

一、传统检索的痛点
现有检索系统(如BM25或向量库)往往存在两大短板:
-
信息碎片化:仅返回孤立文本片段,割裂整体逻辑 -
上下文缺失:难以理解文档的层次结构与宏观主题
当传统检索还在“关键词匹配”的平原上徘徊时,RAPTOR已带我们登上语义理解的树冠层。这片由斯坦福培育的“知识森林”,正为LLM注入真正的理解力——未来已来,只是尚未均匀分布。
二、RAPTOR的森林建造术
RAPTOR通过构建语义摘要树解决上述问题,其核心流程如同培育一片知识森林:
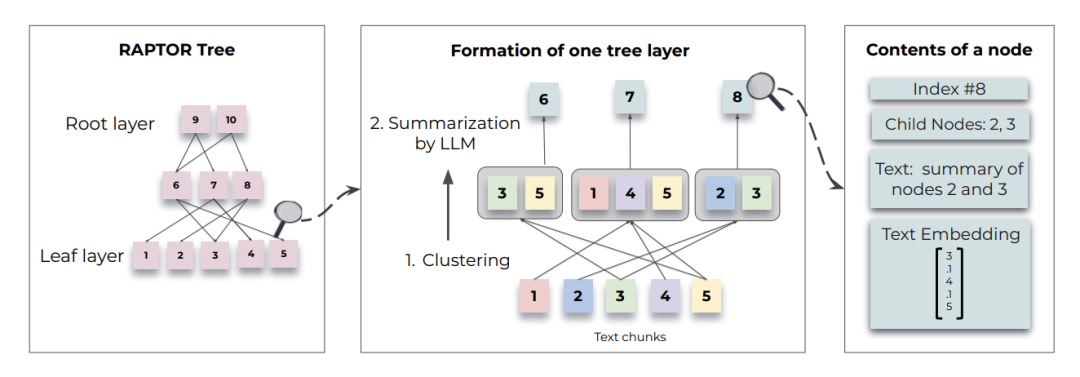
第一步:播种叶子(文本切分与嵌入)
文本块 = 分割长文档(文档) # chunk_size=100+且保持句子完整
叶子节点 = [SBERT嵌入(块) for 块 in 文本块] # 生成语义向量
第二步:培育枝干(聚类与总结)
-
用高斯混合模型(GMM) 对叶子节点软聚类
→ 同一簇内文本语义相近(允许重叠)
❝
聚类算法采用的是高斯混合模型(Gaussian Mixture Models, GMMs),同时由于单个文本可能包含与多个主题相关的信息,所以这篇文章采用了软聚类,即节点可以同时属于多个聚类,而不需要事先设定聚类的固定数量,将它们包含在多个摘要中。
-
调用LLM总结引擎(如GPT-3.5)生成簇摘要
→ 产出中间层摘要节点

第三步:生长树冠(递归构建)
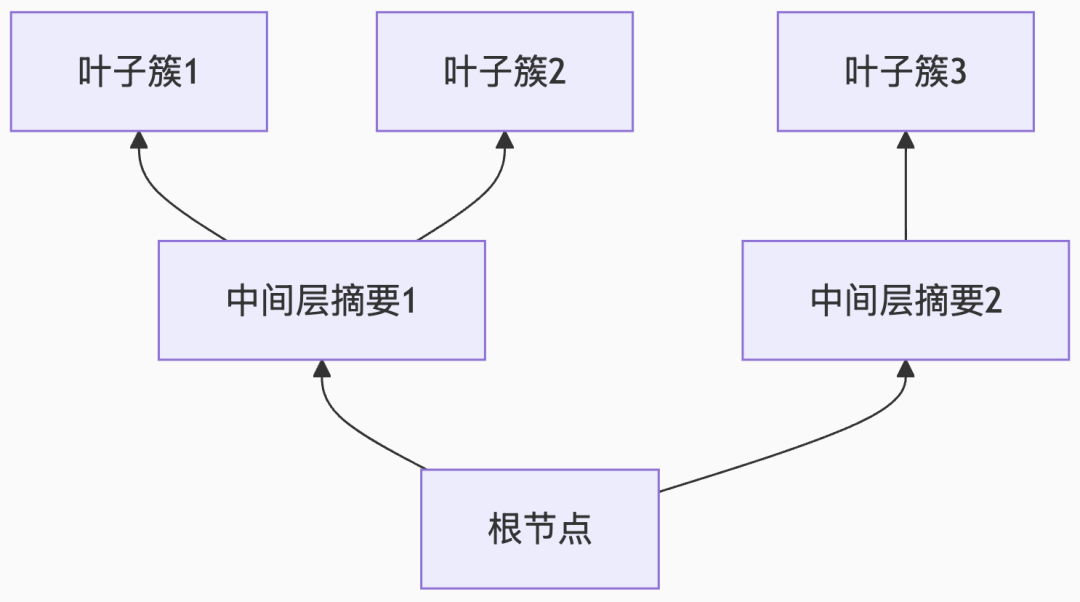
循环执行第二步,直到生成最终根节点,形成自底向上的语义树形结构:
-
根部:全局主题概括 -
中部:章节级摘要 -
叶层:原始文本细节
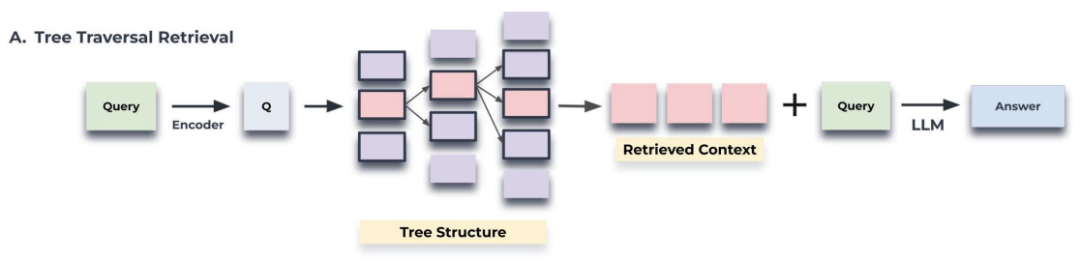
三、查询机制:两种遍历策略
当用户发起查询时,RAPTOR提供双通道检索:
-
树遍历:深度优先遍历 根节点 → 中层节点 → 叶子节点,从根节点开始,计算查询和节点之间的余弦相似度,逐层选择最相关的节点,直到叶子节点。
-
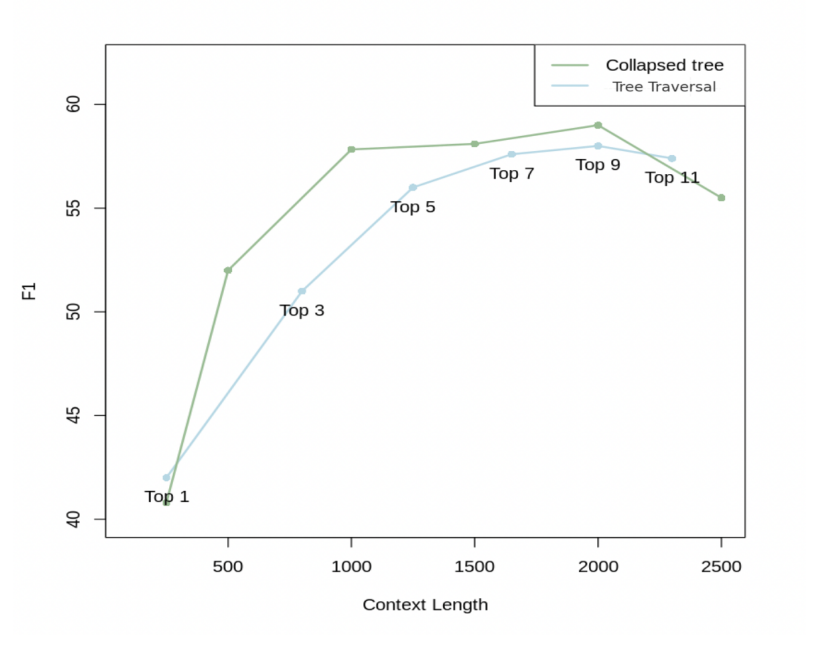
折叠树:压缩森林查询 平铺所有节点并行比对,将所有节点视为同一层次,选择最相关的节点,直到达到模型输入的token限制。

树遍历 VS 压缩树
