
本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
一、多模态RAG面临的困难
-
知识图谱(KGs)通过将实体及其关系以结构化形式编码,为多跳推理和精准召回上下文提供了可行性。
-
但是在多模态资源中,实体之间的关系非常复杂,导致检索输出碎片化和持续的幻觉问题。
-
并且知识图谱的构建和维护需要大量人工劳动,将其与向量搜索和 LLM 提示相结合会增加大量的工程开销。
-
现有的知识图谱与 RAG 混合框架面临着可扩展性瓶颈,需要大量的手动调整以保持知识更新时的鲁棒性。
二、DO-RAG的解决方案
DO-RAG 的核心思想是将非结构化的、多模态的领域数据转换为动态的、多级的知识图谱,并通过结合图遍历和语义向量搜索来检索结构化的、上下文丰富的信息。
在生成阶段,通过基于事实的细化步骤验证输出,减少幻觉现象,从而提高答案的事实准确性。

DO-RAG 的系统架构包括四个关键阶段:
-
多模态文档抽取和分块
-
多级实体 – 关系提取以构建知识图谱
-
结合图遍历和密集向量搜索的混合检索,以及用于生成基于事实的
-
与用户对齐的答案的多阶段生成管道。
2.1 多模态文档抽取和分块
-
首先,将异构领域数据(如日志、技术手册、图表和规范)解析为有意义的块单元。
-
这些块存储在启用 pgvector 的 PostgreSQL 实例中,同时保留其向量嵌入。
-
同时,基于代理的链式思维实体提取管道将文档内容转换为结构化的多模态知识图谱(MMKG),捕捉系统参数、行为和依赖关系等多粒度关系。
2.2 多级知识图谱构建
性。
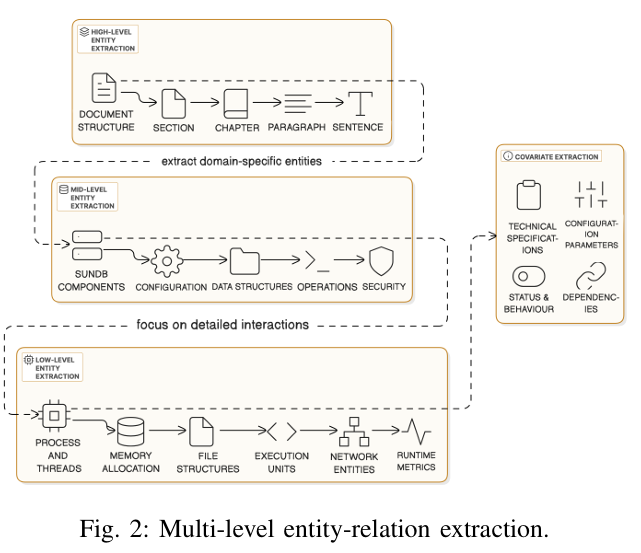
DO-RAG 通过设计和实现一个分层的基于代理的提取管道,自动构建和更新知识图谱,捕捉实体、关系和属性。
该管道包括四个专门的代理,分别在不同的抽象级别上运行:
-
高级代理:识别结构元素,例如章节、段落等。
-
中级代理:提取特定领域的实体,如系统组件、API 和参数。
-
低级代理:捕获细粒度的操作关系,如线程行为或错误传播。
-
协变量代理:为现有节点附加属性,例如默认值、性能影响等。
通过这种方式,DO-RAG 能够从文本、表格、代码片段和图像等多种模态的文档中提取结构化知识,构建动态的知识图谱。
