

-
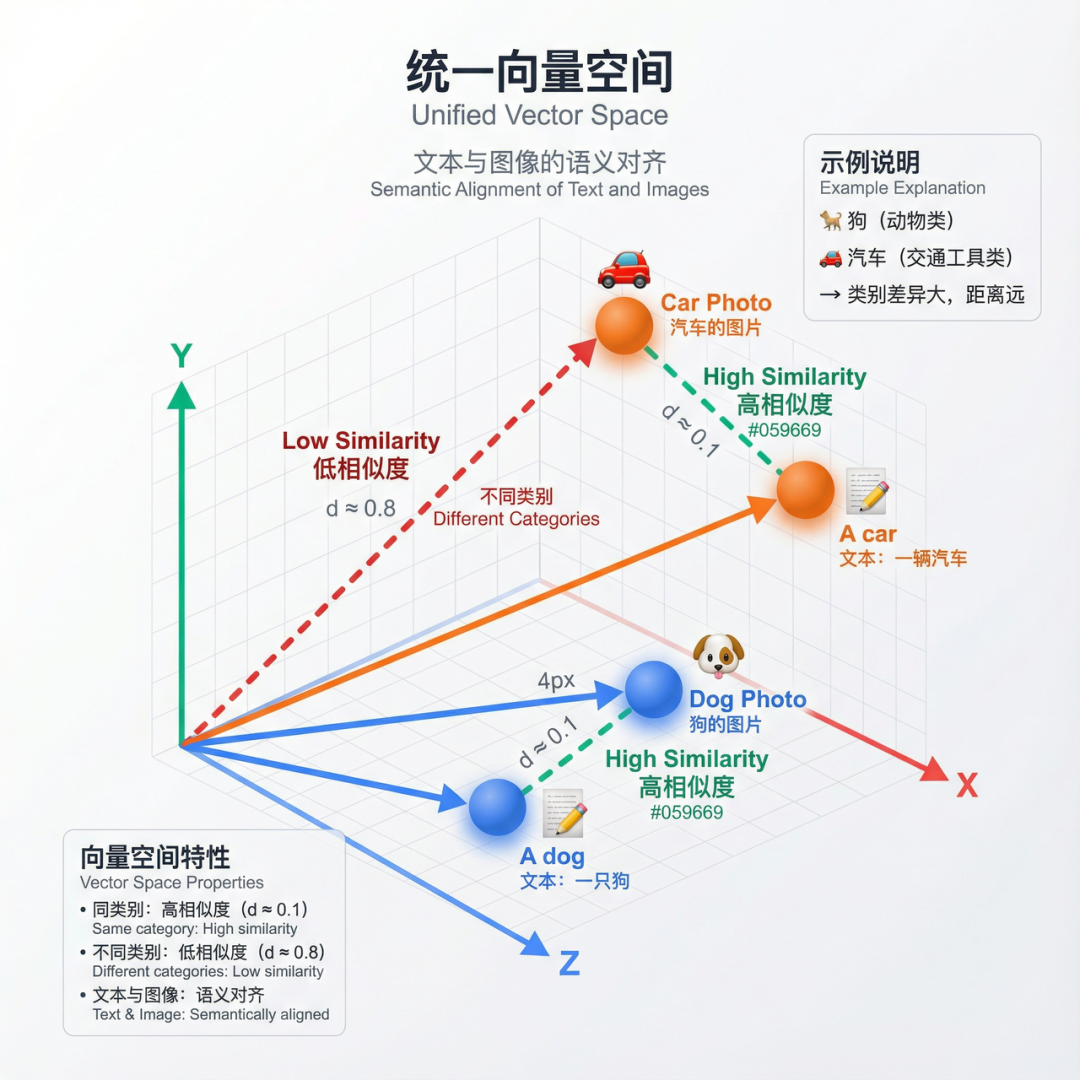
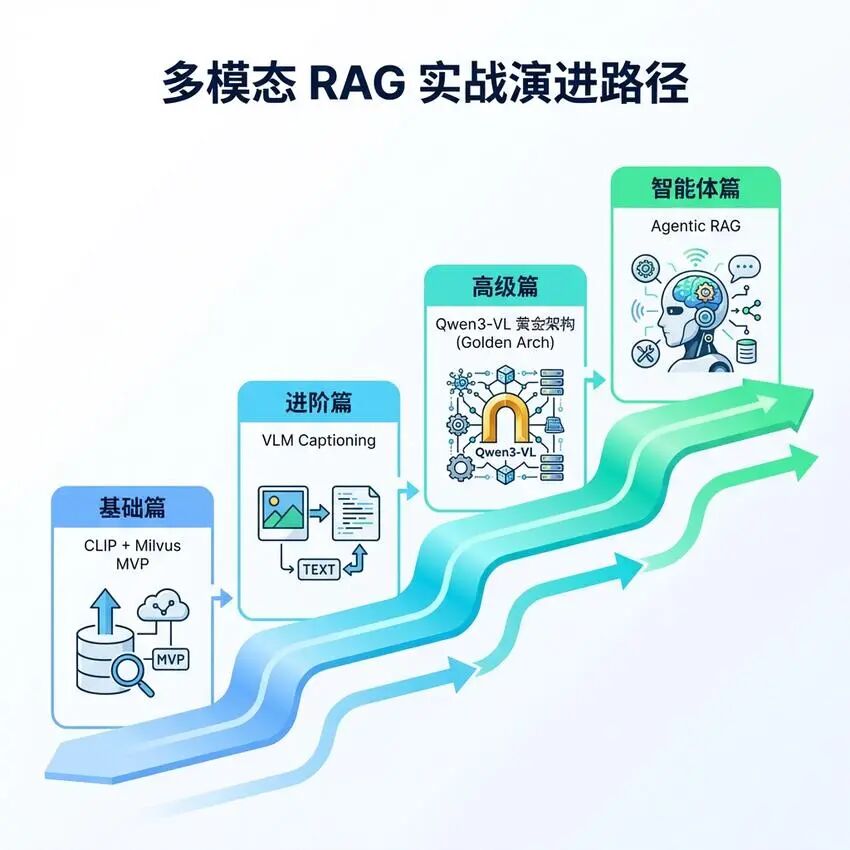
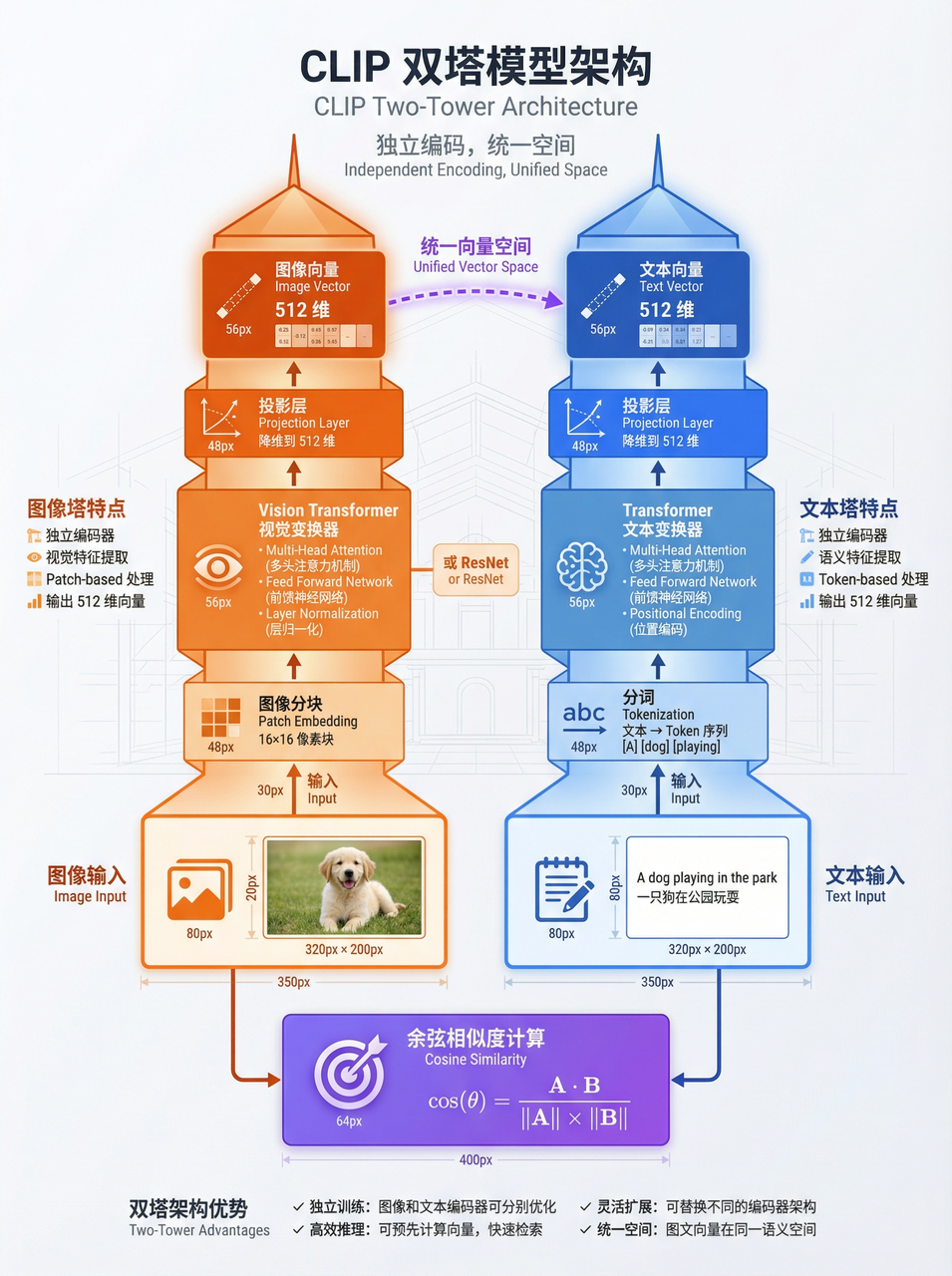
CLIP双编码器方案:通过对比学习将文本和图像映射到统一向量空间 -
VLM Captioning方案:利用视觉语言模型为图像生成文本描述,转化为文本检索问题 -
Qwen3-VL黄金架构:结合Embedding和Reranker的两阶段检索方案 -
Agentic RAG:引入智能Agent,根据查询意图动态选择检索策略
-
文本编码器(Text Encoder):将文本转换为512维向量 -
图像编码器(Image Encoder):将图像转换为512维向量
-
正样本:匹配的图文对,目标是拉近它们的向量距离 -
负样本:不匹配的图文对,目标是推远它们的向量距离
-
离线索引阶段:
-
遍历图片库中的所有图片 -
使用CLIP的图像编码器将每张图片转换为512维向量 -
将向量存入向量数据库(如Milvus)
-
在线检索阶段: -
接收用户的文本查询 -
使用CLIP的文本编码器将查询转换为512维向量 -
在向量数据库中进行相似度搜索 -
返回最相似的图片
-
离线索引阶段:与文搜图相同 -
在线检索阶段:
-
接收用户上传的查询图片 -
使用CLIP的图像编码器将查询图片转换为向量 -
在向量数据库中搜索相似向量 -
