

其实不论是常规的AI应用,还是现在大家都在传的Agent框架:

一直有个问题是难以解决的:模型与领域知识(个人知识)如何混用的问题。
因为一般公司对模型的使用多还是粗暴的直接上提示词,比如我们在《为什么AI多轮对话那么傻》这篇文章里面为文章生成观点这块。
这种生成提示词,其本质是使用模型本身的知识,那么他就一定不能被称为一个合格的分身,举个例子,我的AI分身有一段发言:
你这鬣狗哲学挺溜啊!但华为狼狈计划能成,不正是高层先打破了元老垄断?光逼总监分权却纵容董事会搞小圈子,跟要求瘸子跑马拉松有啥区别?
逻辑上,我绝不会发出这种言论,核心原因是:我对华为并不熟悉,我的案例全部是来源于平时工作,这也是为什么大家读起来倍感清切的原因。
这里的点是AI每次发言,必须符合预期,他得有我的知识与习惯。他的要求有二:
-
生成观点的时候跟我思维一致; -
输出观点的时候跟我的风格一致;
所有的一切,其实只有一个要求:模型具备记忆功能…
LLM 记忆
记忆模块(Memory)一直是Agent时代研究的重点,也是当前AI应用难以突破的拦路虎。
事实上对于很多缺少流量的公司对此是乐见其成的,因为AI时代的应用变得毫无技术秘密可言,数据资产或许是他们最后的壁垒了。
另一方面前些日子每一次模型发布都可能颠覆一些创业公司,比如GPT的发布就把很多搞文生图的团队拉爆了。
但记忆这个有些不一样:幻觉问题逻辑上是模型难以解决的问题,所以根据知识库做RAG肯定不会错。
而要深入了解记忆问题,可以从两个角度出发:
-
第一,存储,配合大模型的数据(记忆)应该如何存储; -
第二,应用,如何通过数据(记忆)增强模型的上下文理解能力,除了最基础的能记忆,还会涉及到更新、遗忘和记忆的全面性等问题;
然后又一论文对记忆做了基础的分类,我觉得挺不错可以直接使用:
https://arxiv.org/pdf/2505.00675
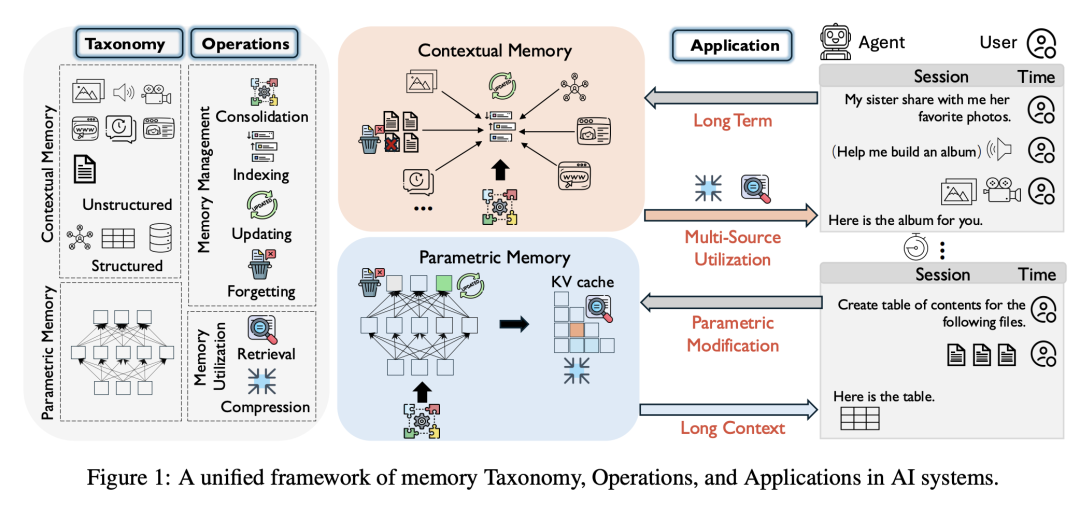
一、参数记忆
所谓参数记忆(Parametric Memory)即模型内置记忆,也就是我们常说的模型自带的知识库,他通过预训练与微调包括RL形成。
这种内置的知识,是一种即时的、长期的、持久的记忆,能够快速、无上下文地检索事实和常识知识。
换句话说:区别于提示词,微调过的模型泛化能力更好。
只不过问题也很清晰:第一是知识时间上有些滞后,更重要的是各种领域知识是缺失的。如果只使用参数记忆,那么模型就跟试用期的员工差不多。
二、上下文非结构化记忆
上下文非结构化记忆(Contextual Unstructured Memory)大家可以理解为多模态信息,包括文字、图像、音视频。
他们可以让模型拥有阅读、视觉和听觉的能力,是为了解决Agent感知能力而诞生。
三、上下文结构化记忆
上下文结构化记忆(Contextual Structured Memory)是我们最常见的知识结构。
比如知识图谱、关系表或本体论,同时保持易于查询。这些结构支持符号推理和精确查询,通常补充预训练语言模型的关联能力。
PS:虽然可以直接使用,但现在AI论文的营养真的很低…
关于知识的处理
|
|
|
|
|
|---|---|---|---|
| 巩固 (Consolidation) |
|
|
MemoryBank
|
| 索引 (Indexing) |
|
|
HippoRAG
|