2.3 混合检索和查询分解
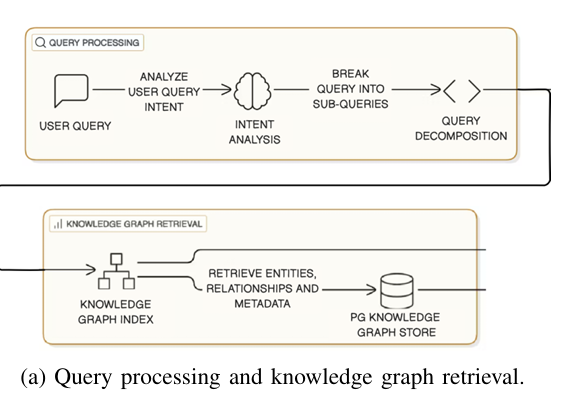
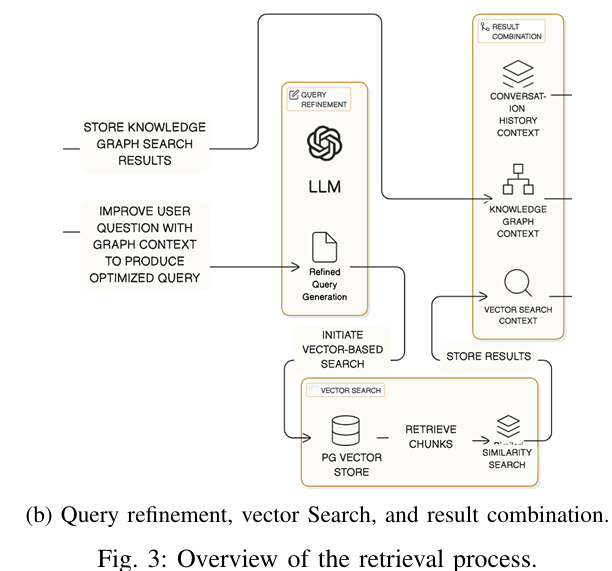
在用户提交问题时,DO-RAG 使用基于 LLM 的意图分析器对用户查询进行结构化分解,生成子查询以指导从知识图谱和向量存储中的检索。
-
首先,通过语义相似性从知识图谱中检索相关节点,然后执行多跳遍历来扩展检索范围,生成结构化的、特定领域的上下文。
-
接着,利用图谱派生的上下文重写原始查询,使其更加具体和明确。
-
最后,将重写的查询向量化,用于从向量数据库中检索语义相似的文本片段。
所有相关的信息源(原始查询、重写后的查询、知识图谱上下文、检索到的文本片段和用户交互历史)被整合到一个统一的提示结构中,并传递给生成管道。
2.4 基于事实的答案生成和幻觉缓解
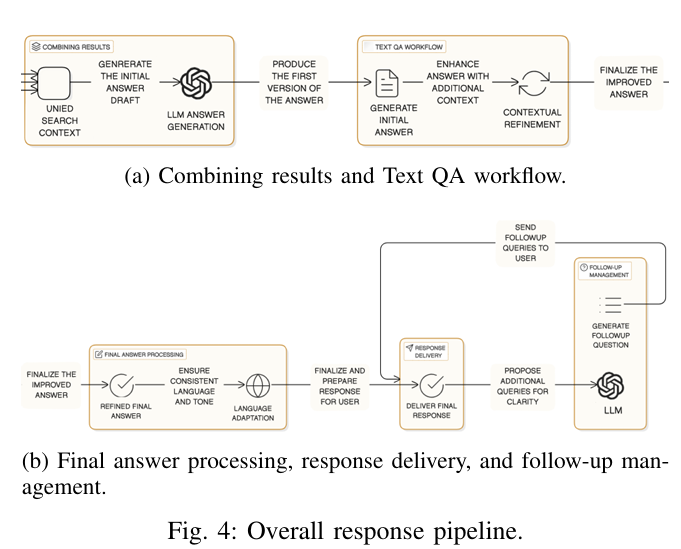
在生成阶段,DO-RAG 采用分阶段的提示策略。
-
初始的简单提示,指示 LLM 仅根据检索到的证据回答问题,并明确避免未经支持的内容。
-
输出经过细化提示,重新构建和验证答案,然后通过压缩阶段确保连贯性和简洁性。
-
此外,DO-RAG 还会根据细化后的答案生成后续问题,基于整体对话上下文提出下一步的查询,增强用户参与度并支持多轮交互。
-
如果系统无法找到足够的证据,模型将返回“我不知道”,以保持可靠性并防止幻觉。

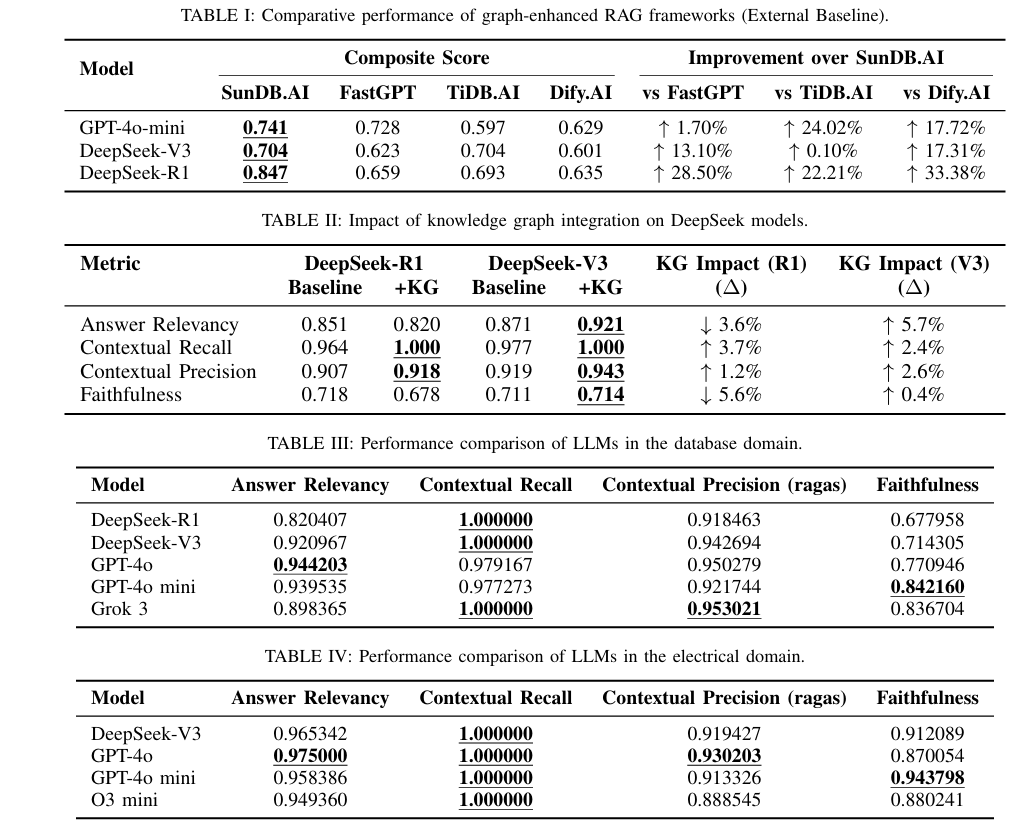
三、一些细节
3.1 知识图谱构建
-
多模态文档摄取:
-
系统接收包含文本、表格和图像的异构领域数据,将其标准化并分割为有意义的块单元。
-
同时,保留元数据,如源文件结构、章节层次和布局标签,以便于追溯。
-
实体 – 关系提取:
-
通过多代理管道提取结构化知识
-
高级代理识别文档的结构元素
-
中级代理提取特定领域的实体
-
低级代理捕获细粒度的操作关系
-
协变量代理为现有节点附加属性
-
每个代理的输出被整合到动态知识图谱中,节点代表实体,边代表关系,权重表示置信度。
-
去重与优化:
-
通过计算新实体嵌入与现有实体嵌入之间的余弦相似性,避免知识图谱中的冗余。
-