返回最相似的图片
-
双索引架构:分别为文本和图像建立独立的向量索引 -
统一查询接口:通过统一的API同时检索文本和图像 -
灵活的Embedding配置:支持配置不同的文本和图像Embedding模型
-
加载文档和图像数据 -
配置文本Embedding模型和图像Embedding模型(如CLIP) -
创建MultiModalVectorStoreIndex实例 -
系统自动将文本和图像分别编码并存储
-
创建MultiModalRetriever -
输入查询(文本或图像) -
系统自动选择对应的编码器处理查询 -
返回相关的文本节点和图像节点
-
高性能:支持十亿级向量的毫秒级检索 -
多种索引类型:IVF_FLAT、HNSW等,可根据场景选择 -
分布式架构:支持水平扩展
-
配置Milvus连接参数(URI、collection名称等) -
创建MilvusVectorStore实例 -
将其作为存储后端传入MultiModalVectorStoreIndex -
索引数据自动持久化到Milvus
-
文本Collection:存储文本向量,维度由文本Embedding模型决定 -
图像Collection:存储图像向量,维度为512(CLIP标准输出)
-
端到端简洁:无需额外的图像描述生成步骤 -
真正的跨模态理解:直接学习图文语义对齐 -
检索速度快:向量检索复杂度低
-
语义理解深度有限:CLIP的训练数据以简短描述为主,对复杂语义理解不足 -
