

DeepSeek太秀了,更新了DeepSeek-OCR-2,
又是高立意的一篇文章,验证了了LLM架构有作为VLM编码器的潜力,有远大的理想。
我之前分享过DeepSeek-OCR相关内容,见
-
DeepSeek又开源,这次是OCR模型!附论文解读! -
再谈DeepSeek-OCR的信息压缩论!附DeepSeek-OCR与PaddleOCR实测对比! -
DeepSeek OCR的高OCR准确率,全是幻觉?
咱们今天来看看DeepSeek-OCR-2怎么回事儿,
一些文章介绍什么双向+因果流视觉推理,可能理解起来会比较迷糊,我这里带着大家简单理解,并且通过代码来看其中的细节。
相较于DeepSeek-OCR V1的核心改动就是视觉编码模块。
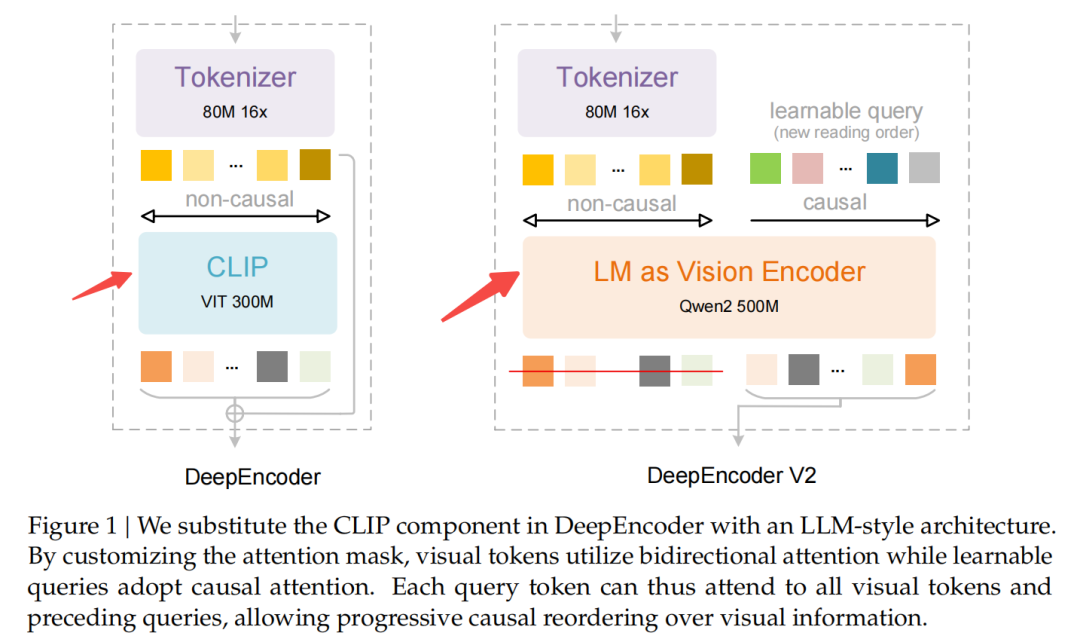
将原始的ViT改成了LM格式,你可以这么理解,ViT就是纯Encoder结构,会让每个视觉Token都彼此看见。
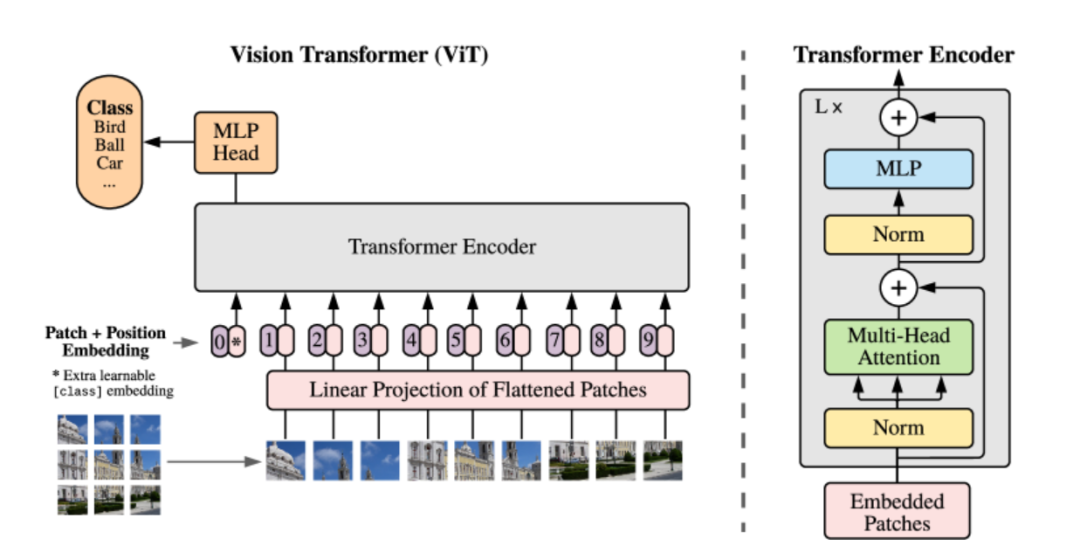
那么就存在了一个问题,就是视觉token其实是2维的,直接Patch会出现信息错乱,因此加入位置编码,
但是这样就相当于看图像,就是必须从左上一直看到右下,按照顺序来阅读,
而人在看图片的时候,会考虑每个模块的语义关联性,会有一定的阅读顺序,当然跟排版页有关。