| 更新 (Updating) |
|
|
NLI‑transfer
|
| 遗忘 (Forgetting) |
|
|
|
| 检索 (Retrieval) |
|
|
LoCoMo
|
| 压缩 (Compression) |
|
|
xRAG
|
我这里不一一去拆解论文了,就按照我的理解做解读即可,所谓记忆操作即是把易失的短期上下文→可持久存取的长期记忆。他的核心难点是:
-
选哪些内容? -
存成什么格式? -
如何让 LLM 以后真正“想得起”?
举个实际的例子,我写了一套40节课管理课程,现在要做一个AI分身,这里的知识应该如何巩固?如何用最少工程量就能让 LLM 既找得到、也“想得起”我的内容。
一、存什么内容?
整个流程分三层:外部 RAG 层 → 结构化层 → 轻量微调层,按价值递进。首先是内容选择,可以用这个:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每上传一节课就跑一次“抽取 + 摘要”脚本,把上表三挡内容分层写库,并做少量手工校对,保证关键概念准确。
二、存什么格式
这个其实比较简单,直接结构化知识库+RAG一起用就好,处理的数据大概长这样:
{
"id": "L17-okr-loop",
"type": "concept",
"title": "OKR 循环",
"summary": "设定目标→关键结果→对齐→检查→复盘",
"keywords": ["目标管理","OKR","循环"],
"lesson": 17,
"timestamp": "2025-05-10T12:00:00Z",
"importance": 0.9
}
事实上,结构化知识库这里会直接引入知识图谱。
三、让LLM想得起
所谓想得起也就是召回率较高,这里策略也很多,比如先根据提问里的显式词,过滤 40 节课中相关信息(缩小向量检索范围,延迟可降 40‑60%)。
这也就是说,可以用模型先针对提问优化一波问题,提取出关键词再去检索。
其次,挑选“高频命中率 > 30%” 且 “回答需要一步就能说清”的知识(≤ 500条)。
也就是用一些策略,丢弃到大部分不需要的返回。
这里其实就是一般的RAG操作,这里实际上也说得比较简单,大家自行品味即可…
最后说下知识图谱的问题。
知识图谱
关于知识图谱如何增强大模型,之前有文章做过介绍:知识图谱
今天,我们还是沿着前文的案例做延伸:构建我个人的AI分身。这里最关键的挑战是如何让模型真正"继承"我的知识体系和思维模式。
这里以如何将40节管理课程转化为知识图谱,并实现与大模型的深度协同,打造一个真正"懂你"的AI分身。
一、知识提取
将40节管理课程转化为知识图谱不是简单的文本转换,而是需要建立概念层-关系层-案例层的三级知识表示体系:
-
概念层:提取课程中的核心管理理论、方法论和工具框架 -
节点示例:OKR循环、5W2H分析法、德鲁克五大任务 -
属性包括:定义、提出者、适用场景、优缺点 -
关系层:建立概念间的多维关联 -
"OKR循环"→"衍生自"→"MBO理论" -
"5W2H分析法"→"可用于"→"问题诊断场景" -
案例层:连接抽象理论与具体实践 -
"华为部门墙案例"→"印证"→"跨部门协作障碍" -
"Netflix文化变革"→"体现"→"情境领导理论"
事实上,知识整理直接会决定后续模型回答的好坏,所以这里值得花大力气!
