传统RAG(Retrieval-Augmented Generation,检索增强生成)和GraphRAG(Graph-based Retrieval-Augmented Generation,基于图的检索增强生成)是两种基于检索增强的生成模型技术,它们的核心区别在于对知识的组织方式和检索机制的设计。
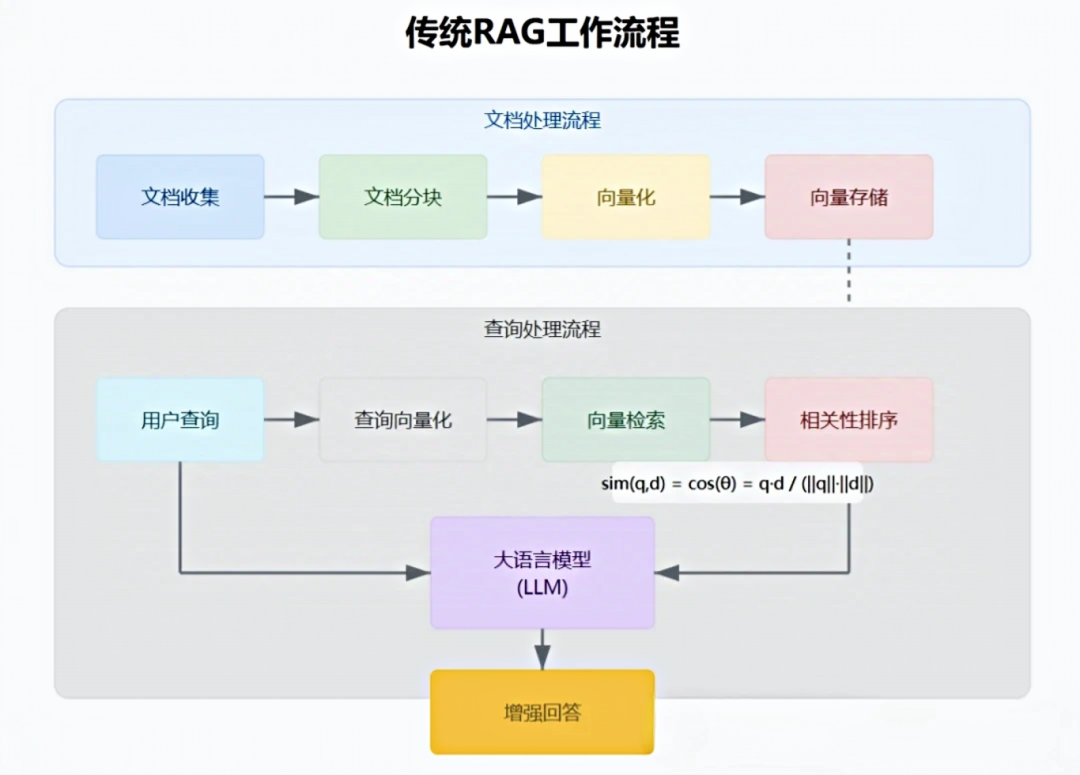
传统的检索增强生成(RAG)依赖向量检索技术,从文档库中查找与用户问题相关的文本片段(chunks),再基于这些片段生成答案。
但这种方式可能忽略文本间的深层语义关系(如实体间的关联、因果链等),导致检索结果不够精准或遗漏关键信息。
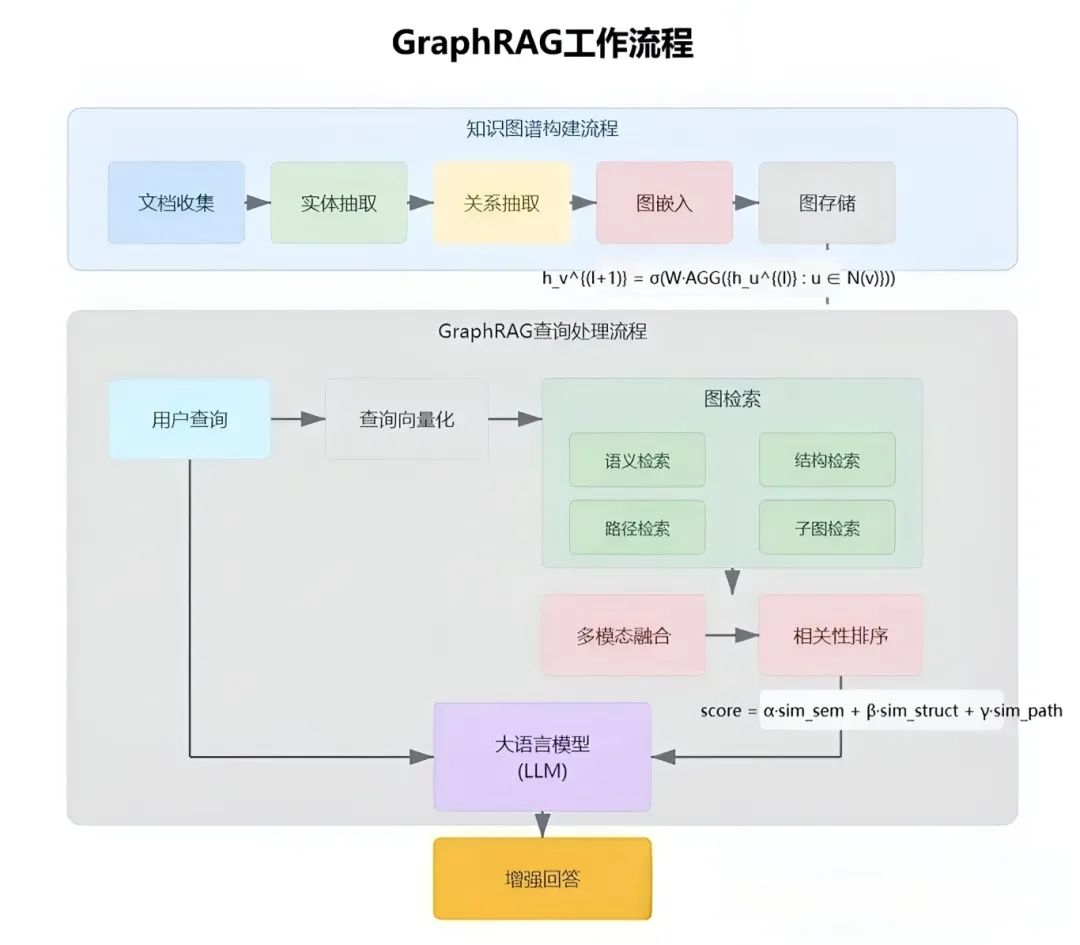
GraphRAG是一种结合知识图谱(Knowledge Graph)与检索增强生成(RAG)的技术,旨在通过结构化数据提升大语言模型(LLM)在复杂场景下的推理能力和生成质量。
其核心思想是:将非结构化文本中的实体、关系、事件等结构化,构建知识图谱,再基于图谱的拓扑关系进行检索和推理,从而提升生成答案的逻辑性和准确性。
-
数据存储:依赖向量数据库,将文本分割为片段后编码为向量。
-
结构特点:知识以独立的文本块形式存储,缺乏显式的语义关联。
-
局限性:难以捕捉跨文档或长文本中的复杂关系(如实体关联、事件因果)。
-
数据存储:构建知识图谱(Knowledge Graph),将文本中的实体、关系、事件等结构化存储为节点和边。
-
结构特点:知识以图结构组织,显式建模实体间的关系(如“A是B的母公司”或“C导致D”)。
-
