Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
西交、清华、西电联合团队
https://arxiv.org/pdf/2511.13201
一、当 RAG 陷入“实体孤岛”
Retrieval-Augmented Generation(RAG)已经成为大模型落地垂直领域的“标配外挂”——把私域文档切成 chunk,做向量索引,回答时召回最相似的片段喂给 LLM,简单粗暴却有效。
但扁平的向量相似度检索天生有两个缺陷:
-
跨 chunk 语义割裂:无法显式建模 chunk 之间的依赖或主题演化,导致召回内容“碎片化”。 -
高阶关系缺失:基于向量的方法只能做“点对点”匹配,难以刻画“多实体联合”的复杂语义。
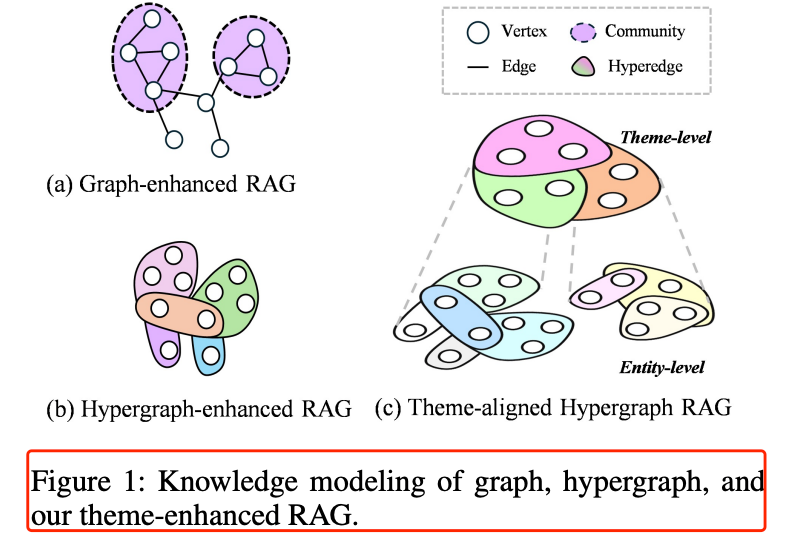
近两年,GraphRAG、LightRAG 等工作把实体级知识图谱搬进 RAG,用“边”把实体串起来,一定程度上缓解了割裂问题。
