

本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
本文此分享一个LightPROF(Lightweight and efficient Prompt learning-ReasOning Framework for KGQA)的轻量级推理框架,旨在解决大型语言模型(LLMs)在知识更新延迟导致推理错误或产生有害结果的问题。
LightPROF 通过“检索-嵌入-推理”流程,利用小规模 LLMs 高效完成复杂推理任务,仅需训练知识适配器,兼容任何开源 LLM。
现有方案的局限性
-
知识更新延迟: -
LLMs 在知识密集型任务中表现不佳,因其缺乏特定任务的先验知识和理解能力,且训练成本高昂,难以持续更新知识库。 -
现有方法的不足: -
结构信息缺失:将 KG 内容直接作为文本内容注入 LLM,未有效传达图结构中的逻辑关系。 -
效率低下:检索和推理过程需要大量 LLM 调用和推理能力,导致效率降低,且需要更大的上下文窗口和更强大的 LLM。 -
现有基于 KG 的 LLM 推理方法存在以下问题:
LightPROF重点解决的问题

-
高效检索:如何准确、稳定地从 KG 中检索出与问题相关的推理图。 -
结构化信息利用:如何将 KG 的文本内容和图结构转化为 LLM 友好的提示。 -
轻量级推理:如何在小规模 LLMs 上实现高效推理,减少对大型 LLM 的依赖。
LightPROF
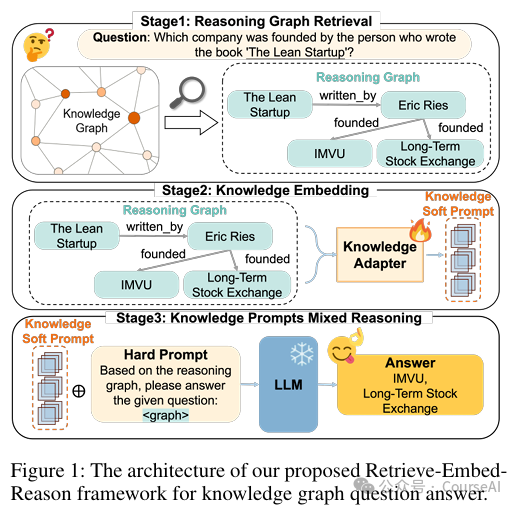
LightPROF 通过“检索-嵌入-推理”框架,充分利用 LLMs 的潜力,解决知识图谱问答(KGQA)任务中的复杂推理问题。
-
检索模块(Reasoning Graph Retrieval): -
语义提取(Semantic Extraction):使用预训练语言模型(如 BERT)提取问题的语义,确定推理所需的跳数(hop)和锚点实体(anchor entities),缩小检索范围。 -
关系检索(Relation Retrieval):基于锚点实体和预测的跳数,在 KG 中进行受限的广度优先搜索(BFS),收集所有从锚点实体出发的关系链。 -
推理图采样(Reasoning Graph Sampling):将检索到的关系链输入 LLM,根据与问题的语义相关性进行排序,选择前 k 个相关链,基于这些链在 KG 中采样,构建精炼的推理图。 -
这种检索方式不仅提高了检索的准确性和稳定性,还大大缩小了搜索空间,减少了对频繁 LLM 调用的需求 -
嵌入模块(Knowledge Embedding): -
对于推理图中的每个三元组,使用 Embed(·)(如 BERT)获取关系嵌入和实体嵌入。 -
使用 StructEmb(·) 编码局部结构信息,然后通过 Linear(·) 聚合全局结构信息。 -
使用 Fusion(·) 结合文本信息,将所有头实体、关系和尾实体的嵌入合并为推理路径的文本表示。 -
使用 KnowledgeEncoder(·) 将文本信息和结构信息整合为推理路径的融合表示。 -
通过可训练的投影器 Φ(·) 将融合表示映射到 LLM 的输入空间,生成知识软提示(knowledge soft prompt)。 -
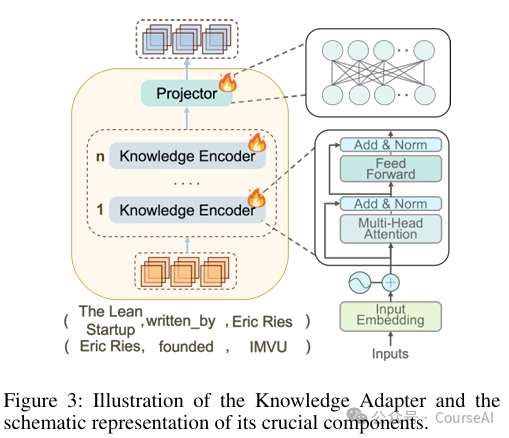
知识适配器(Knowledge Adapter):通过 Transformer 基础的结构,提取推理图中的文本信息和结构信息,并将其整合为适合 LLM 的表示。具体步骤如下: -
通过基于 Transformer 的知识适配器,从推理图中精细提取和整合文本信息和结构信息,然后将这些信息映射到 LLM 的标记嵌入空间,创建适合 LLM 的提示。 -
该模块以高效、简洁的方式对信息进行编码,解决了潜在的歧义和信息冗余问题,同时减少了所需的输入标记数量和上下文窗口大小,从而提高了推理的准确性和效率 -
推理模块(Knowledge Prompts Mixed Reasoning): -
将知识软提示与精心设计的自然语言提示(硬提示)结合,输入到 LLM 中进行推理。 -
冻结 LLM 的参数,仅训练知识适配器,通过最大化生成正确答案的概率来优化模型。 -
仅训练知识适配器,避免了对 LLM 进行昂贵且耗时的重新训练,从而减少了知识更新延迟对 LLM 推理的影响
示例展示
例如:问“Lindsay Lohan 滥用了哪些药物?”

-
LightPROF 的检索模块会从知识图谱中检索出与“Lindsay Lohan”相关的“药物滥用”关系链 -
嵌入模块将这些关系链的文本和结构信息整合为知识软提示 -
推理模块将知识软提示与问题提示结合,输入 LLM 进行推理,最终得出答案“酒精饮料”和“可卡因”。 -
LightPROF 能够准确识别并全面回答查询,展示出更深入的推理路径和更高的评分。 -
相比之下,StructGPT 虽然能够处理相关问题,但未能完全捕捉到所有相关答案。 -
LightPROF 还能够持续生成仅包含答案的输出,使用更少的输入标记和更短的推理时间,证明了其在高效准确处理复杂 KGQA 任务方面的可靠性和实用性。

-
LightPROF 在处理 WebQSP 数据集时,时间成本比 StructGPT 低 30%(1:11:49 vs. 1:42:12)。 -
在输入token数量方面,LightPROF 仅使用 365,380 个标记,而 StructGPT 使用 24,750,610 个标记,LightPROF 的标记使用量减少了约 98%。 -
LightPROF 的平均每个请求的标记数(NPR)为 224,远低于 StructGPT 的 6400,表明 LightPROF 在处理每个请求时更精确、更高效。