-
检索方式:基于向量相似度匹配,直接检索与问题最相关的文本块。
-
局限性:可能遗漏分散在多个文本块中的关联信息。对长距离依赖或复杂逻辑推理的支持较弱。
-
图遍历:通过知识图谱的边(关系)检索相关实体和子图。
-
子图匹配:提取与问题相关的局部图谱,保留上下文关系。
-
优势:支持多跳推理(例如从“A导致B”和“B导致C”推断“A间接导致C”)。能捕捉隐含的全局语义。
-
输出特点:依赖检索到的文本块直接生成答案,可能缺乏逻辑连贯性。
-
适用场景:简单问答、短文本生成(如单篇文档摘要)。
-
输出特点:基于图谱的结构化知识生成答案,更擅长复杂推理(如因果分析、事件链解释)。
-
适用场景:需要多文档关联的复杂问题(如“分析某公司股价下跌的原因”)。对逻辑连贯性和可解释性要求高的任务。
使用ChatWiki+DeepSeek,即可0基础搭建一个GraphRAG系统。
ChatWiki是一款国产开源的知识库 AI 问答系统。系统基于大语言模型(LLM )和检索增强生成(RAG)和GraphRAG知识图谱构建,提供开箱即用的数据处理、模型调用等能力,企业,高校和政务部门可快速搭建私有的知识库AI 问答系统。
在Github上可下载ChatWiki软件,有多种部署方式,支持:
Github地址:https://github.com/zhimaAi/chatwiki
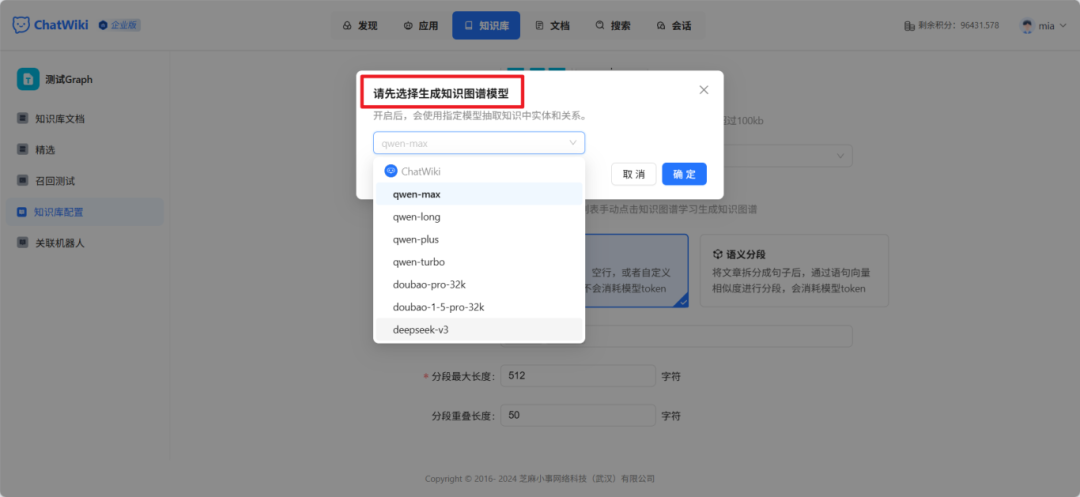
ChatWiki支持接入DeepSeek R1、DeepSeek V3、doubao pro、qwen max、Openai、Claude 等全球20多种主流模型。只需要简单的配置API Key,即可接入DeepSeek。