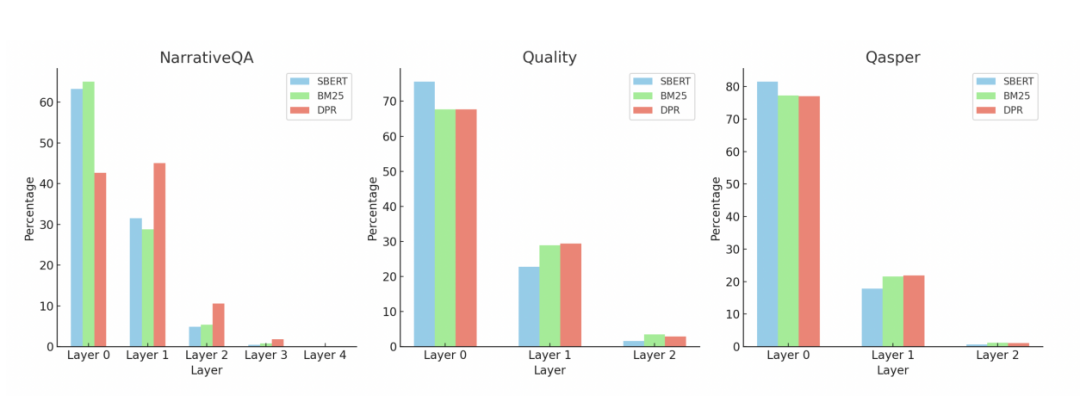
与其他检索方法相比,RAPTOR 独特优势包括:
-
综合信息检索:RAPTOR通过多层次树结构,能够在检索过程中同时考虑文本的高层次主题信息和低层次细节信息,从而实现更全面的综合信息检索。 -
灵活的查询策略:RAPTOR的树遍历和折叠树查询机制,能够根据不同的查询需求灵活地选择和组合不同层次的节点信息,从而更好地应对复杂的多步推理问题。 -
高效的聚类算法:使用高斯混合模型(GMM)进行聚类,能够有效地捕捉文本片段之间的相似性,并将相似的片段聚类在一起,从而提高检索的相关性和准确性。
这些优势使得RAPTOR在处理需要综合整个文档信息的复杂问答任务时表现出色,特别是在文学领域的长篇文本理解任务中。
四、总结
本文介绍了一种新颖的基于树的检索系统:RAPTOR,通过各种抽象级别的上下文信息来增强LLM的参数知识。采用递归嵌入、聚类和摘要技术,RAPTOR创建了一个分层树结构,能够跨检索语料库的各个部分综合信息。在查询阶段,RAPTOR 利用此树结构进行更有效的检索。实验表明,使用递归总结的检索方法在多个任务上相较于传统的检索增强语言模型提供了显著的改进。在涉及复杂、多步骤推理的问题解答任务中,展示了最优的结果。例如:通过将RAPTOR检索与GPT-4结合使用,能够将QuALITY基准上的最佳性能提高20%的准确率。
五、答疑
问:RAPTOR 如何区分问题来源、避免版本错乱以及处理多版本文档的问题?
👉👉👉 核心机制解析
-
问题区分与来源定位
-
索引阶段区分:RAPTOR在构建索引时,会为每个文档/片段添加唯一元数据(如文件名、版本号、时间戳)。例如: # 伪代码:为每个文本块嵌入元数据
text_chunk = "某条款内容..."
metadata = {"doc_id": "合同_v3", "section": "4.2", "version": "2025-06"} -
检索阶段定位:当用户提问时,RAPTOR的检索器会:
-
优先召回与问题最相关的文本片段; -
返回片段的元数据(如 doc_id和version),明确标注答案来源。
-
版本错乱的预防
-
为每个版本创建独立索引(如 索引_v1、索引_v2); -
通过版本过滤器限定检索范围(例如用户指定“基于2025版回答”)。 -
