

RAG与DeepSeek的碰撞火花
近年来,检索增强生成(Retrieval-Augmented Generation, RAG)成为大语言模型(LLM)应用中的热门技术,它通过结合外部知识库弥补了模型的知识局限。而DeepSeek作为一个以推理能力见长的新兴模型,与RAG的结合似乎是一个充满潜力的方向。然而,这种组合真的能继续走下去吗?锦上添花?本文将从技术现状、实践案例和未来趋势三个维度,带你一探究竟。
一、技术现状:DeepSeek与RAG的适配性分析
-
RAG的基本逻辑与挑战
RAG的核心是将检索与生成结合:先从知识库召回相关文档,再由生成模型加工输出。这种方法在需要高准确性和可追溯性的场景(如法律、医疗)中表现出色。但挑战在于:检索阶段的准确性(召回率与精确率)直接决定了生成质量,而生成阶段的推理能力又决定了最终答案的逻辑性和实用性。

-
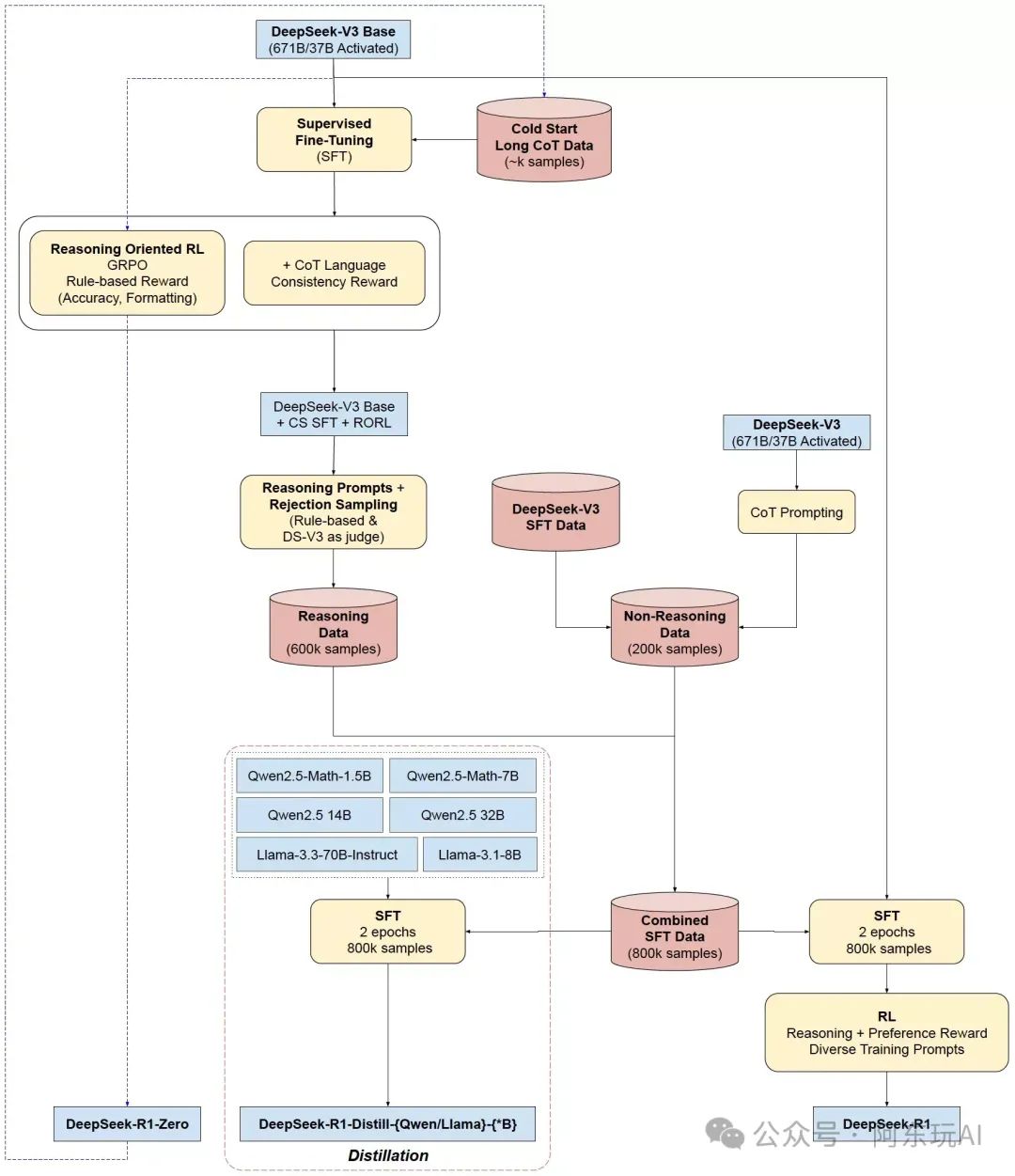
DeepSeek的强项与短板
DeepSeek(特别是R1版本)以强大的推理能力著称,能够通过“链式思维”(Chain-of-Thought)生成逻辑清晰、幻觉较少的回答。然而,它并非万能钥匙。在生成嵌入(Embedding)方面,DeepSeek表现不佳,其发散性思维导致速度慢且与向量数据库匹配度低。相比之下,专门的嵌入模型(如Qwen2)更适合检索任务。
-
结合的现状与优化方向
当前,DeepSeek+RAG的实践多采用分工协作模式:用Qwen2等嵌入模型负责检索,DeepSeek负责生成。这种分工看似合理,但也暴露了一些问题——如果检索阶段过于保守,DeepSeek的推理能力可能无用武之地;如果检索过于发散,又可能引入噪声,影响生成质量。因此,如何平衡检索与生成的复杂度,是技术落地的关键。
