

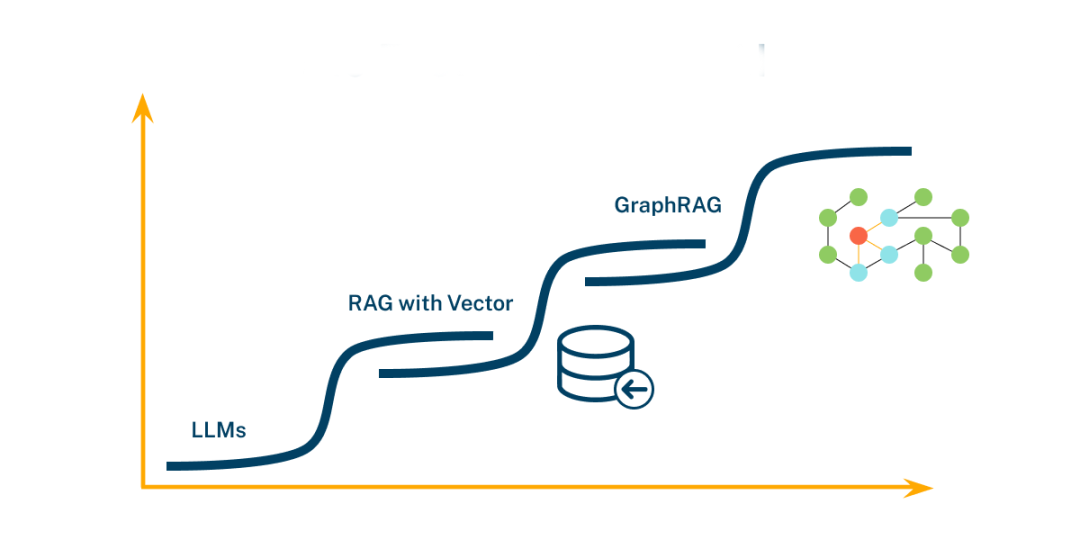
GraphRAG(Graph-based Retrieval-Augmented Generation)是检索增强生成(RAG)技术的升级版本,通过将知识图谱(Knowledge Graph)与大型语言模型(LLM)结合,解决了传统RAG在处理复杂查询、多跳推理和跨文档语义关联上的局限。其核心目标是通过结构化的知识图谱表示,捕捉数据中实体、关系及全局语义,从而提升LLM对私有或未训练数据的理解与生成能力。

一、GraphRAG
-
复杂查询:利用社区聚类(如Leiden算法)生成分层摘要,支持跨文档主题分析(如“近五年AI研究趋势”),实现全局语义理解,解决复杂查询。 -
多跳推理:通过图谱路径回答需多次关联的问题(如“A事件如何间接导致C结果”。
案例1:复杂查询(社区聚类 + 跨文档主题分析)
将海量AI文献数据划分为高内聚、低耦合的社区,每个社区代表一个研究主题。在社区聚类基础上,分析不同主题间的关联与演化趋势。
-
输入:近五年AI领域文献数据。 -
构建文献网络:以文献为节点,引用关系为边,构建加权图。 -
社区聚类:使用Leiden聚类算法,输出分层社区结构。
-
第一层:基础技术(机器学习、深度学习) -
第二层:应用领域(自然语言处理、计算机视觉) -
第三层:细分方向(生成式AI、多模态学习)
-
生成分层摘要: -
对每个社区提取高频关键词、主题词,生成社区级摘要。 -
聚合社区摘要,形成全局分层摘要。
-
主题关联分析:计算社区间主题相似度(如余弦相似度),构建主题关联图。 -
趋势预测:基于时间序列分析,识别主题的兴起、衰落与融合。
-
输出:“近五年AI研究趋势”报告 -
2020-2021:深度学习模型优化(如Transformer改进) -
2022-2023:大语言模型(如GPT系列)爆发 -
2024:多模态AI与具身智能(Embodied AI)兴起
通过知识图谱路径,回答“A事件如何间接导致C结果”的复杂问题。
-
问题:“A事件(2019年Transformer架构提出)如何间接导致C结果(2023年ChatGPT发布)?” -
构建知识图谱: -
节点:事件、技术、领域、机构等。 -
边:因果关系、引用关系、合作关系等。
-
图谱路径分析: -
A事件→ B事件(2020年Google发布BERT模型,验证Transformer有效性)。
-
B事件→ C事件(2022年OpenAI基于Transformer训练GPT-3,2023年发布ChatGPT)。 -
解释生成:将路径转化为自然语言描述,例如:Transformer架构的提出(A)推动了预训练语言模型的发展(B),最终催生了ChatGPT(C)。
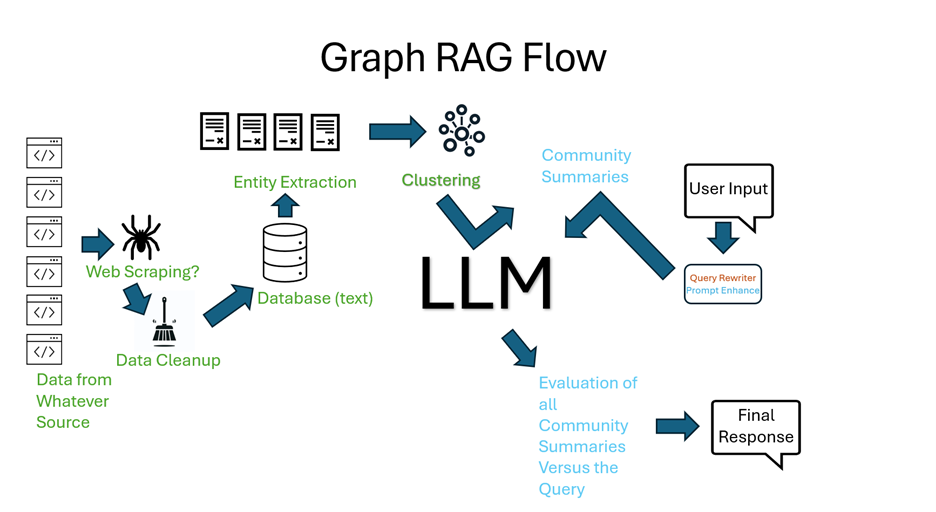
二、知识图谱
如何进行知识图谱(Knowledge Graph)的构建?知识图谱构建的核心是将非结构化数据转化为语义网络,通过实体识别、关系抽取和图谱融合,最终形成可查询、可推理的知识图谱。这一过程需要结合NLP技术、图数据库和领域知识,适用于智能问答、企业决策支持等场景。