细粒度检索能力弱:难以处理"图片中红色物体的左边是什么"这类细节查询 -
向量维度固定:512维可能无法充分表达复杂图像的全部信息

-
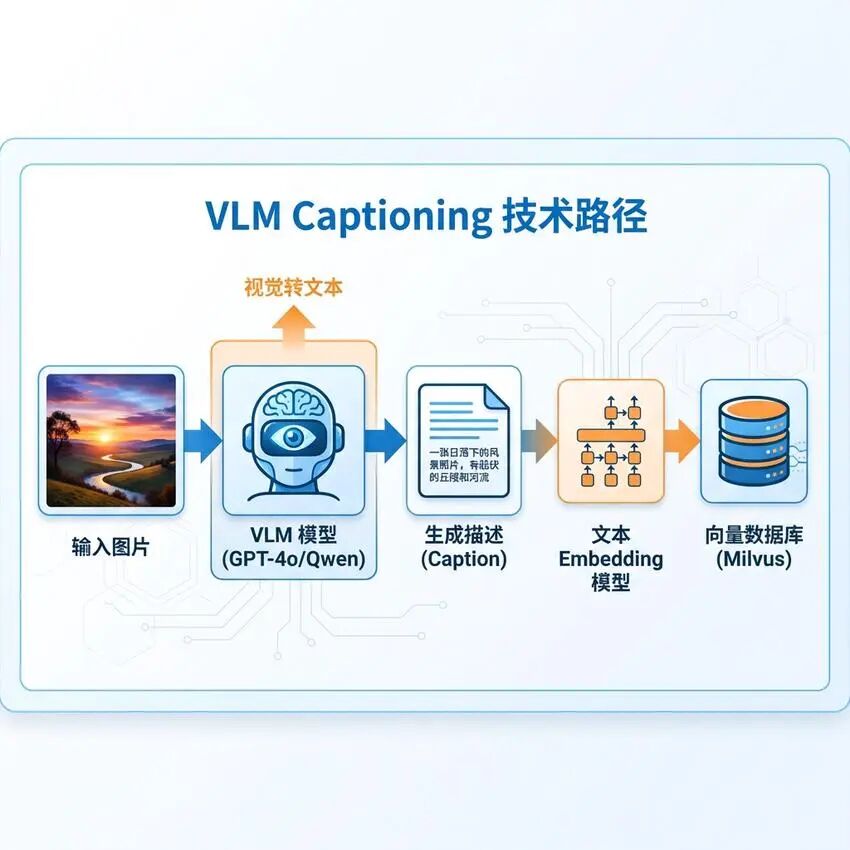
图像描述生成:使用视觉语言模型(如GPT-4o、Qwen-VL-Max)为每张图片生成详细的文本描述 -
文本索引构建:将生成的描述文本进行Embedding,存入向量数据库 -
文本检索:用户查询与图片描述进行文本相似度匹配 -
结果映射:将匹配的描述映射回对应的图片
-
GPT-4o:OpenAI的多模态旗舰模型,描述质量高但成本较高 -
Qwen-VL-Max:阿里云的视觉语言模型,性价比较高 -
Claude 3.5 Sonnet:Anthropic的多模态模型,理解能力强
-
全面性要求:描述图片中的所有重要元素 -
结构化输出:按照主体、背景、细节等层次组织 -
语义丰富性:包含颜色、位置、动作、情感等多维度信息 -
检索友好性:使用用户可能搜索的关键词
-
词频(TF):关键词在文档中出现的次数越多,相关性越高 -
逆文档频率(IDF):在越少文档中出现的词,区分度越高 -
文档长度归一化:避免长文档获得不公平的优势
-
向量检索器:基于语义相似度检索 -
BM25检索器:基于关键词匹配检索 -
RRF融合算法:使用Reciprocal Rank Fusion合并两路结果
-
语义理解:向量检索捕捉语义相似性 -
精确匹配:BM25确保关键词不被遗漏 -
互补增强:两种方法的优势互补,提升整体召回率