比如双栏的,如果直接横行阅读,那么就会出现视觉和语义的Gap,或者是竖版文字识别等。
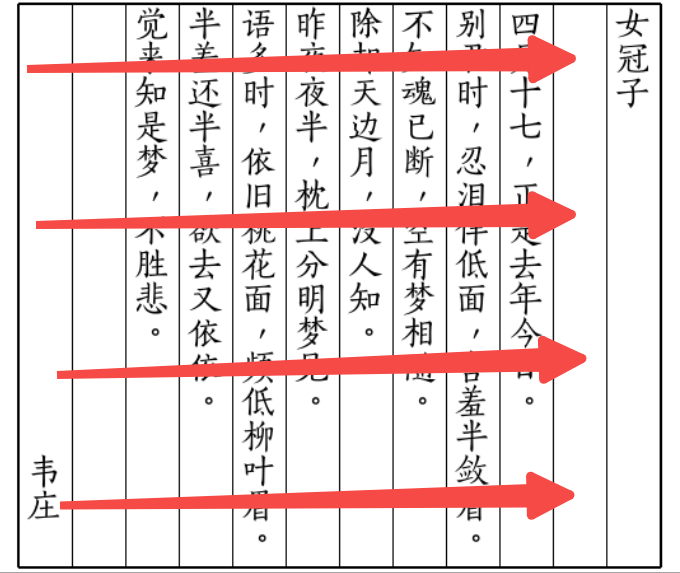
那么怎么做呢,直觉的做法,就是我对视觉Token进行排序就可以了嘛,
事实上DeepSeek-OCR-2也是这么做的。
而对视觉Token排序,可以是encoder-decoder框架也可以是纯decoder框架,
encoder-decoder类似于mBART式交叉注意力结构,但是经过实验发现,视觉 token会因为处在独立编码器内,难以收敛。
而纯decoder,让视觉token前面内容看不到后面内容,也是不合理的,
所以采用prefix LM结构,同时引入可学习query交互,有效压缩视觉信息。
就是你们看到的双流(双向+因果)注意力架构,这不是是首创,不过确实是在编码器里首次使用。
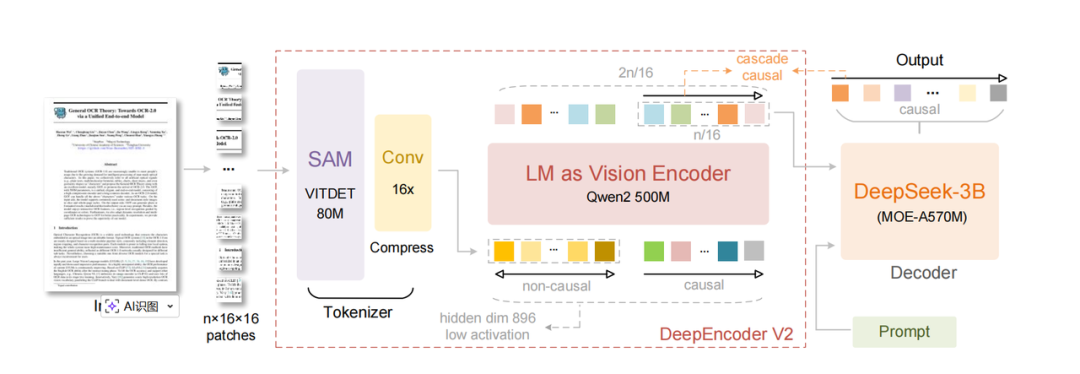
如果你早期做过bert的话,一定知道unilm,当时是三种结构并行,都支持。
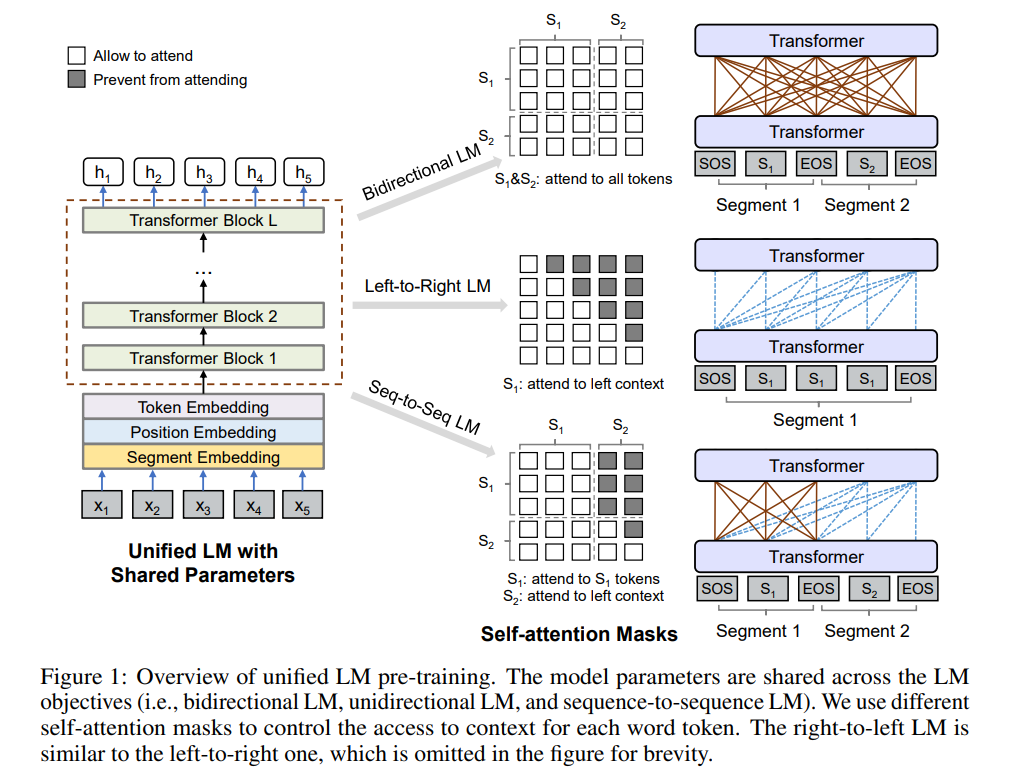
当然很早的ChatGLM1,也是这种prefix LM结构

核心是通过mask,保证前面视觉token是彼此之间相互可以看见的;可学习query token部分,是当前token只能看到前面内容,看不到后面内容的。
