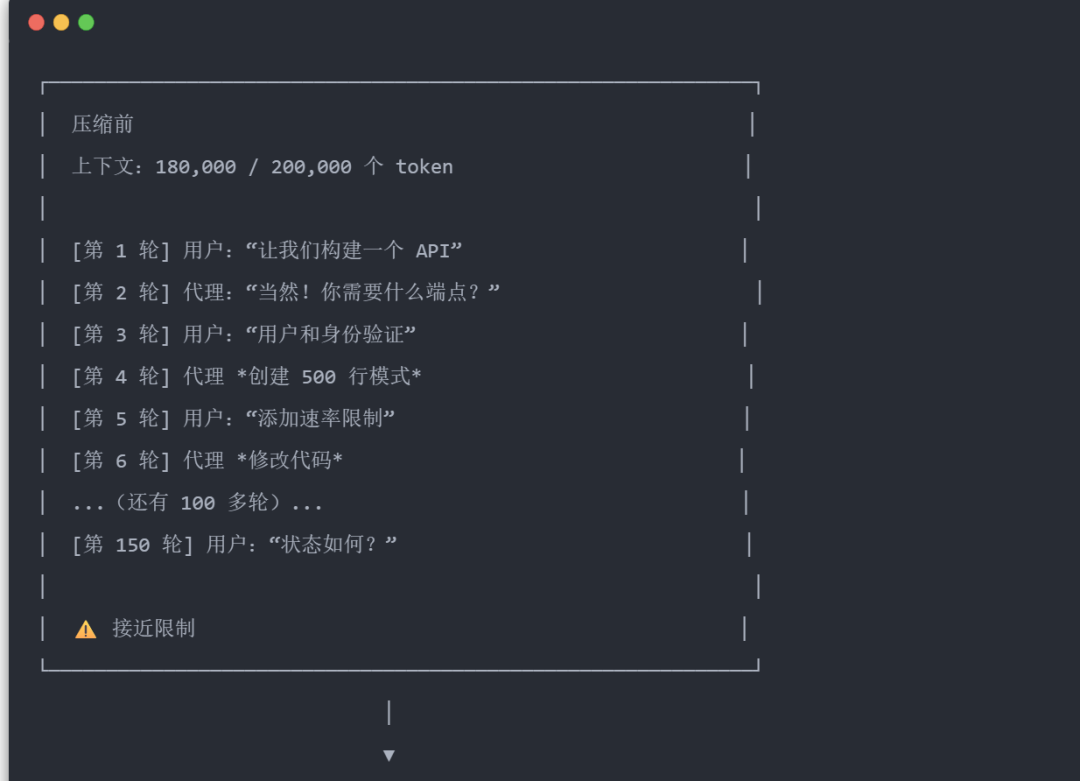

自动与手动压缩
自动:在接近上下文限制时触发
-
你会看到: 🧹 自动压缩完成(在详细模式下) -
原始请求将使用压缩后的上下文重试
手动:使用 /compact 命令
/compact 关注决策和未决问题
与某些优化不同,压缩会持久化到磁盘。摘要会写入会话的 JSONL 记录文件,因此将来的会话会从压缩后的历史记录开始。
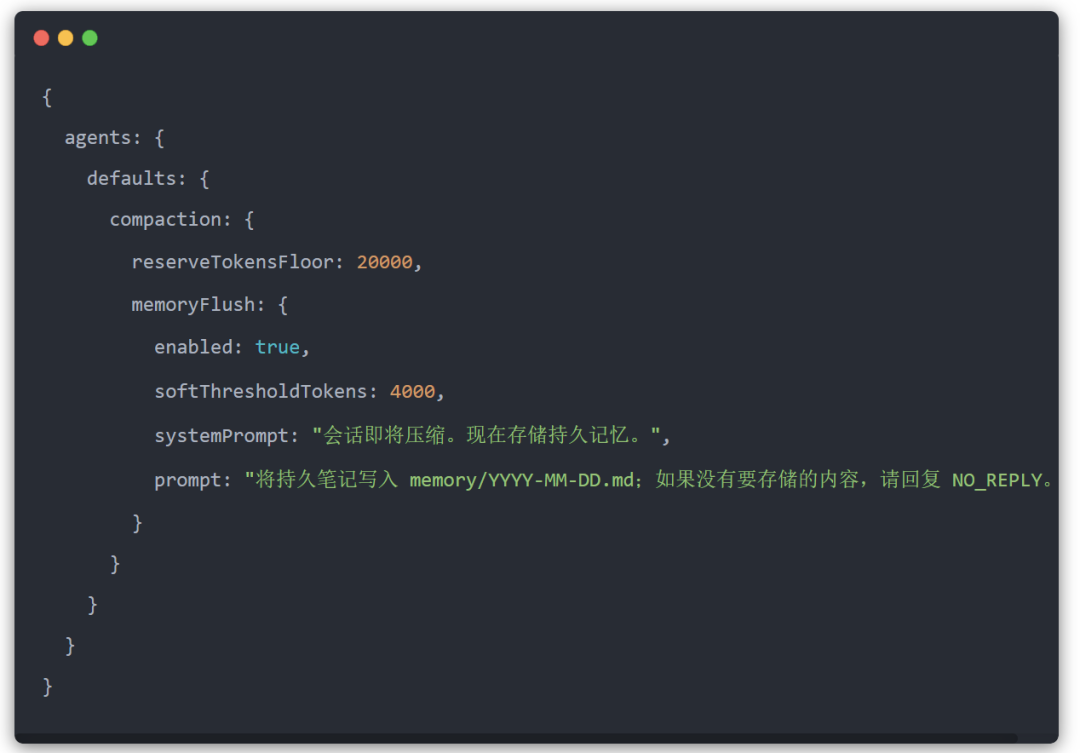
记忆刷新
基于 LLM 的压缩是一个有损过程。重要信息可能会被总结掉并可能丢失。为了解决这个问题,Clawdbot 使用了压缩前的记忆刷新。
