

目录:
📖 1. 引言
你是否经历过这样的痛苦:想用AI做个视频,得先去A软件生成图片,再去B网站生成视频,最后还得在C软件里剪辑配音?现有的AI模型要么只懂生成,要么只懂理解,就像一个个“偏科生”。
今天我们要介绍的这篇论文 《UniVA: Universal Video Agent》,就是要解决这个问题。它提出了一个开源的、全能的视频智能体,不仅能听懂你的模糊指令,还能像真人导演一样,帮你策划、生成、剪辑、理解视频,一站式搞定!
💡 2.UniVA四个核心要点
要点一:代理式创作,它是“有脑子”的合作伙伴,而不只是工具
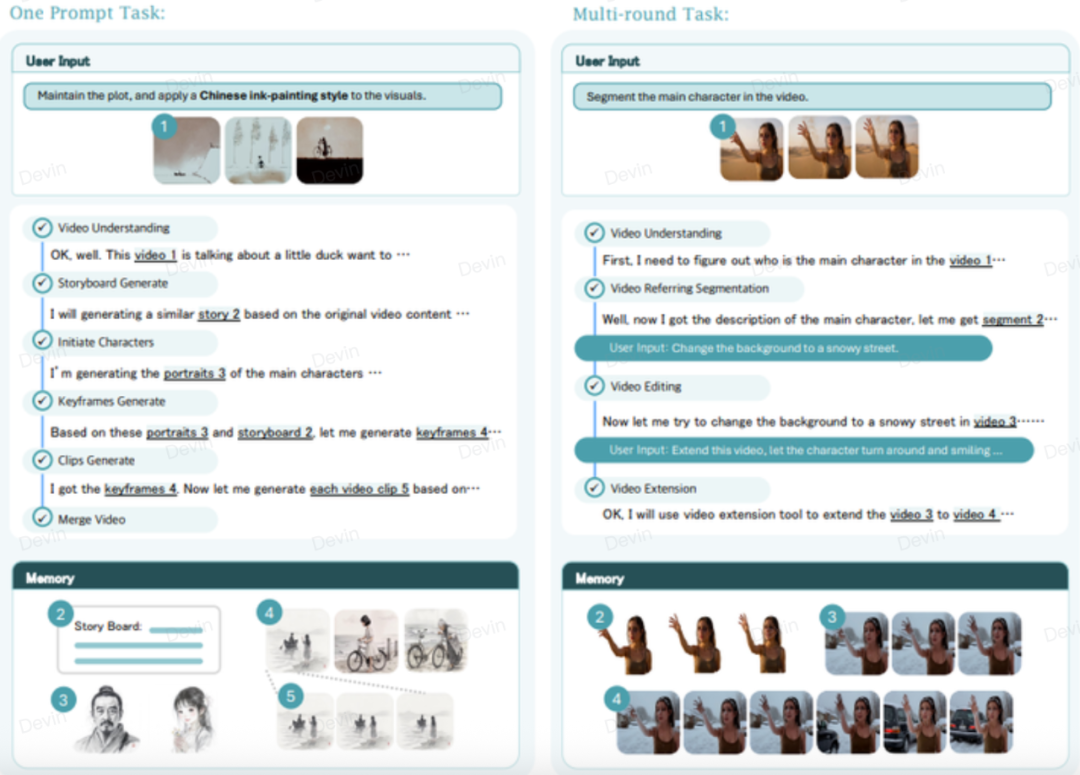
生活案例: 以前用AI,你得像“程序员”一样写精准的Prompt。用UniVA,就像跟摄影师聊天:“帮我拍个复古风的猫咪视频,要那种慵懒的感觉。” UniVA会反问你:“是80年代港风还是胶片感?背景要不要加点落日?” 它会记住你的喜好,理解你的潜台词,甚至主动提建议。
专业解读: 论文提出了多轮共创(Multi-round co-creation)和隐式意图理解(Implicit intent reading)。它拥有“三级记忆”,能通过上下文补全你没说出口的需求。
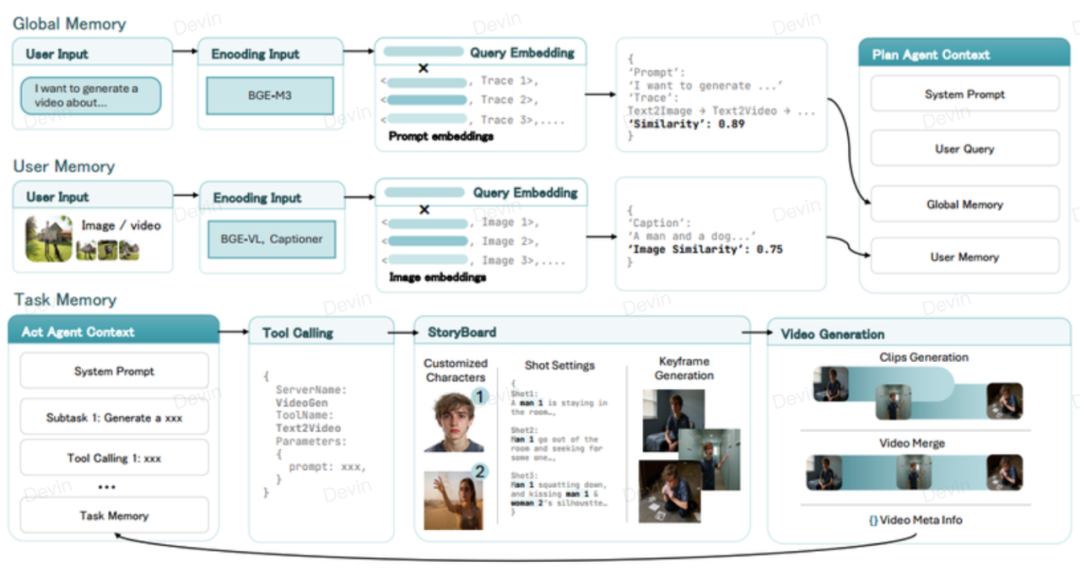
要点二:双核驱动——计划-执行双智能体架构
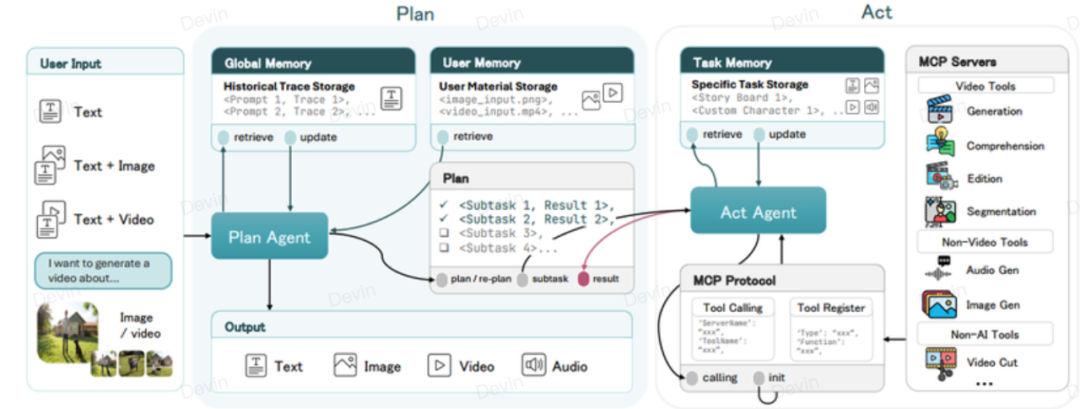
生活案例: 拍电影时,导演负责想剧本分镜,摄影师负责具体拍摄。UniVA内部也有这样的分工:Plan Agent(策划智能体) 是“军师”,负责把你的那一句话拆解成详细的执行步骤;Act Agent(执行智能体) 是“大将”,负责一步步去调用各种工具把视频做出来。
专业解读: 这是UniVA的核心架构。Planner将目标分解为结构化的计划序列,Actor通过MCP(Model Context Protocol)协议调用各种模块化工具(生成、剪辑、追踪等)来执行。