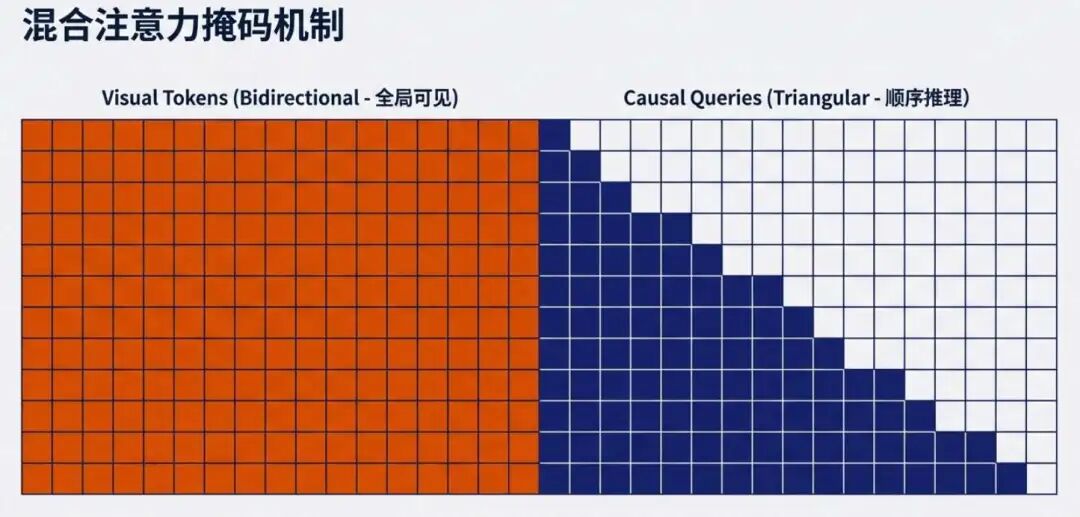
实现可以看代码,
def _create_custom_4d_mask(self, sequence_length, dtype, device, batch_size, token_type_ids, ):
min_dtype = torch.finfo(dtype).min
masks = []
for b in range(batch_size):
mask = torch.full((sequence_length, sequence_length), fill_value=min_dtype, dtype=dtype, device=device)
type_ids = token_type_ids[b]
image_positions = (type_ids == 0).nonzero(as_tuple=True)[0]
text_positions = (type_ids == 1).nonzero(as_tuple=True)[0]
# non-casual
if len(image_positions) > 0:
mask[image_positions[:, None], image_positions] = 0.0
# causal
for i, text_pos in enumerate(text_positions):