二、实践案例解析:法律领域的DeepSeek+RAG实验
为了更直观地理解这种组合的效果,我们来看一个具体的实验:SkyPilot团队在法律领域的RAG尝试。
-
实验设计
-
数据集:使用Pile-of-Law数据集的子集,聚焦法律建议。 -
技术栈:ChromaDB作为向量存储,Qwen2嵌入负责检索,DeepSeek R1负责生成,vLLM和SkyPilot优化性能。 -
目标:为复杂的法律问题提供准确、可追溯的回答。
用两个模型为数据集生成嵌入,并组成两个向量数据库。然后,我们对两个模型使用相同的查询,并在相应模型生成的向量数据库中找到前 5 个最相似的嵌入。
 上表中,DeepSeek R1的检索结果明显更差,这是为什么呢?
上表中,DeepSeek R1的检索结果明显更差,这是为什么呢?
我们认为根本问题在于 DeepSeek-R1 的训练方式。DeepSeek-R1 主要被设计为推理引擎,侧重于顺序思维和逻辑连接。这意味着 DeepSeek-R1 不会将文档映射到语义空间中。
相比之下,Qwen2 模型变体( gte-Qwen2-7B-instruct )专门针对语义相似性任务进行训练,创建了一个高维空间,其中概念相似的文档紧密聚集在一起,而不管具体措辞如何。
这种训练过程的差异意味着 Qwen 擅长捕捉查询背后的意图,而 DeepSeek-R1 有时会遵循导致主题相关但实际上不相关的结果的推理路径。
除非 DeepSeek-R1 针对嵌入进行了微调,否则不应将其用作 RAG 的检索嵌入模型。
-
关键发现
-
不要用DeepSeek做检索:实验对比了DeepSeek R1与Qwen2的嵌入效果,结果显示DeepSeek的检索结果偏离主题(如查询“小额法庭准备”,返回“放狗是否合法”),原因是其推理导向的训练逻辑不适合语义空间映射。 -