-
语义理解深度:VLM可以生成非常详细的图片描述,包含丰富的语义信息 -
复用成熟技术:可以直接使用成熟的文本检索技术栈 -
可解释性强:检索结果可以通过描述文本解释为什么匹配
-
信息损失:图像转文本过程中不可避免地丢失部分视觉信息 -
成本较高:需要为每张图片调用VLM生成描述 -
不支持图搜图:用户上传图片后,需要先生成描述再检索,体验不够直接
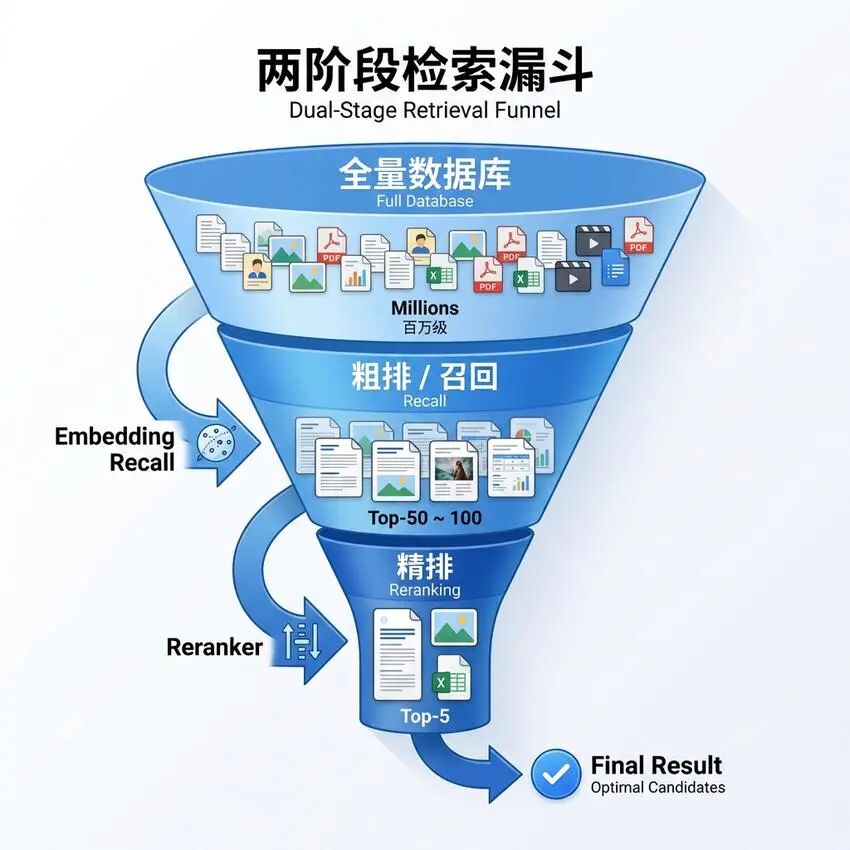
-
速度快:向量检索复杂度低 -
召回量大:通常召回Top-K(如100条)候选 -
容错性高:宁可多召回,不可漏掉相关结果
-
理解深度:Reranker可以同时看到查询和候选,进行交叉注意力计算 -
排序精准:输出精确的相关性分数 -
计算量可控:只处理第一阶段召回的少量候选
-
原生多模态:同一个模型可以处理文本和图像 -
统一向量空间:文本和图像编码到同一个高维空间 -
指令感知:支持通过指令控制Embedding的生成方式
-
继承LlamaIndex的BaseEmbedding类 -
实现文本编码方法:调用Qwen3-VL处理文本 -
实现图像编码方法:调用Qwen3-VL处理图像 -
确保输出向量维度一致
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
将查询和候选拼接成特定格式的输入 -
调用Qwen3-VL模型进行推理 -
从模型输出中提取相关性分数 -