if len(image_positions) > 0:
mask[text_pos, image_positions] = 0.0
mask[text_pos, text_positions[:i + 1]] = 0.0
masks.append(mask)
mask = torch.stack(masks, dim=0).unsqueeze(1)
return mask
DeepSeek-OCR-2的核心贡献是验证了LLM作为视觉编码器的可行性。
因为视觉编码利用LM、后面解码器用的也是LM,所以架构统一了,也为原生多模态打下基础。
整个训练流程分三步,
-
Step1:仅训练DeepEncoder-V2部分,尾部加个MLP,预测token内容,训练Vision Tokenizer(DeepEncoder初始化)和LLM编码器(Qwen2-0.5B-base初始化) -
Step2:LLM编码器和DeepSeek-LLM解码器,用于增强可训练Query的表征能力 -
Step3:仅训练DeepSeek-LLM解码器,专注理解DeepEncoder-V2重排序后的视觉Token序列
评测榜单依旧是OmniDocBench v1.5评测,
可以看到在纯端到端上DeepSeek-OCR-2相较于DeepSeek-OCR有很大提升,
但,PaddleOCR-VL依旧是神
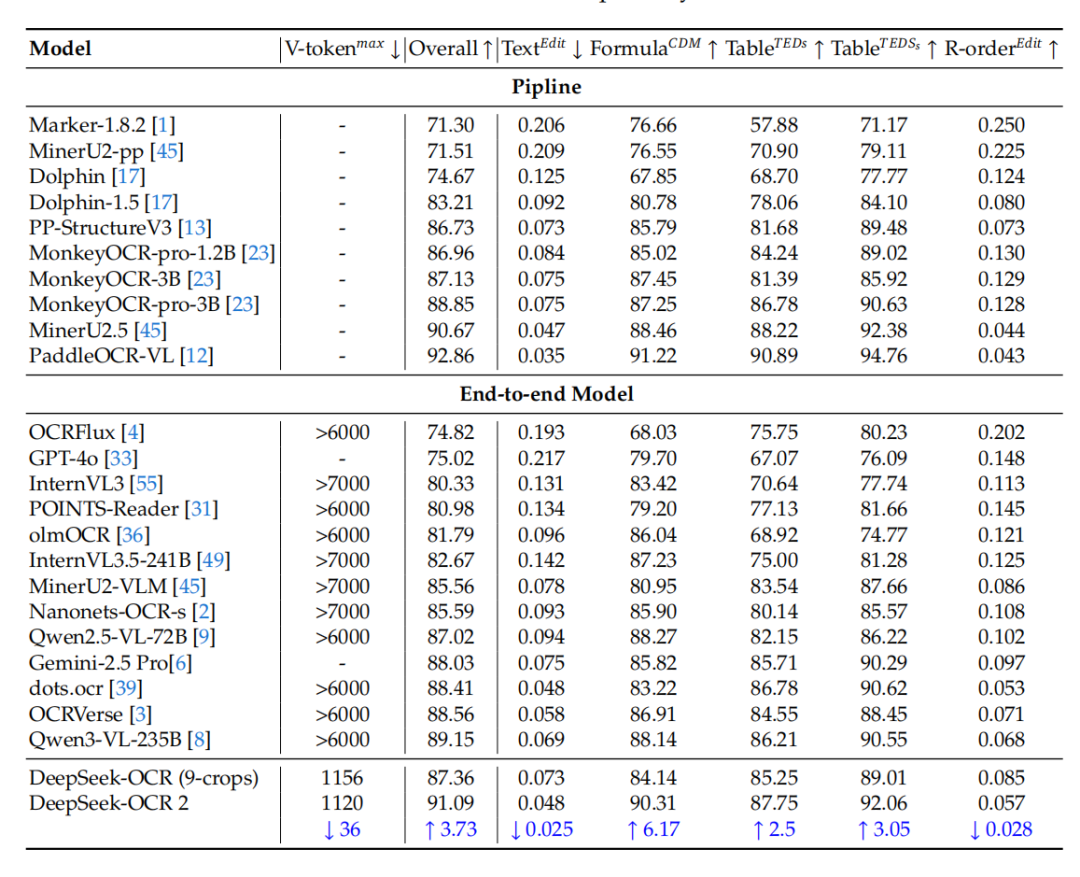
针对视觉模块排序的编辑距离,明显下降

对于DeepSeek自己来说,DeepSeek-OCR-2主要是,
一个是在deeepseek-lm进行问答时,解决用户上传图片的问题,就是先转成文字,在给llm回答
第二个就是给deepseek造预训练数据,
都是在工程上自己使用的。
下面是真实评测,
-
机打内容的OCR识别准确很高 -
手写体简单的识别没有问题,过于连笔的会出错 -
表格识别内容没问题,但是结构会出错 -
生僻字识别较第一版本有提高 -
竖版识别也有提高,这也是排序带来的好处
手写体识别
简单识别,正确。

复杂手写体,会出错。


生僻字形近字识别
识别正确


表格识别
表格的结构会识别错误,文字内容没问题
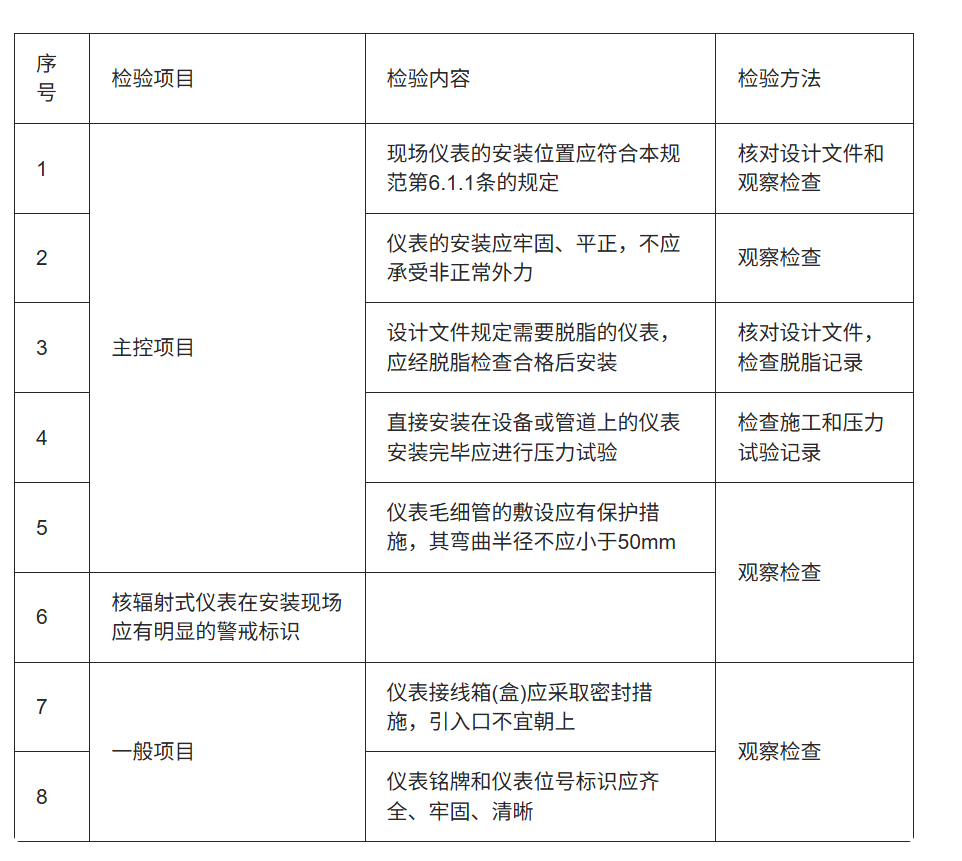
公式识别
简单公式没问题,复杂公式会丢失信息,不知道是不是我图片太小,导致。
最后,
没等来DeepSeek-V4,先等来了DeepSeek-OCR-2,
将LLM作为视觉编码器,
验证了一种可能,
只能说,DeepSeek创新这一块,
没毛病~
今天属实有点卷了,Qwen3-Max-Thinking、K2.5、DeepSeek-OCR-2,
年前还会有,
所以感觉春节大概率要加班了呀~
