

AI模型库 · 今日重点
阿里刚刚开源的这套多模态模型,可能会改变“搜索”和“RAG”的底层逻辑
如果你最近在关注 AI 模型圈,会发现一个非常明显的变化:
大家讨论的不再只是“能不能生成”,而是——能不能真正“理解”。
就在 1 月 9 日,阿里通义悄悄扔出了一套重量级开源模型组合:
Qwen3-VL-Embedding + Qwen3-VL-Reranker
没有铺天盖地的营销,但在开发者圈子里,这套模型已经开始被反复提起。
原因只有一个:
它直指多模态检索与 RAG 的核心痛点。
一、先说一句大白话:它是干嘛的?
如果用一句话解释这套模型的价值:
“让 AI 能把图片、文字、视频,放在同一个‘理解层’里做搜索和判断。”
过去我们做搜索、做知识库,大多是:
-
文本靠文本
-
图片靠图片
-
视频拆帧再配描述
模态之间是割裂的。
而 Qwen3-VL 的目标是:
👉 统一语义空间,让图文视频可以互相检索、互相理解。
二、这次阿里到底开源了什么?
这不是一个模型,而是一整套工程级组合方案。
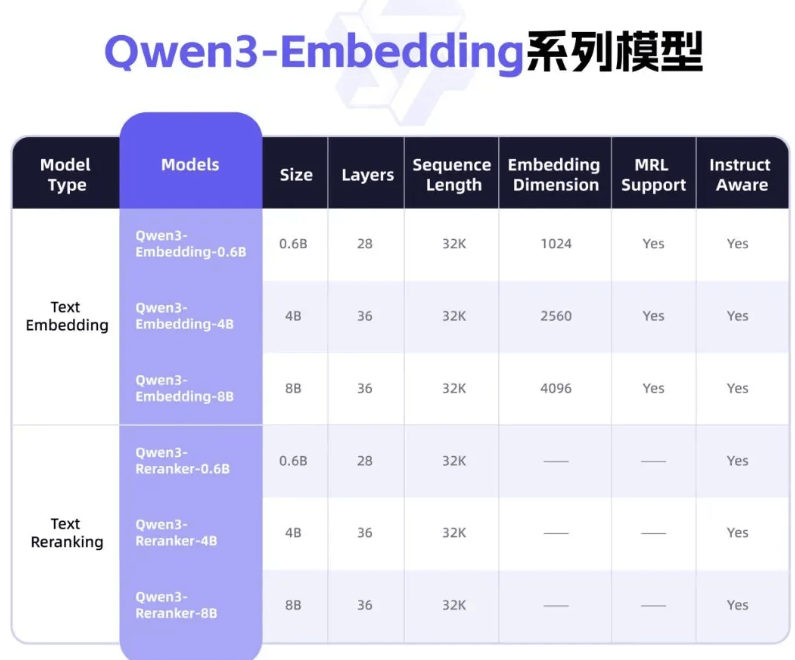
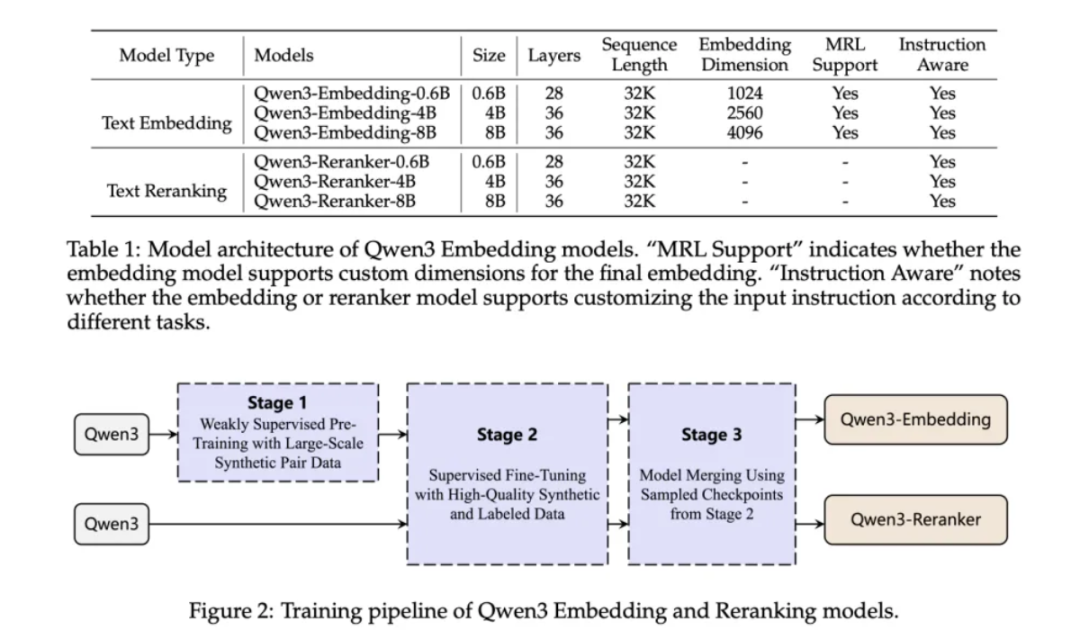
1️⃣ Qwen3-VL-Embedding:多模态“召回引擎”
你可以把它理解成:
多模态世界里的向量发动机
它负责的事情很纯粹:
-
把 文本 / 图片 / 视频帧 / 图表 / 截图
-
编码成 统一语义向量
-
用于大规模相似度检索
适合用在:
-
搜索系统第一层召回
-
多模态 RAG 的向量库
-
视频 / 素材 / 商品的快速检索
一句话总结:
快、全、规模化。
2️⃣ Qwen3-VL-Reranker:多模态“精排大脑”
如果说 Embedding 是“先捞出来”,
那 Reranker 就是:
判断“谁才真的相关”
它会:
-
同时读取「查询 + 候选内容」
-
做跨模态深度理解
-
给出更可靠的相关性评分
最终效果就是:
👉 搜索结果更准,RAG 命中率更高。
三、为什么这套模型“很不一样”?