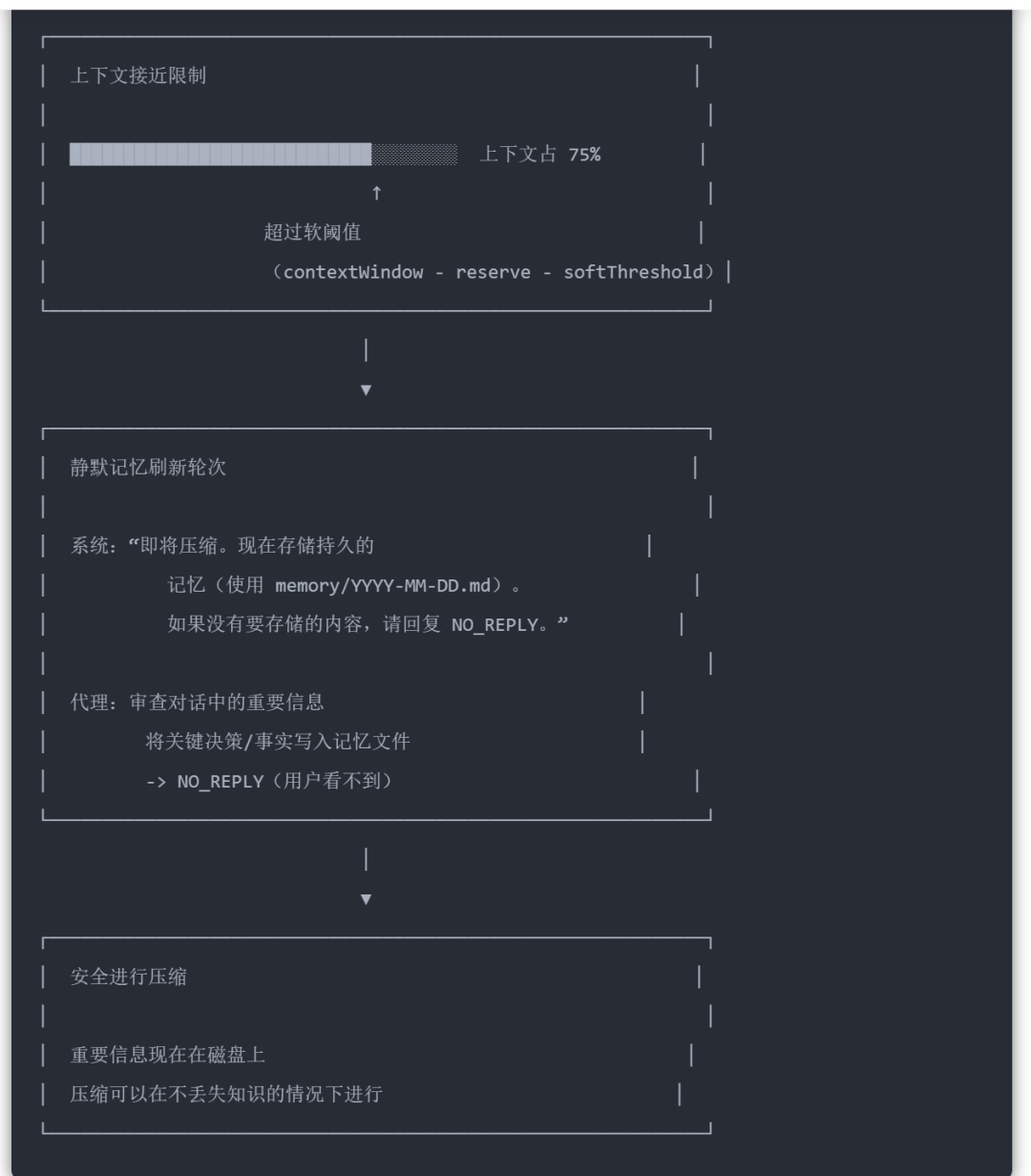
记忆刷新可在 clawdbot.yaml 文件或 clawdbot.json 文件中配置。
修剪
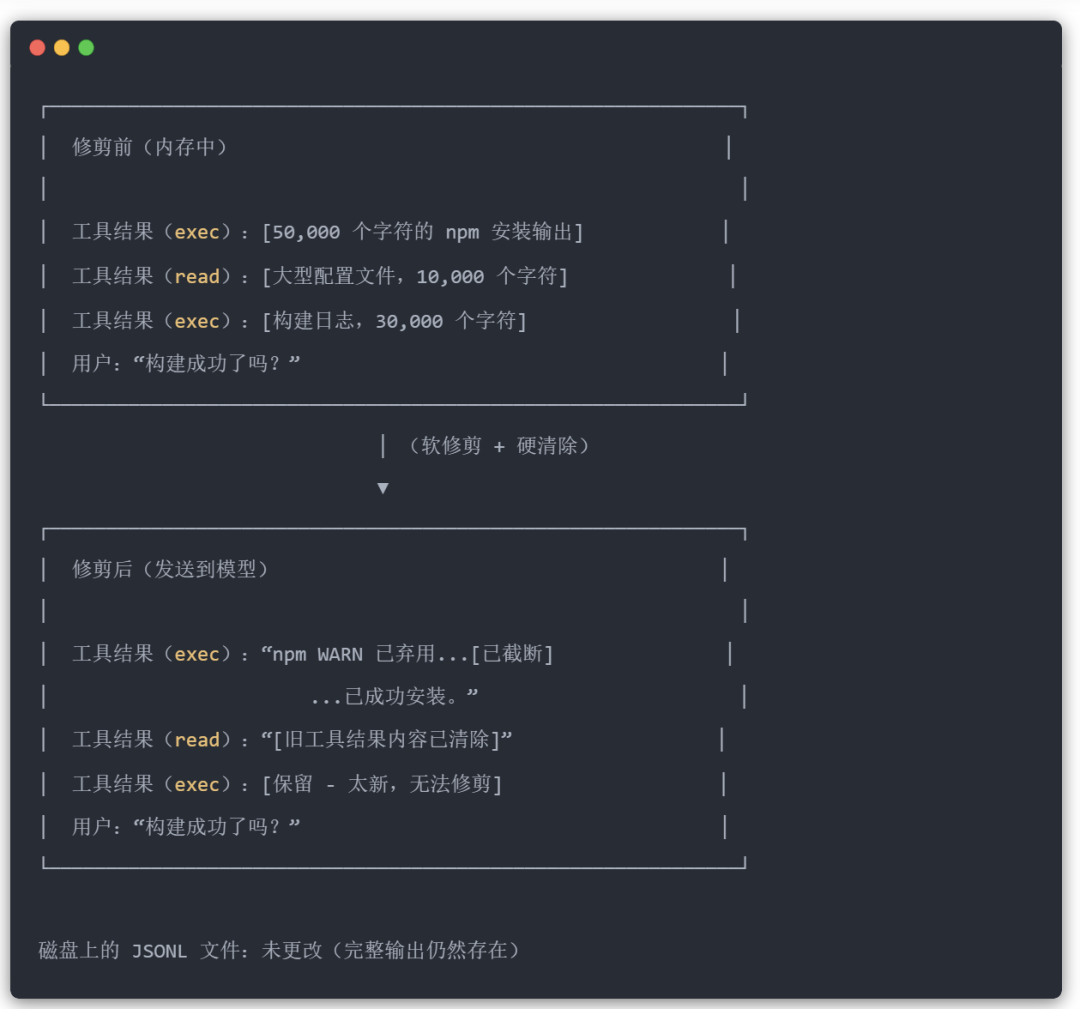
工具结果可能非常庞大。单个 exec 命令可能会输出 50,000 个字符的日志。修剪可以在不重写历史记录的情况下修剪这些旧输出。这是一个有损过程,旧输出无法恢复。
缓存 TTL 修剪
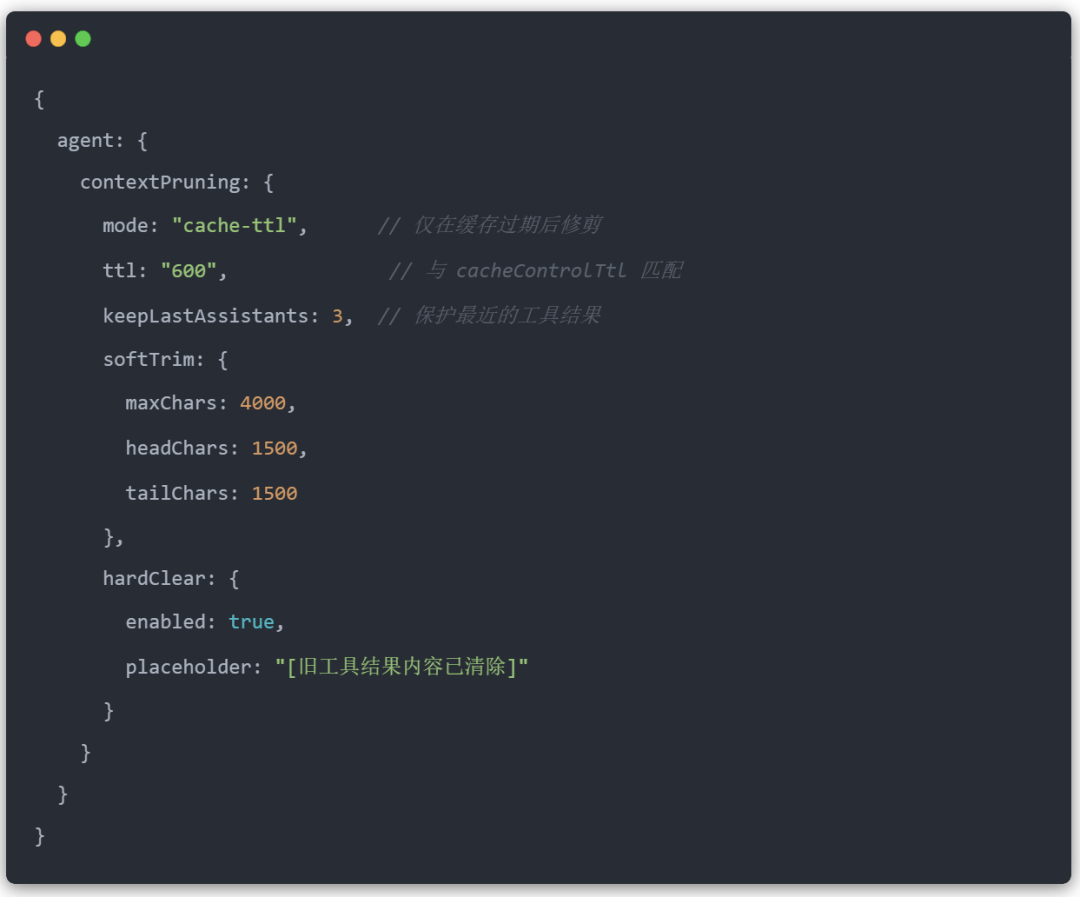