一. 知识图谱构建核心:将非结构化文本转化为结构化知识网络
知识图谱构建的核心任务是将海量非结构化文本数据(如新闻、文献、网页内容等)转化为结构化的知识图谱。在这一过程中,节点代表实体(如人物、地点、事件、概念等),边则表示实体之间的语义关系(如“糖尿病→胰岛素→副作用”)。通过这种结构化表示,知识图谱能够清晰展现实体间的关联,为后续的语义推理、信息检索和智能问答提供支持。
二. 知识图谱构建过程:实体识别、关系抽取和图谱融合
- 实体识别:从文本中识别出关键实体(如“糖尿病”“胰岛素”“副作用”),并将其作为知识图谱的节点。
示例:从“糖尿病患者使用胰岛素可能引发低血糖”中抽取实体“糖尿病”“胰岛素”“低血糖”。 - 关系抽取:确定实体之间的语义关系(如“治疗”“引发”“属于”等),并将其作为边连接相关节点。
示例:根据上述文本,构建关系“糖尿病→治疗→胰岛素”“胰岛素→引发→低血糖”。 - 图谱融合:合并来自不同文本的重复实体或关系,确保图谱的一致性。
示例:若另一文本提到“胰岛素的副作用包括低血糖”,则将其与现有关系融合,形成更完整的图谱。
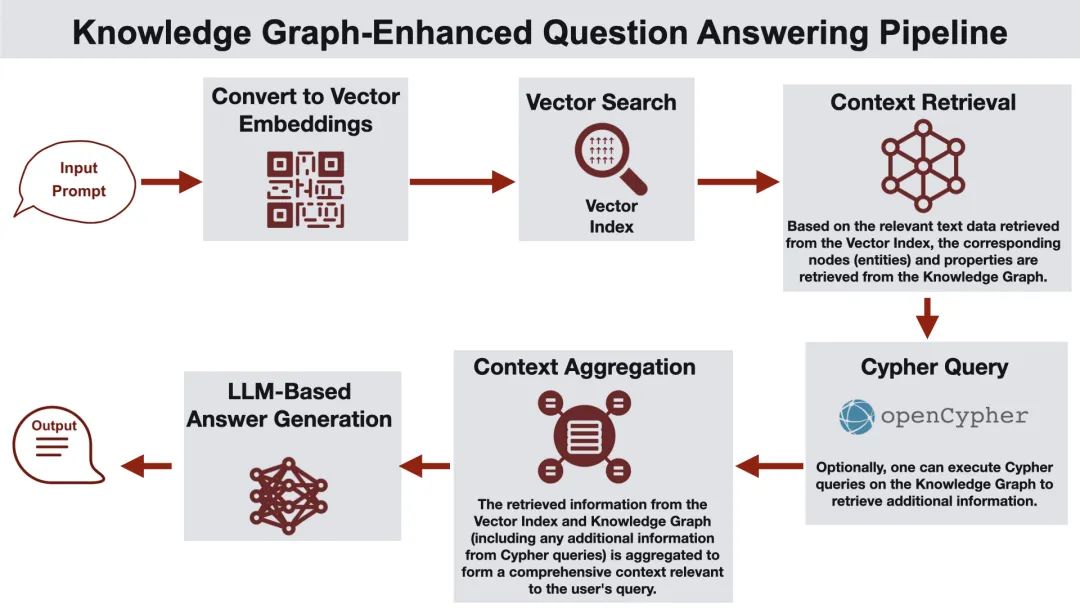
三、知识图谱典型案例:构建糖尿病知识图谱
-
数据来源:医学文献、百科词条、患者论坛。 -
实体:糖尿病、胰岛素、低血糖、血糖监测、饮食控制。 -
关系:糖尿病→治疗→胰岛素,胰岛素→引发→低血糖,糖尿病→管理→血糖监测。