然而,图谱仍然只关注“成对关系”,对于“多个实体共同构成一个事件/主题”的高阶依赖束手无策,如图 1(a)(b) 所示。
二、双超图 + 两阶段检索,模拟“人脑自上而下”的阅读过程
2.1 总体框架
Cog-RAG 的核心思想一句话概括:先找主题,再找细节,像人一样先快速浏览目录把握主旨,再定位到关键段落精读。
为此,作者设计了两张互补的超图 + 两阶段检索,见图 2。
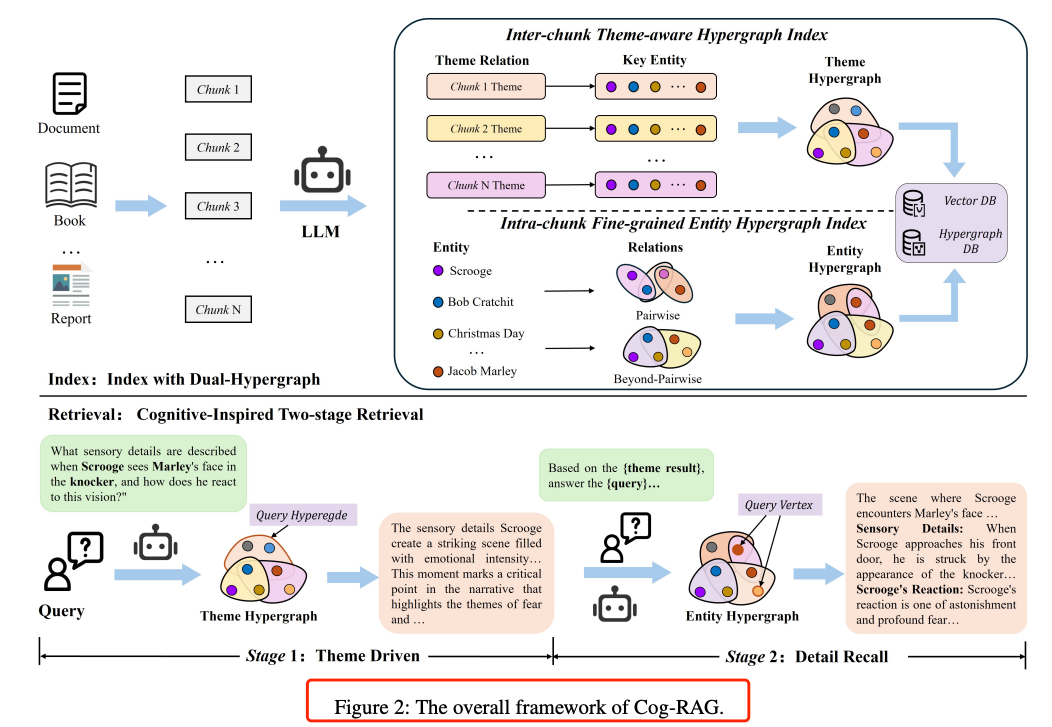
2.2 双超图索引
|
|
|
|
|
|---|---|---|---|
| Theme Hypergraph |
|
|
|
| Entity Hypergraph |
|
|
|
-
构建流程
-
文档滑窗分段 → LLM 抽取主题描述 + 关键实体 → 主题超图 -
每段内部再抽取实体 + 低阶/高阶关系 → 实体超图(低阶=成对,高阶≥3 元组)
-
存储
两类超图分别序列化到向量+结构混合数据库,支持超边/顶点双路检索。 -
关键词自动抽取
