

不需要部署,不需要了解原理,更不需要操心运维和安全,点两下就可以实现一个功能完备的RAG。
什么是RAG
你问大模型“美国2025年4最新关税提高到了多少?”,它一定不知道。
因为主流模型的训练数据就到2024年,大部分还是2023年的,这就是目前大多数AI的局限性——它们只知道训练时学到的内容,对于新信息或专属于你的信息则一无所知。
而RAG技术(全称是Retrieval-Augmented Generation,检索增强生成)就是为了解决这个问题。让AI能够主动去"查资料"。
传统RAG系统的痛点
RAG看起来很好,但搭建一个完整的RAG系统却十分复杂:
你得需要管理多种工具和服务,然后要编写大量的"胶水代码"将各个部分连接起来,这中间还要更新后需要重新索引,完了,维护成本高,容易出错。
等于是自己从零搭建一辆汽车,不仅要有发动机、轮胎、方向盘等各个部件,还要确保它们能够协调工作,一旦任何部分出了问题,整车就无法前行。
虽然市面还有类似于IMA这类的第三方集成度比较高的RAG应用,但是个人知识库的隐私性又无法保证。
赛博菩萨Cloudflare的AutoRAG就像是提供了一辆已经组装好的汽车,你只需要加油(提供数据)和开动(提问)即可。
它自动处理了从数据摄入、切片处理、向量嵌入到检索和响应生成的全过程。
