

用AI写地学文献综述:从超大语料到证据链
一位 Reddit 法律研究者把 2 万份案件材料(约 100MB)通过 OCR 整合为单一可检索文本,并用 AI 在 20–30 小时内完成原本需要数百小时的线性阅读。这不是“速度更快”的故事,而是“组织方式改变”的故事。把这类方法迁移到地学文献综述,可以显著提升证据管理与研究版图构建的效率。
本文在吸收该案例的方法论后,重新组织为地学综述写作路径,重点探索其在地学文献综述中的潜力。
案例给地学综述的启示
关键不在于 AI 的“智能”,而在于语料的“可检索与可追溯”。当海量文献被统一成结构化语料,并保留原始来源,AI 才能快速形成证据链与研究地图。对地学而言,这相当于把“散落的地质记录”变成“可查询的研究地层”。
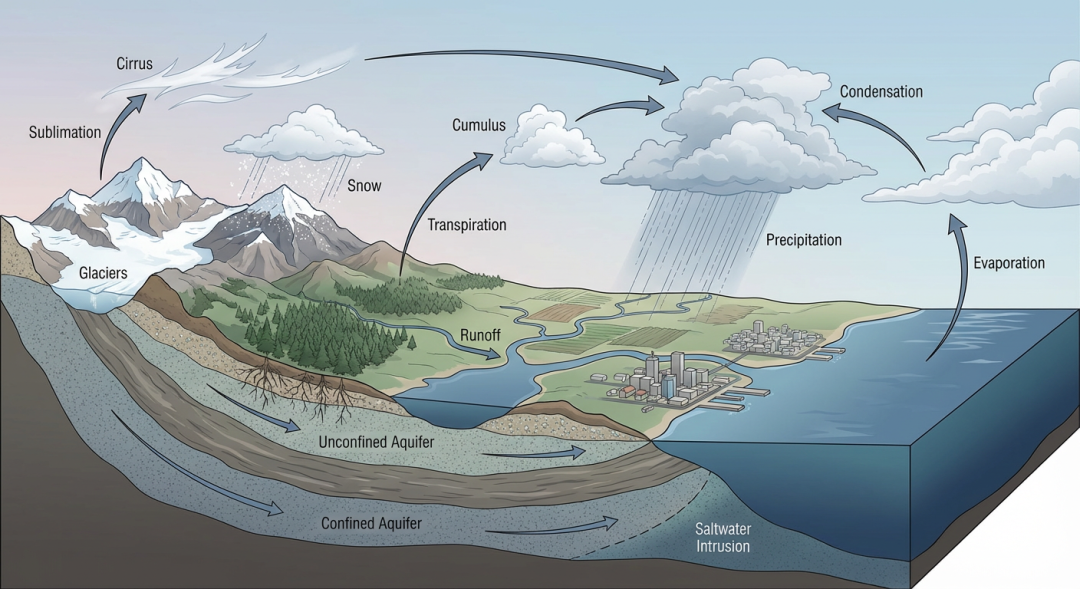
为什么地学综述更依赖结构化语料
-
跨尺度与跨学科:从大气—水文—生态,尺度跨度大,术语体系不完全一致。
-
资料类型混杂:论文、图件、报告、遥感与野外记录并存,无法靠线性阅读完成整合。
-
区域性与时代性强:同一过程在不同地区与地史时期差异显著,容易被“一般化结论”遮蔽
-
争议与不确定性多:相同数据可能支持不同机制,需要清晰证据链而非单一结论。
策略一:语料整合,让资料“可检索、可追溯”
目标:把分散文献整理成结构化语料库,并保留来源信息。
做法要点:
推荐元数据模板:
[Source]
Title:
Year:
Region:
Timescale:
Method:
Data Type:
DOI/URL:
优化建议:补充“干旱”“地区”“关键词或关键方法(同位素、遥感分类等)”。这会显著提升后续检索和比对的准确度。

策略二:分层问题体系,驱动综述结构
地学综述的关键不是“文献数量”,而是“问题结构”。可用四层问题体系组织检索与写作:
层级1:版图与共识
-
该区域/过程的主流认识是什么?
-
关键地质事件的时间框架如何被不同证据约束?
层级2:模式与差异
-
不同数据类型给出的趋势是否一致(遥感反演 vs. 观测资料)?
层级3:机制与因果
-
证据支持哪种主控机制(构造驱动、气候驱动、物源变化等)?
-
该机制能否同时解释多类观测?
层级4:不确定性与空白
-
哪些关键时段或区域数据稀缺?
-
结论对样本规模或方法假设是否敏感?
分层提问能把“共识—争议—空白”直接转化为综述的章节骨架。
策略三:证据链与伦理,确保综述可信度
地学综述必须强调证据链:
-
证据来自哪些数据类型(野外、实验、遥感、模型)。
-
哪些是“观测事实”,哪些是“解释与推断”。
-
是否有独立来源交叉验证。
同时注意数据与报告的版权、使用许可,以及敏感地理信息的合规处理。AI 生成内容必须可追溯到具体文献或数据来源,避免“看似合理”的无依据推断。
从语料到综述:推荐结构
-
研究范围与问题定义:区域/过程/时间尺度的界定与核心问题。 -
数据与方法概览:数据类型、时间约束、分析方法的演进。 -
研究进展(按时间、区域或方法组织):每段突出“共识 + 证据”。 -
关键争议与机制解释:展示不同证据链与对应解释路径。 -
不确定性与空白:缺失数据、方法局限、尺度转换问题。 -
未来研究方向:可操作的采样、分析或模型建议。
90分钟起步流程(可落地)
-
第1–30分钟:语料整理。选定 20–50 篇核心文献,OCR 并补齐元数据。 -
第31–50分钟:分层问题列表。每层至少 3 个问题。 -
第51–70分钟:快速检索与归纳。让 AI 按问题返回证据与引用提示。 -
第71–90分钟:生成综述框架。把“共识—争议—空白”转成章节结构。
这套方法的潜力
它不仅提高阅读速度,更重要的是让地学综述从“文献堆叠”变成“研究地图构建”。当语料持续更新,综述也可以迭代为“活的知识体系”,随新数据补充而自动修正证据链与研究空白。
总结
地学文献综述的核心不是“多读几篇”,而是建立一张可追溯的研究地图。通过语料整合、分层问题体系与证据链管理,AI 可以把海量文献转化为“可写、可证、可迭代”的综述框架。研究者负责地学判断与机制解释,AI 负责系统检索与证据组织,两者结合可以显著提升地学综述的深度与效率。