此外,合成概要节点以对相似实体进行分组,降低图谱复杂性。
3.2 混合检索步骤
-
查询分解:
-
用户查询通过基于 LLM 的意图分析器分解为多个子查询,每个子查询代表一个离散的信息意图。
-
知识图谱检索:
-
将初始查询嵌入到向量空间中,并与知识图谱中的相关实体进行匹配。
-
然后执行多跳遍历,扩展检索范围,生成结构化的、特定领域的上下文。
-
查询重写:
-
利用图谱派生的上下文,通过图感知提示模板重写原始查询,使其更加具体和明确。
-
向量检索:
-
将重写的查询向量化,并从向量数据库中检索出语义相似的文本片段。
-
信息整合:
-
将所有相关信息源(原始查询、重写后的查询、知识图谱上下文、检索到的文本片段和用户交互历史)整合到一个统一的提示结构中。
3.3 生成与细化步骤
-
初始答案生成:
-
基于检索到的证据,使用简单的提示策略生成初始答案。此时,明确指示 LLM 避免生成未经支持的内容。
-
答案细化:
-
将初始答案传递给细化提示,重新构建和验证答案,确保其事实准确性。
-
答案压缩:
-
通过压缩阶段调整答案的语气、语言和风格,使其与原始查询保持一致,同时确保连贯性和简洁性。
-
后续问题生成:
-
基于细化后的答案和整体对话上下文,生成后续问题,引导用户进行更深入的探索。
https://arxiv.org/pdf/2505.17058
推荐阅读
-
效率提升30%,Token减少 98%!LightPROF加速GraphRAG落地
-
港中大&华为云联合突破!首次提出GraphRAG统一框架
-
DeepSeek过度思考「自省式推理」登顶多跳问答榜” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>清华ReaRAG,严防Deepseek过度思考「自省式推理」登顶多跳问答榜
-
微软再放大招!成本直降99.9%!:LazyGraphRAG「实时分析」秒级落地!
-
Alibaba首创:多模态混合检索+多智能体RAG
-
GraphRAG性能拉胯,DeepSearcher开箱即用
-
Alibaba新年首秀RAG,千万别错过~
-
GraphRAG落地难,微软工业级RAG+Agent实施方案
-
必读!RAG好用的3种Router
-
1.2kStar RAG2.0具备超长记忆,实现全局检索