二、图谱构建
图谱构建有很多框架,我们这里简单描述即可,以"目标管理"模块为例,其知识图谱片段可能包含:
{
"nodes": [
{
"id": "MBO",
"type": "concept",
"label": "目标管理理论(MBO)",
"properties": {
"definition": "彼得·德鲁克1954年提出的以目标为导向的管理方法",
"core_principles": ["目标设定","自我控制","成果导向"],
"lesson_reference": ["L03","L17"]
}
},
{
"id": "OKR",
"type": "concept",
"label": "OKR目标管理法",
"properties": {
"derived_from": ["MBO","SMART原则"],
"implementation_steps": ["目标设定","关键结果定义","定期复盘"],
"case_studies": ["Google2018年OKR实施","字节跳动双月OKR"]
}
}
],
"edges": [
{
"source": "OKR",
"target": "MBO",
"type": "derived_from",
"weight": 0.9
},
{
"source": "OKR",
"target": "SMART",
"type": "enhanced_by",
"weight": 0.7
}
]
}
这种结构化表示使知识具备了可追溯性(每个结论都有课程来源)和可组合性(不同概念能自由关联)。
三、检索
接下来就到了关键的检索增强环节,当AI分身需要回答用户提问时,采用图检索→向量精筛→上下文构造的三阶段处理:
一、图模式匹配:将自然语言问题转化为图查询,比如:
问题:"OKR与KPI如何结合使用?" → 匹配"OKR"和"KPI"节点及其间路径
二、子图提取与向量精筛:其实就是将概念比较近的知识全部提取出来:
(OKR基本原则)
│─┬─ 包含: [挑战性目标设定] (权重0.9)
│ ├── 冲突: [可实现性评估] (需平衡)
│ └── 应用: [Google 2014年OKR改革]
│
(目标设定理论)
│─┬─ 源自: [德鲁克MBO理论]
│ └── 工具: [SMART原则]
三、上下文构造:将检索结果转化为自然语言提示
这个比较简单,比如:"根据课程L17和L23:1) OKR侧重目标导向,KPI侧重指标测量… 2) 华为实践表明…"
四、思维链增强
在生成回答时,AI分身模拟专业咨询师的思考过程:
-
概念定位:这个问题涉及目标管理领域的OKR与KPI对比 -
知识提取:回忆课程中三个相关案例和两个理论框架 -
观点整合:我的典型分析角度是先区分适用场景再谈融合方法 -
风格适配:采用问题-根源-方案的三段式表达
你是一位资深管理顾问,请按以下结构回答:
1. 问题本质:用一句话点明核心矛盾
2. 理论依据:引用课程中的2-3个关键概念
3. 实践案例:简要描述一个相关企业案例
4. 个人观点:用"我认为"开头表达鲜明立场
当前问题:{用户提问}
相关知识:{检索到的子图信息}
五、案例
最后再给个案例吧,比如有个粉丝今天的问题:空降高管如何快速建立团队威信?
AI分身应该的处理流程:
第一,知识检索
-
匹配到"新官上任三把火"案例(L12) -
关联"权力来源理论"(L08)和"情境领导模型"(L15) -
召回我曾在内部培训提到的"三个月生存法则"
第二,观点生成
1. 问题本质:这是关于领导力合法性与变革管理的平衡问题
2. 理论依据:
- 根据课程L08,权力来源包括职位权力和个人权力
- 情境领导理论强调不同阶段需要不同领导风格
3. 典型案例:
- 课程L12提到的阿里张勇空降案例:前30天只做三件事...
4. 我的观点:
我认为空降领导要避免"证明自己"的陷阱,首月应该:
- 70%时间用于倾听和诊断
- 先解决1-2个显性痛点建立信任
- 通过小胜利(quick wins)积累变革资本
第三,风格调整
-
添加口头禅:"记住,管理是门手艺活" -
使用惯用的排比句式:"一要…二要…三要…" -
保持标志性的70%理论+30%案例的叙述比例
通过这种深度整合知识图谱与大模型的技术方案,AI分身将不再是简单的复读机,而真正成为一个具有一致世界观和专业判断力的数字孪生…
结语
以上其实都在围绕模型记忆展开,相信大家到此也看懂了,所谓模型记忆就是知识库的应用:外部 RAG 铸短期感知,知识图谱构长期索引,轻量微调植入个性。