根据分数对候选进行排序
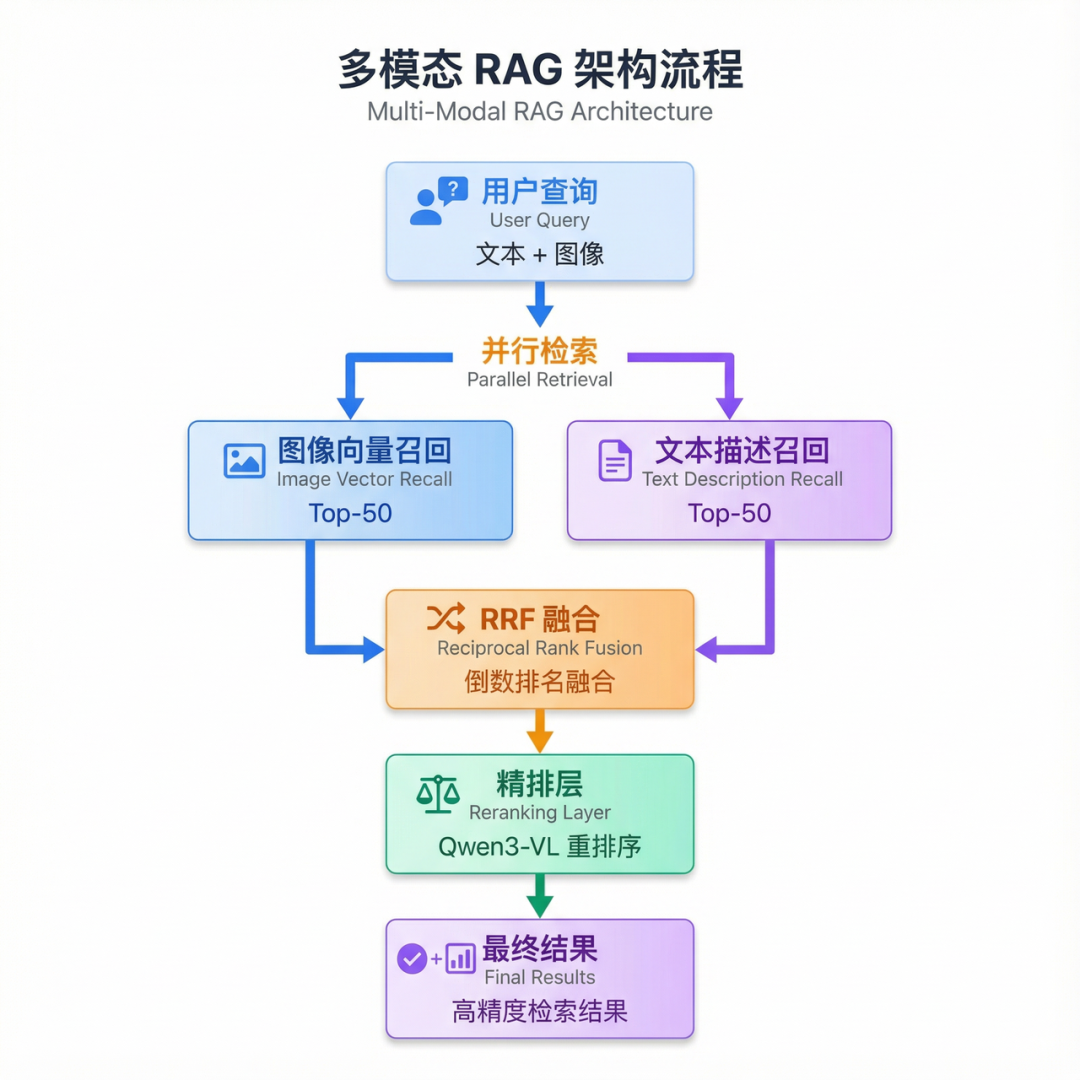
-
查询处理:接收用户的文本或图像查询 -
Embedding编码:将查询编码为向量 -
向量检索:在向量数据库中检索Top-K候选(如100条) -
Reranker精排:对候选集进行精细排序 -
结果返回:返回Top-N最相关结果(如10条)
-
召回阶段:追求高召回率,宁可多召回 -
精排阶段:追求高精度,确保排序准确 -
参数调优:K和N的选择需要根据实际场景调整
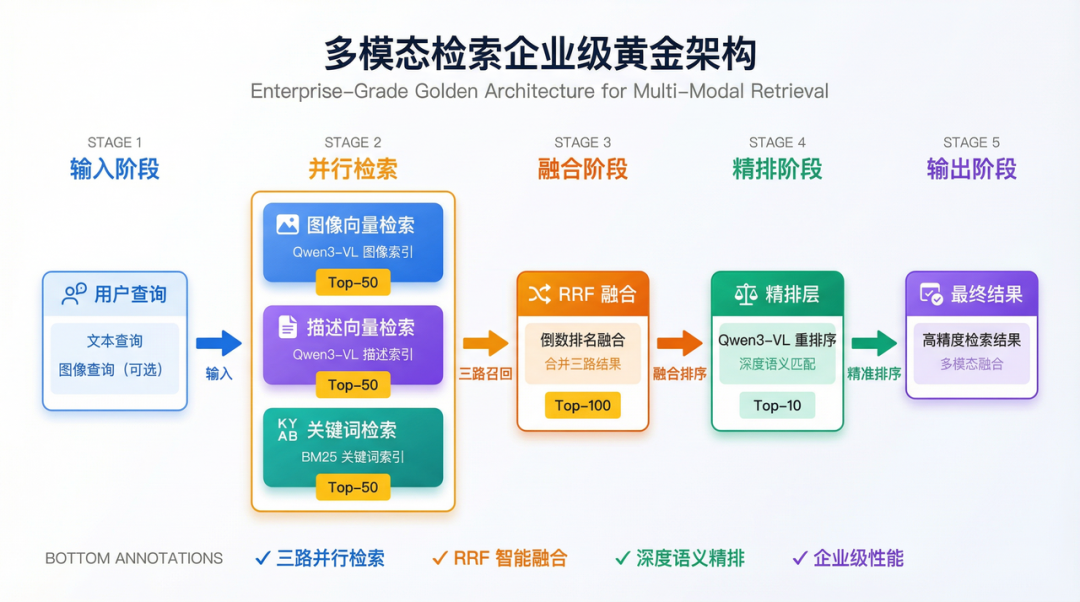
-
向量检索路:基于Qwen3-VL Embedding的语义检索 -
BM25检索路:基于图片描述的关键词检索 -
融合层:使用RRF算法合并两路结果 -
精排层:使用Qwen3-VL Reranker对融合结果精排
-
支持同时查询文本和图像Collection -
支持配置不同的检索参数 -
支持结果的合并与去重 -
与LlamaIndex的Retriever接口兼容
-
检索质量高:两阶段架构兼顾召回率和精度 -
原生多模态:无需图像转文本,保留完整视觉信息 -
灵活可扩展:可以根据需求调整各阶段参数
-
系统复杂度高:需要维护多个模型和组件 -
计算成本较高:Reranker阶段需要额外的模型推理 -
部署要求高:需要GPU资源支持大模型推理

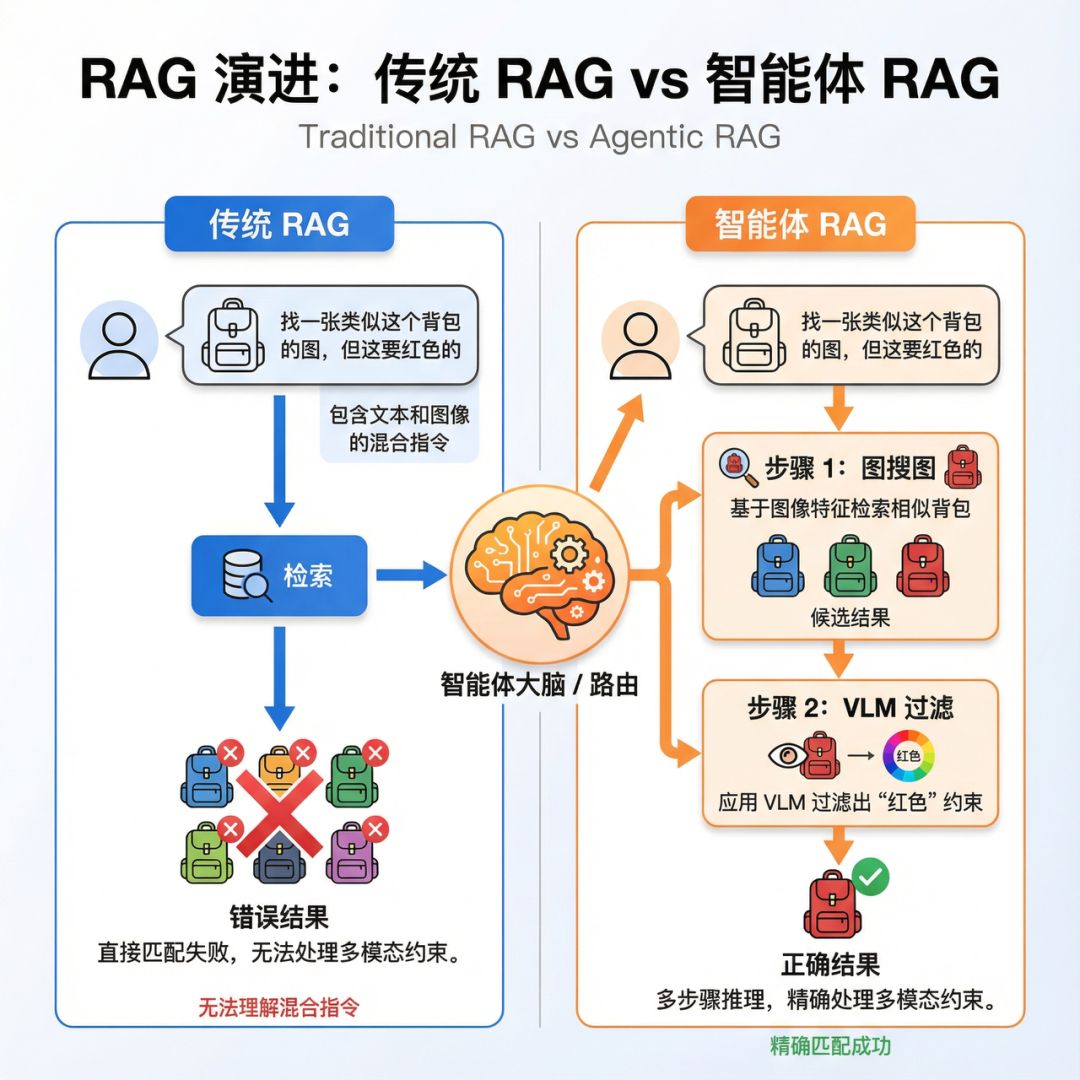
