

在浏览器中做向量检索,一直是个麻烦事。原生的IndexDB并不支持向量。之前笔者使用过pglite方案,完成浏览器内的向量检索及问答。我已经将它做为一款书签/桌面/资讯于一体的chrome插件,感兴趣的朋友可以下载使用。
今天,我要再介绍一个原生解决浏览器向量检索的开源产品EdgeVec。它是一个完全运行在浏览器中的向量数据库,通过WebAssembly实现,导入即用,无需任何外部依赖。
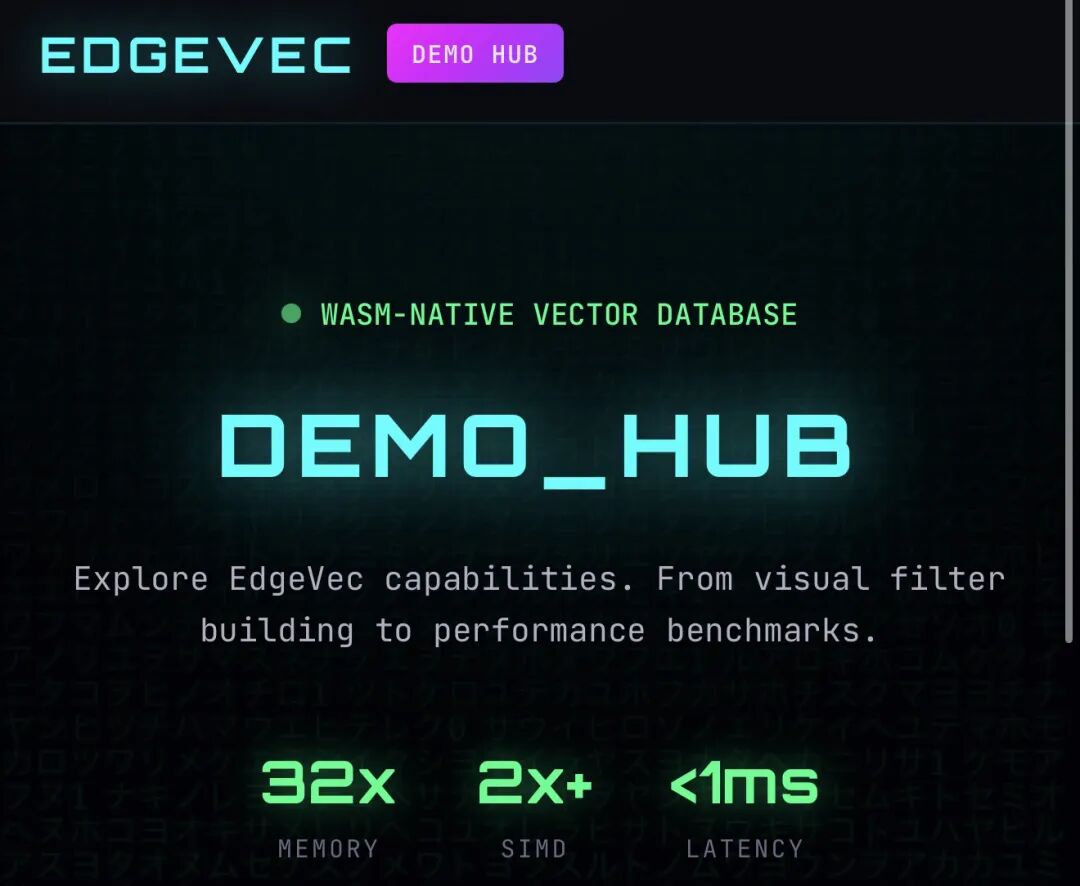
EdgeVec把完整的向量数据库能力直接搬到浏览器里。所有计算在本地完成,数据不出设备,同时提供企业级的功能特性。
核心特性
零配置部署
像使用普通npm包一样简单,无需Docker、服务器或任何配置文件。一行import,立即可用。
极致内存优化
通过二值量化技术,将向量存储空间压缩32倍。100万个768维向量从300MB压缩到10MB,让浏览器也能处理大规模数据。
硬件加速
利用WebAssembly SIMD指令,向量运算速度提升2-8倍。在支持SIMD的浏览器中(Chrome 91+、Firefox 89+、Safari 16.4+),汉明距离计算可达8.75倍加速。
完整数据库功能
-
元数据过滤:支持SQL风格的过滤表达式 -
软删除:O(1)删除操作,支持压缩回收空间 -
持久化存储:数据可保存到IndexedDB -
内存监控:实时监控WASM堆使用情况
性能表现
768维向量搜索测试(M1 MacBook):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
距离计算性能:
-
点积运算:374ns(2.1 Gelem/s吞吐量) -
汉明距离:4.5ns(40 GiB/s吞吐量)
快速上手
npm install edgevec
import init, { EdgeVec } from 'edgevec';
import { pipeline } from '@xenova/transformers';
// 初始化
await init();
const embedder = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2');
const db = new EdgeVec({ dimensions: 384 });
// 添加向量
const embedding = await embedder(text, { pooling: 'mean', normalize: true });
db.insertWithMetadata(new Float32Array(embedding.data), {
category: "document",
timestamp: Date.now()
});
// 搜索
const results = db.searchWithFilter(
queryVector,
'category = "document"',
10
);
// 持久化
await db.save("my-vector-db");技术对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