它还会持续监控你的数据源,当有新信息时自动更新索引,始终是最新信息,而无需手动干预。
AutoRAG实现的步骤和原理
整个的索引流程是后台自动运行,用户只需要做一件事,
在数据源(如R2存储桶)放入文件,
之后就是后台的一系列操作:
- 将所有文件转换为结构化的Markdown格式
- 将文本分割成小块以提高检索精度
- 使用嵌入模型将内容转换为向量
- 将生成的向量存储在Cloudflare的Vectorize数据库中
- 查询流程(用户提问时触发)
- 接收用户查询
- 可选择性地重写查询以提高检索质量,将查询转换为向量
- 在向量数据库中搜索最相关的内容
- 从原始数据源获取内容
- 使用语言模型生成基于检索内容的回答
实践
第0步,注册Clouflare,因为AutoRAG是完全免费的,不需要绑卡,直接用就行。
第1步,来到个人中心,找到AI栏目下的,AutoRAG
第2步,创建 Create AutoRAG
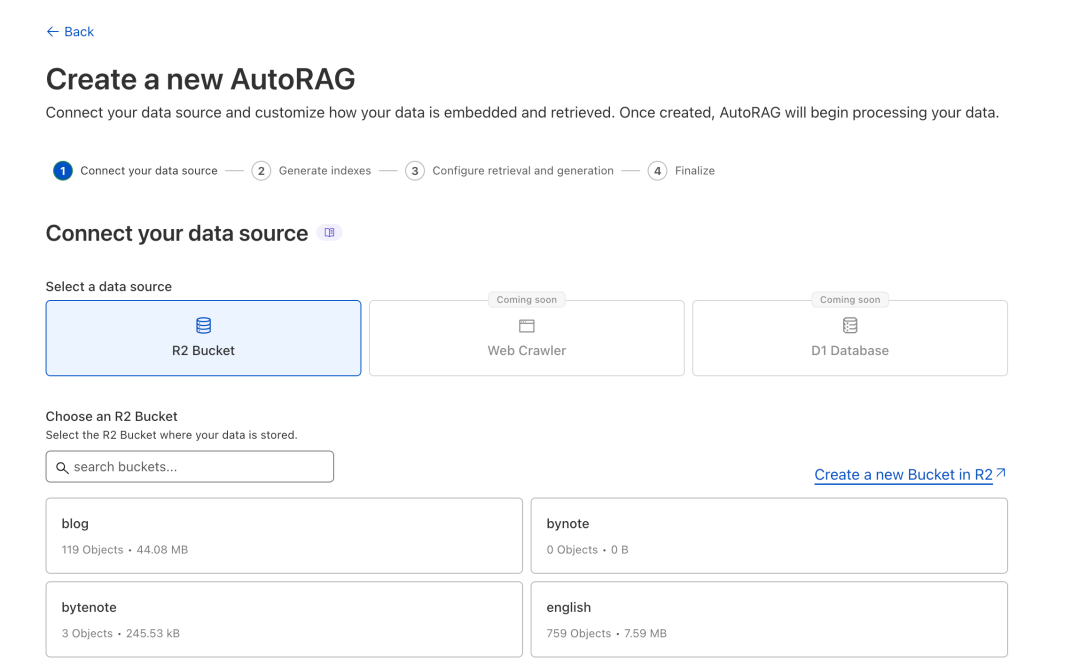
第3步,选择“数据源”,目前仅支持R2,这个名字看着怪怪的,其实就是一个文件存储库。后续我们的资料就直接往里面扔就完了。
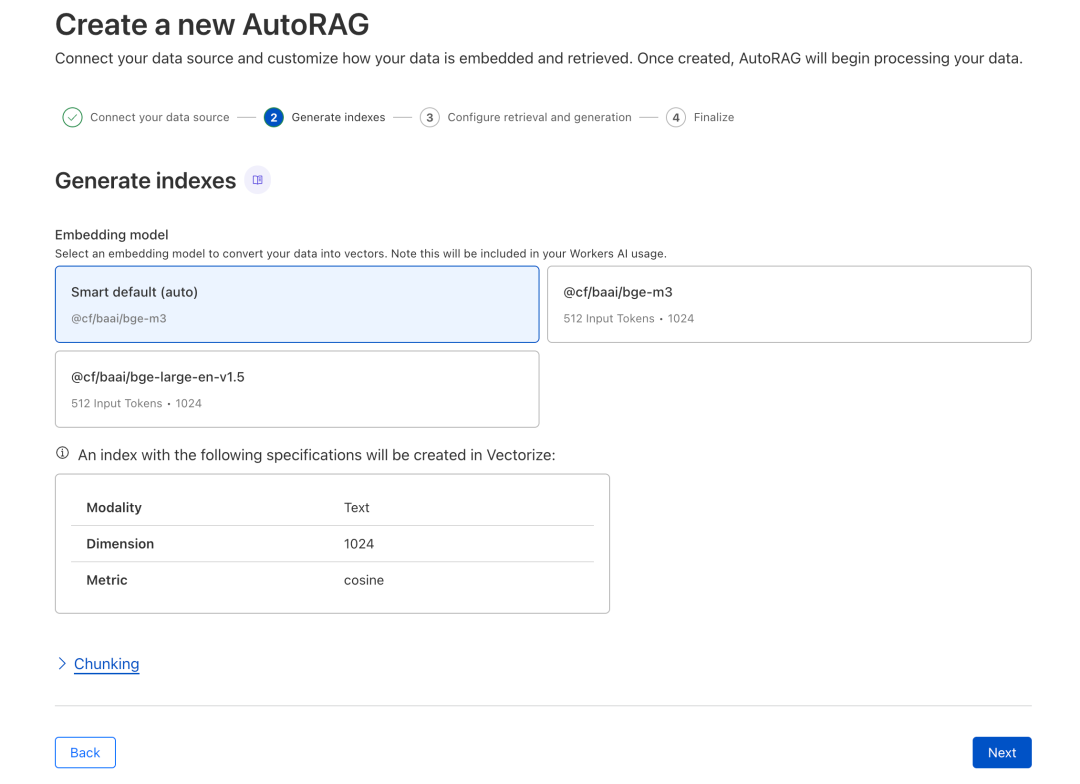