-
流程固定:无论什么查询都走相同的检索流程 -
无法迭代:一次检索不满意无法自动重试 -
缺乏推理:无法根据检索结果进行逻辑推理
-
动态决策:根据查询意图选择最合适的检索策略 -
迭代优化:检索结果不满意时自动调整策略重试 -
推理能力:可以对检索结果进行分析和推理
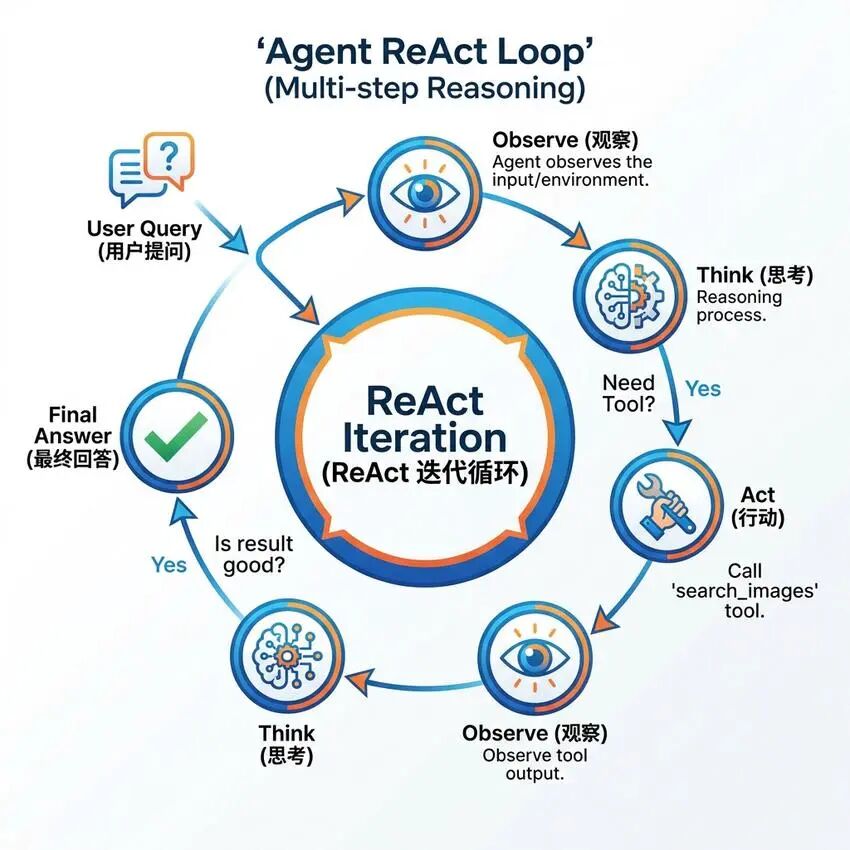
-
Observe(观察):Agent观察当前状态,包括用户查询、已有的检索结果等 -
Think(思考):Agent分析当前状态,决定下一步应该采取什么行动 -
Act(行动):Agent执行决定的行动,如调用检索工具、生成回答等
-
Agent认为已经收集到足够的信息 -
达到最大迭代次数 -
用户主动终止
-
文搜图工具:输入文本查询,返回相关图片 -
图搜图工具:输入图片,返回相似图片 -
混合检索工具:同时使用向量和BM25检索 -
精排工具:对候选结果进行Reranker精排
-
清晰说明工具的功能 -
明确输入输出格式 -
给出使用场景示例 -
说明与其他工具的区别
-
LLM:作为Agent的"大脑",负责推理和决策 -
Tools:Agent可以调用的工具集合 -
Memory:存储对话历史和中间状态 -
Prompt:指导Agent行为的提示词
-
定义检索工具,封装各种检索能力 -
配置LLM,选择合适的大语言模型 -
创建Agent,绑定工具和LLM -
运行Agent,处理用户查询
-