① 它不是 Demo 型,而是工程型
Embedding + Reranker
这是搜索系统最成熟、最稳妥的结构。
意味着什么?
-
可以直接接入向量数据库
-
不用推翻原有架构
-
真正能进生产环境
这是很多“论文型模型”做不到的。
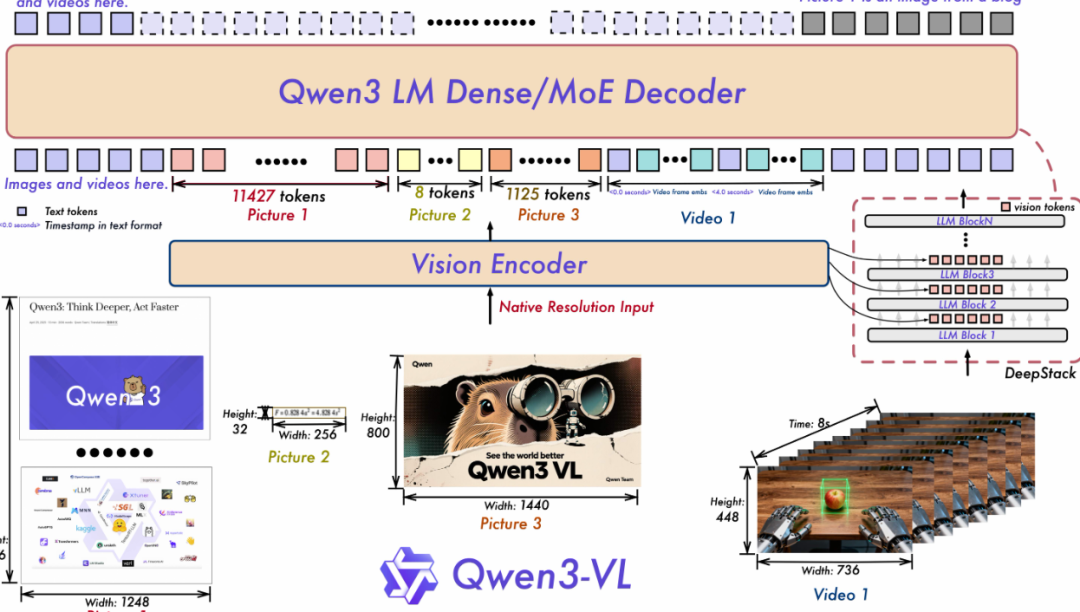
② 多模态不是拼接,而是统一理解
Qwen3-VL 的关键点在于:
-
图像、文本、视频
-
被投射到同一个语义空间
这带来的改变非常大:
-
一句话找视频
-
一张图反查文档
-
截图直接进知识库
对搜索和 RAG 是质变。
③ 它是开源的
这一点,非常关键。
-
权重开放
-
可私有部署
-
可二次微调
-
可长期维护
对于企业、开发者来说,
安全感和可控性,直接拉满。
四、它可能影响哪些方向?
我们大胆一点,直接说趋势。
🔹 多模态 RAG
文档不再只是“文字”,而是“视觉内容整体”
🔹 搜索系统
从关键词 → 语义 + 视觉理解
🔹 视频与内容平台
老内容被重新激活,真正“可搜索”
🔹 企业知识库
PPT、截图、PDF、系统页面都能被理解
五、AI模型库的判断
在 AI模型库 看来:
Qwen3-VL 系列,很可能会成为未来一年多模态检索的基础件之一。
它不炫技,但极其重要。
它不追热度,但非常“值钱”。
如果你在做:
-
AI 搜索
-
RAG
-
内容平台
-
企业知识库
这套模型,值得你现在就收藏。