支持导入Word、Excel、PPT、PDF、markdown等多种格式的文档。
同时开启“生成知识图谱”,这样,一个GraphRAG系统就搭建成功了!
将该知识库应用于机器人或工作流中,当有用户咨询时,GraphRAG会通过实体关系网络提升检索的深度和推理能力,解决复杂问题中的多跳推理需求。
1. 需要多跳推理的问题(如“A如何间接影响C?”)
2. 依赖隐藏关联的决策(如风险预测、学术争议分析)
3. 动态关系分析(如实时更新的新闻事件、企业股权变动)
场景:电商平台需要根据用户历史行为(浏览、购买、退换货)推荐商品,并解释推荐理由。
传统RAG的局限:
传统推荐可能基于协同过滤(相似用户喜欢什么),但无法解释“为什么推荐A商品”(如材质偏好、品牌忠诚度)。
构建用户-商品图谱(如“用户A→购买→运动鞋→偏好→透气材质→关联→品牌N”)。
通过路径分析,发现用户偏好(如“透气材质>品牌>价格”),并推荐符合逻辑链的商品。
示例输出:“根据您常购买透气材质的运动鞋,我们推荐品牌N的新款跑鞋(透气性评分9.5,与您之前购买的款式相似)。”
场景:分析某国际事件(如能源危机)的根源和后续影响,追踪涉及的国家、企业、政策关联。
传统RAG的局限:
传统检索可能返回事件的时间线报道,但无法自动梳理因果链(如“地缘冲突→天然气断供→德国制造业成本上升”)。
构建事件因果图谱(如“俄乌战争→影响→天然气管道→导致→欧盟电价上涨→迫使→工厂迁往XXX”)。
示例输出:“能源危机源于俄乌战争对天然气供应的限制,间接导致德国汽车制造业成本上升,宝马已宣布在XXX扩建工厂。”