路由Agent:分析查询意图,决定调用哪个专门Agent -
文搜图Agent:专门处理文本到图像的检索 -
图搜图Agent:专门处理图像到图像的检索 -
问答Agent:基于检索结果生成回答
-
串行模式:Agent按顺序执行,前一个的输出作为后一个的输入 -
并行模式:多个Agent同时执行,结果合并 -
层级模式:主Agent协调多个子Agent
-
智能化程度高:能够理解复杂查询意图 -
自适应能力强:可以根据情况动态调整策略 -
可扩展性好:通过添加工具扩展能力
-
延迟较高:多轮推理增加响应时间 -
成本较高:每次推理都需要调用LLM -
可控性降低:Agent的行为不完全可预测
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
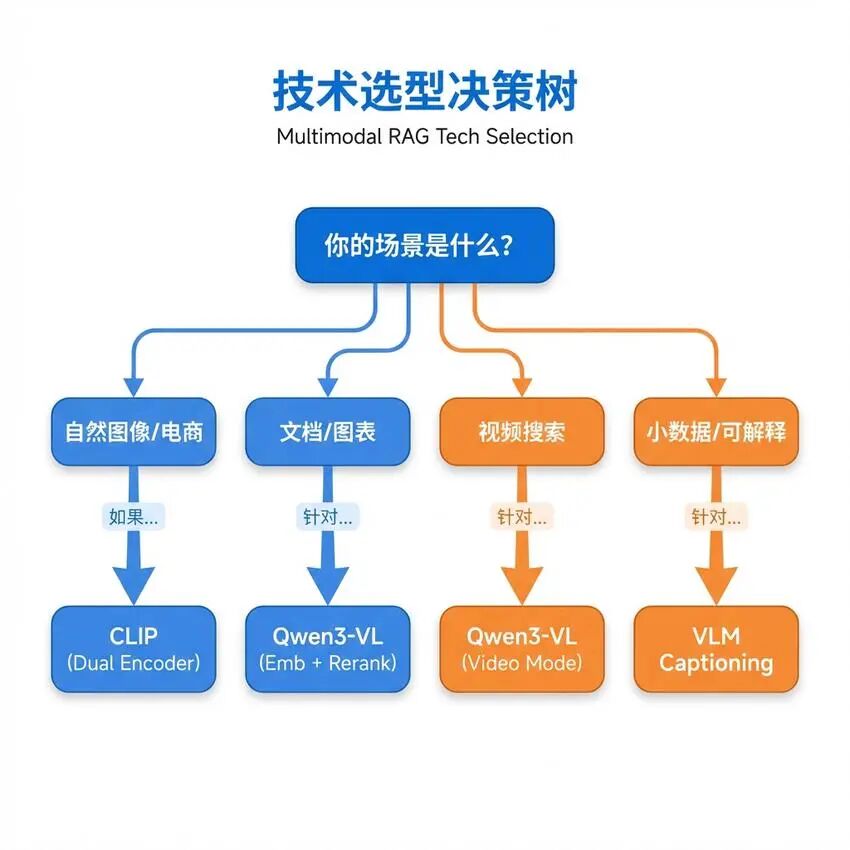
海量商品图片(百万级以上) -
用户查询相对简单(如"红色连衣裙") -
对响应速度要求高
-
CLIP能够处理简单的商品描述查询 -
向量检索速度快,满足高并发需求 -
实现成本低,易于维护
-
图片数量中等(万级到十万级) -
查询涉及专业术语和复杂描述 -
对检索精度要求极高
-
VLM可以生成专业的医学描述 -
混合检索确保专业术语精确匹配 -
可解释性强,便于医生验证结果
-
需要同时支持文搜图和图搜图 -
用户可能上传参考图片寻找相似素材 -
对视觉相似度要求高
-
原生支持图搜图,无需额外处理 -
两阶段检索保证检索质量 -