要点三:全能视频生产,从“短视频”到“长电影”的进化
我们简单看下案例,Input prompt:
生活案例: 现在的视频AI大多只能生成3-5秒的片段,人物还容易变脸。UniVA能处理长篇复杂的叙事,不仅能生成高清视频,还能保证主角在不同镜头里长得一样(一致性),甚至能精细到“把第5秒路人的衣服换个颜色”。
专业解读: UniVA建立了一个通用视频工厂(Universal Video Fabric),统一处理文本、图像、实体和视频流。支持超长、细粒度的编辑和基于理解的生成,解决了长视频叙事中的连贯性难题。
要点四:无限扩展的“技能树”
生活案例: 手机只能装出厂自带的APP?太落后了!UniVA就像一个开放的应用商店。通过MCP协议,它今天可以“安装”Midjourney绘图,明天可以“安装”Runway生成视频。它不重复造轮子,而是把全世界最好的AI工具都连接起来,听你指挥。
专业解读: 不同于封闭的商业软件,UniVA是面向开源的下一代视频代理。它利用MCP (Model Context Protocol) 标准接口,能够轻松集成社区开发的各种图像、视频、音频处理工具,构建真正的通用视频生态。
3. UniVA行业定位:为什么说是“下一代”?
-
第一代 (单点工具):如Sora、Runway。缺点只能生成素材,用户还得自己写Prompt、自己剪辑,像是在“买菜”。
-
第二代 (特定流程):如StoryDiffusion。缺点只能做特定任务(如漫画转视频),不够灵活。
-
UniVA (通用智能体):全能、开源、懂你。它不是替代某个模型,而是指挥所有模型的“超级大脑”。它负责全流程理解->策划->执行,让视频创作真正实现自动化。
4. 结尾
UniVA的出现,标志着视频AI正在从“玩具”走向“生产力工具”。它不仅开源,还通过MCP协议让全世界的开发者都能为它增加新技能。未来,也许每个人都能拥有自己的“贾维斯”导演。