隔离索引策略:若需同时处理多版本: -
动态元数据过滤: # 示例:在查询中附加版本过滤条件
query = "某条款的解释?"
filters = {"version": "2025"}
results = retriever.retrieve(query, filters=filters) -
信息交错的应对
-
分块独立性:RAPTOR的树状索引确保每个文本块(chunk)独立存储元数据,回答时仅使用检索到的块的元数据,避免混合。 -
答案生成控制:大模型(LLM)生成答案时,严格限制仅引用检索到的片段。例如: ❝
指令模板:
"仅使用以下上下文片段回答问题,并标注来源:
[片段1] {文本} (来源: 文档A_v2)
[片段2] {文本} (来源: 文档B_v1)
问题:{用户问题}"
实际应用中的额外机制
针对多版本场景,需补充以下设计:
-
版本感知检索器
开发支持版本参数的检索接口,自动路由查询到对应版本的索引。 -
用户显式指定版本
-
前端提供版本选择器(如下拉菜单); -
自然语言解析用户意图(例如:“参考最新版回答” → 自动定位 version:latest)。
冲突检测与告警
若问题涉及多个版本(如“比较v1和v2差异”),系统可:
-
并行检索不同版本; -
生成对比回答,并高亮标注版本来源。
中央化元数据管理
使用数据库记录文档版本关系,确保:
-
版本号全局唯一; -
新旧版本可溯源(如 合同_v2→ 继承自合同_v1)。
结论
-
问题区分可行性:
✅ RAPTOR可通过元数据嵌入精确标识答案来源(文档名+版本号),技术上完全可行。 -
版本错乱风险:
⚠️ 若无防护措施,混合索引不同版本会导致错乱。
✅ 解决方案:隔离索引 + 查询过滤可彻底规避。 -
信息交错问题:
⚠️ 若未限制LLM的上下文范围,可能交叉引用不同版本。
✅ 解决方案:强制LLM仅基于检索片段生成答案,并附加来源元数据。 -
多版本最佳实践:
✅ 推荐按版本分索引 + 显式版本过滤 + 答案来源标注,三者结合可确保:
-
100%答案来源可追溯; -
零版本混淆; -
支持并行多版本查询。
❝
个人建议:在金融、法律等强版本敏感场景中,应在RAPTOR外层封装版本控制中间件,自动管理索引路由、冲突检测与用户交互,而非依赖基础索引能力