LLM 自动把 query 拆成“主题关键词”+“实体关键词”,无需人工规则。 -
主题-实体对齐
用 prompt 让 LLM 判断“哪些实体在主题答案里已被暗示”,避免召回无关实体,减少噪声。 -
Selection-based:LLM 盲评两两对比,算胜率(6 维度 + 总体) -
Score-based:GPT-4o 打分 0-100(6 维度) -
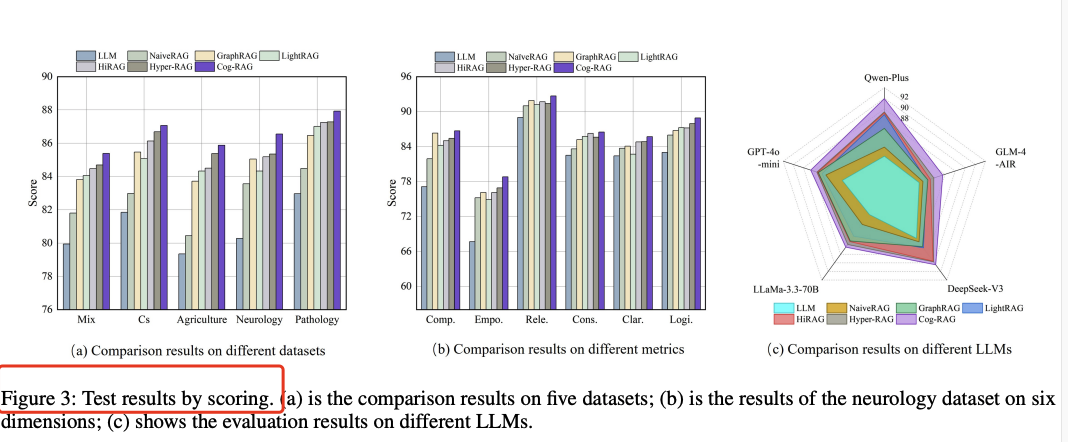
跨 LLM 稳健性:在 GPT-4o、Qwen-Plus、GLM-4-Air、DeepSeek-V3、LLaMA-3.3-70B 上均保持 ≥10% 绝对胜率提升。 -
医学密集领域最亮眼:Neurology 数据集比 Hyper-RAG 提升 **21.0%**,Pathology 提升 **26.4%**。
2.3 认知两阶段检索
|
|
|
|
|
|---|---|---|---|
| Stage-1 主题驱动 |
|
|
|
| Stage-2 细节回溯 |