Reranker提升视觉相似度排序精度
-
用户查询复杂多变 -
可能需要多轮交互 -
需要结合图片和文本生成回答
-
Agent可以理解复杂查询意图 -
支持多轮交互和迭代检索 -
可以整合多种检索策略
-
使用CLIP + 简单向量数据库 -
快速搭建MVP验证业务价值 -
收集用户反馈和真实查询数据
-
引入VLM Captioning增强语义理解 -
添加BM25混合检索提升召回率 -
根据数据特点调优检索参数
-
引入Reranker提升排序精度 -
考虑使用Qwen3-VL等更强的多模态模型 -
建立评估体系持续优化
-
引入Agent实现智能检索 -
支持复杂查询和多轮交互 -
持续迭代优化用户体验
-
CLIP方案:通过对比学习实现跨模态检索,简单高效,适合入门 -
VLM Captioning:将图像转为文本,复用成熟的文本检索技术 -
Qwen3-VL黄金架构:Embedding + Reranker两阶段检索,兼顾效率和精度 -
Agentic RAG:引入智能Agent,实现动态决策和迭代优化
-
从简单开始:先用简单方案验证业务价值 -
数据驱动:根据实际数据特点选择方案 -
渐进演进:随着需求增长逐步升级技术栈 -
成本效益:在效果和成本之间找到平衡点
-
更强的跨模态理解:模型能够理解更复杂的图文关系 -
更高效的检索:在保持精度的同时进一步提升速度 -
更智能的Agent:能够处理更复杂的多模态任务 -
更低的使用门槛:框架和工具链的持续完善