Anthropic 将提示前缀缓存最多 5 分钟,以减少重复调用的延迟和成本。在 TTL 窗口内发送相同的提示前缀时,缓存的 token 成本降低约 90%。TTL 过期后,下一个请求必须重新缓存整个提示。
问题:如果会话在 TTL 之后处于空闲状态,下一个请求将丢失缓存,并且必须以完整的“缓存写入”价格重新缓存完整的对话历史记录。
缓存 TTL 修剪通过检测缓存何时过期并在下一个请求之前修剪旧工具结果来解决此问题。较小的提示重新缓存意味着更低的成本:
会话生命周期
会话不会永远持续。它们会根据可配置的规则重置,为记忆创建自然的边界。默认行为是每天重置。但还有其他模式可用。
|
|
|
|---|---|
daily |
|
idle |
|
daily+idle |
|
会话记忆钩子
当你运行 /new 开始新会话时,会话记忆钩子可以自动保存上下文:

结论
Clawdbot 的记忆系统之所以成功,是因为它遵循了几个关键原则:
-
透明胜过黑盒,记忆是纯 Markdown。你可以阅读它、编辑它、对其进行版本控制。没有不透明数据库或专有格式。 -
搜索胜过注入,代理搜索相关内容,而不是用所有内容填充上下文。这使上下文保持专注并降低成本。 -
持久性胜过会话,重要信息以文件形式保存在磁盘上,而不仅仅存在于对话历史中。压缩无法破坏已保存的内容。 -
混合胜过纯,仅向量搜索会遗漏完全匹配。仅关键字搜索会遗漏语义。混合搜索两者兼得。
blog:https://manthanguptaa.in/posts/clawdbot_memory/