|
|
|
三、实验:5 个领域、6 个维度、5 种大模型全面碾压
3.1 数据集与评测
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
评测指标
3.2 主要结果
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
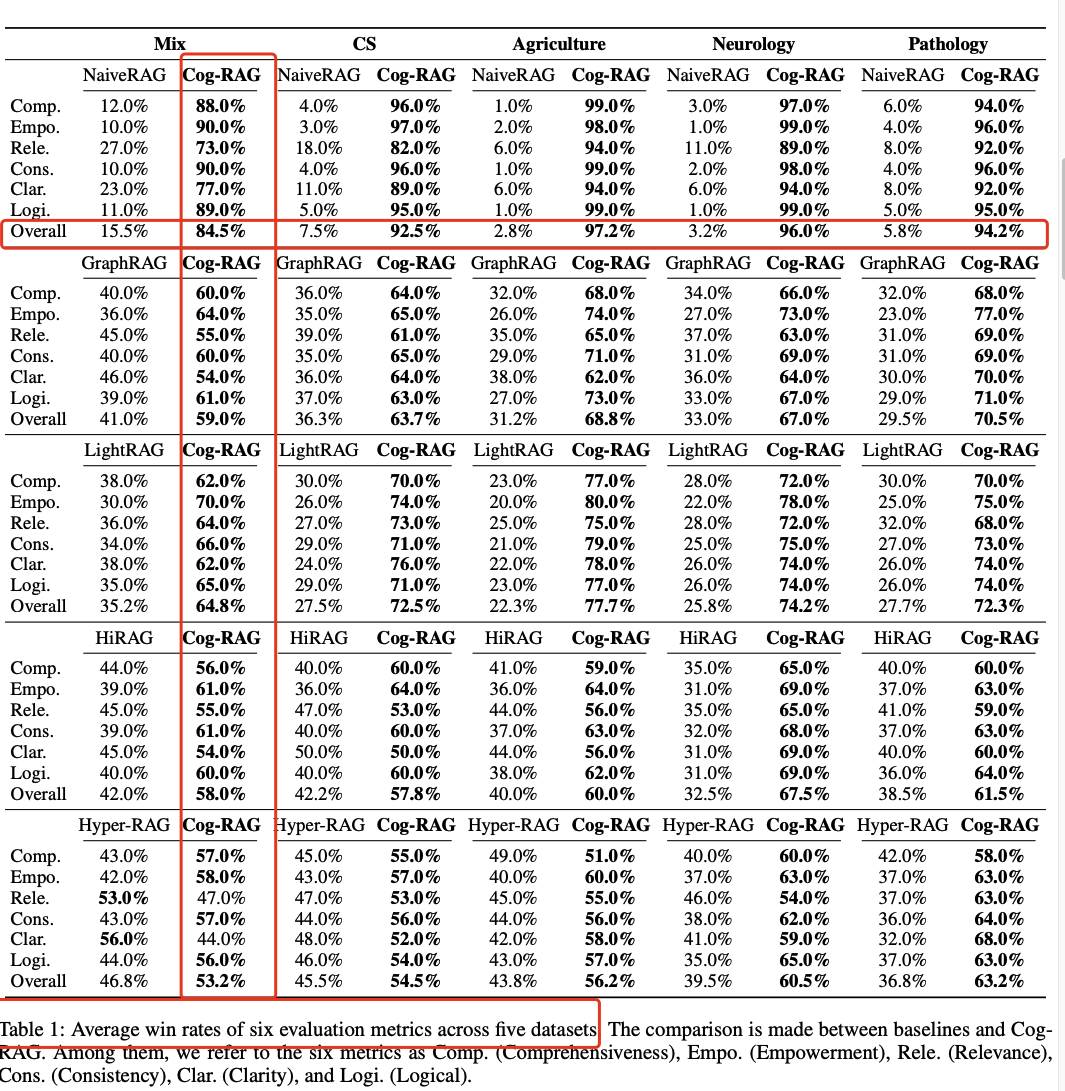
| Cog-RAG | 84.5 % |
❝
表1 节选:Cog-RAG 在 Mix 数据集上总体胜率 84.5%,领先第二名 Hyper-RAG **37.7%**。
3.3 消融实验
❝
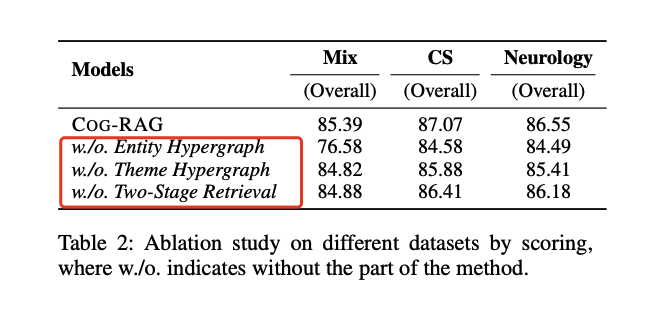
表2 Score-based 消融:实体超图在跨域稀疏场景最敏感;主题超图在域内稠密场景贡献更大。
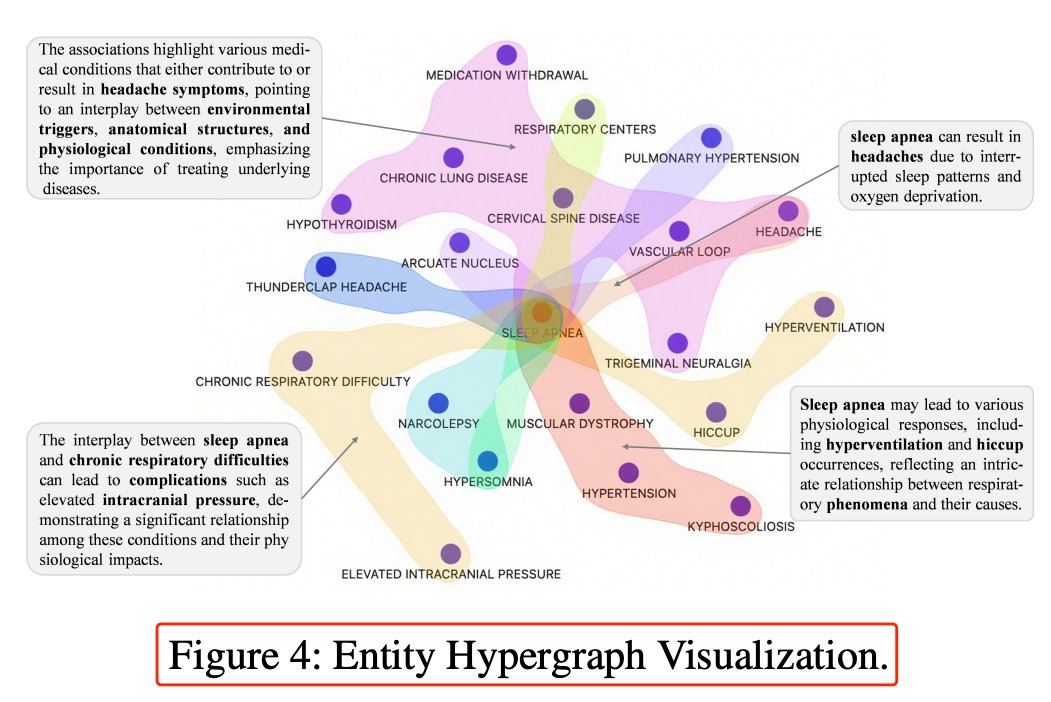
3.4 可视化:一眼看懂高阶依赖