第4步,选择“Embedding model”嵌入模型,无脑选择‘auto’就行,但是需要注意的是这个会计入到你的模型使用量中,价格之前有介绍 ,这里就不再提了,反正就是每天的免费额度个人用完全够。
第5步,起个名字。比如这里的“bytenote"
最后一步,使用,Cloudflare最后一步提供了界面和相关的API调用代码。后续需要上传的资料直接放到上面创建的R2桶就会自动进行索引。
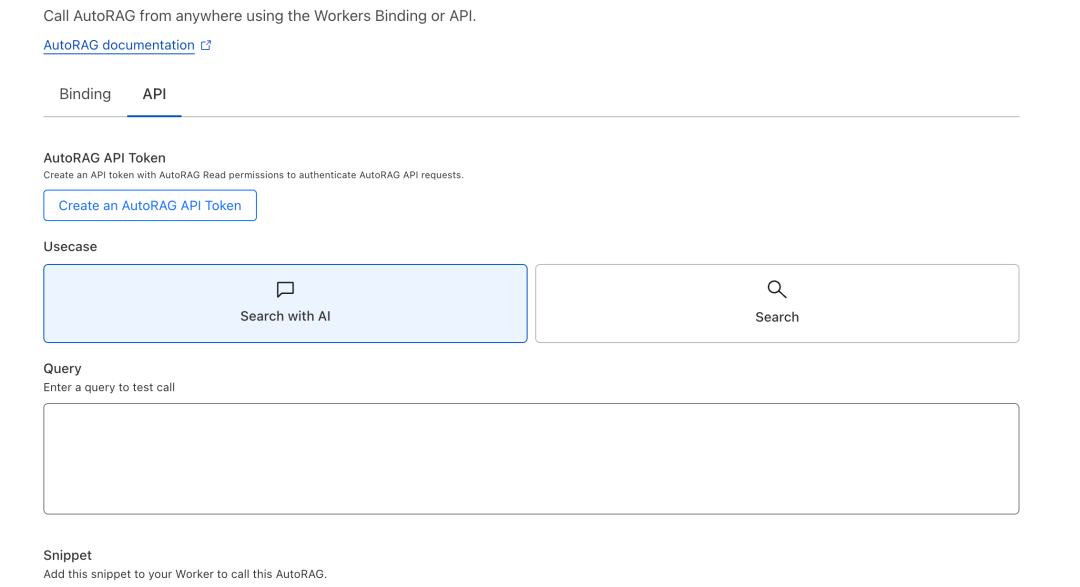
测试,我这里上传了一个关于模型参数的文档,在Playground进行测试,成功地召回,并且给出了出处。

同样也提供了友好的接口界面。
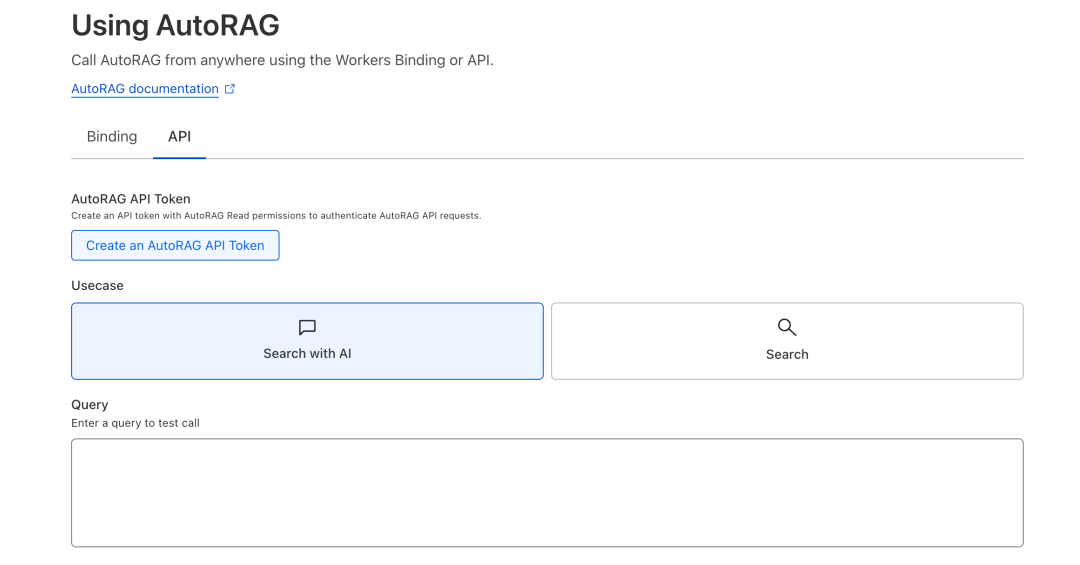
如何是做为个人或者企业资料库会是一个很方便快捷的方式,因为能省很多事。
限制方面:每个账户最多可创建10个AutoRAG实例,每个AutoRAG最多可处理10万个文件。
费用:Cloudflare AutoRAG 在公测期间启用是免费的,但会使用账户中的 Cloudflare 服务资源,这些资源将按您的 Cloudflare 使用量计费。具体包括:R2 存储,Vectorize 数据库。