DeepSeek生成很强:在生成阶段,DeepSeek R1能清晰引用文档,逻辑严密。例如,对于“如何准备小额法庭”的问题,它能从多份文档中提炼要点并生成结构化回答。 -
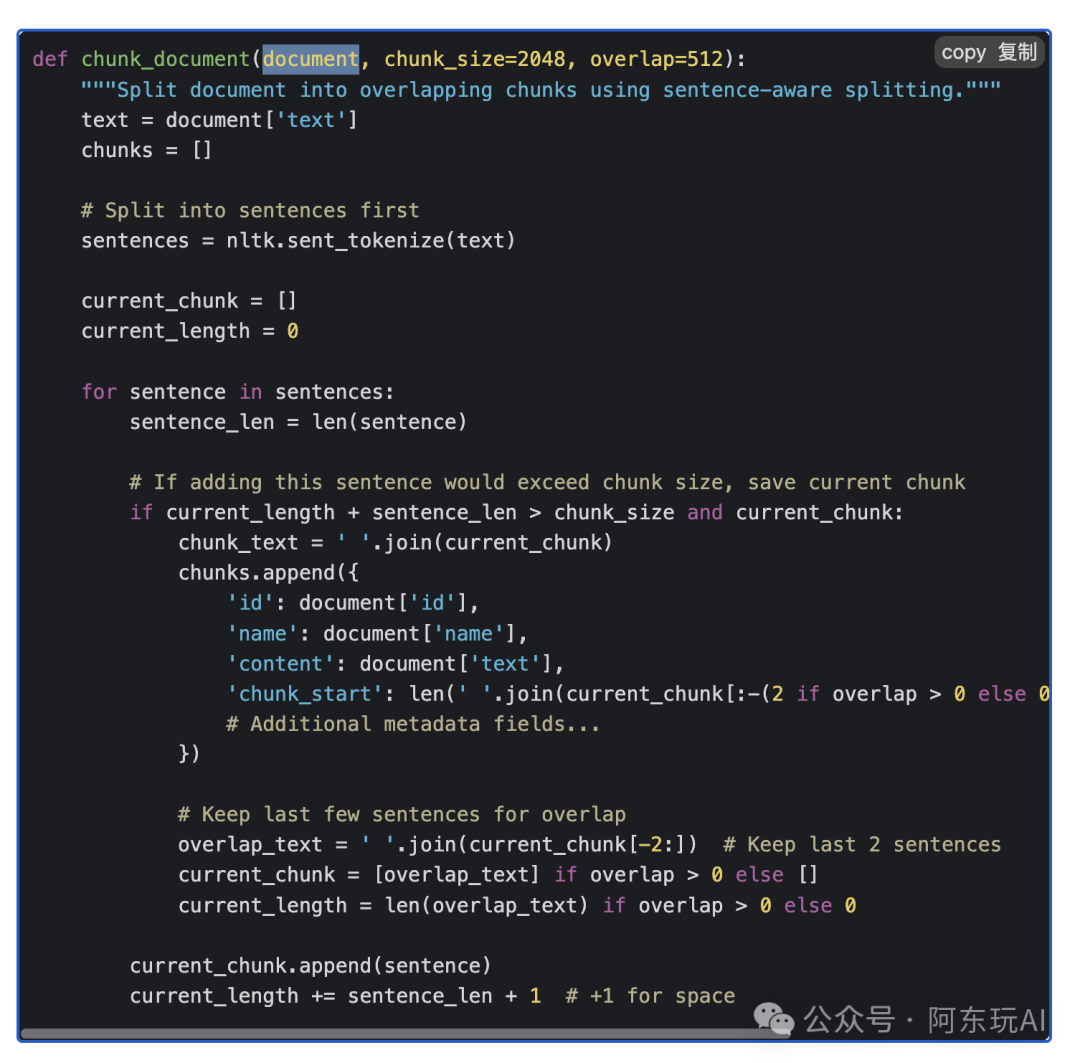
工程优化不可少:精心设计的提示(Prompt)对减少幻觉、提升引用率至关重要;文档分块(Chunking)和并行计算(如vLLM提速5.5倍)也显著提升了效率。
-
启示
这个实验表明,DeepSeek+RAG在需要推理和可追溯性的场景中确实有潜力,但成功的关键在于“扬长避短”——让专业嵌入模型负责检索,DeepSeek专注生成,同时辅以工程优化。
三、未来发展:DeepSeek+RAG的潜力与边界
-
推理与检索的边界在哪里?
当前趋势是将推理能力(Think)更多放在生成阶段,而非检索阶段。例如,O1 Embedder尝试在嵌入模型中加入“思考”步骤,但效果有限且速度慢。相比之下,DeepSeek R1通过生成时的递归推理(见[r1-reasoning-rag]能在复杂问题上实现信息筛选与合成,或许是更高效的路径。 -
用户体验的转变
一个有趣的现象是,用户对“推理时计算”(Test-Time Compute)的接受度在提升。正如https://mp.weixin.qq.com/s/-pPhHDi2nz8hp5R3Lm_mww所说,人们愿意为了高质量结果等待更长时间。这种“延迟满足”观念,可能为DeepSeek+RAG的复杂推理模式打开新空间,尤其是在专业领域。 -
技术演进的方向
-
模型微调:通过针对嵌入任务微调DeepSeek。 -
Agent化趋势:将DeepSeek的推理能力融入Agent框架,比单纯的RAG更灵活。
结论:可以做,但要选对场景
DeepSeek+RAG并非灵丹妙药,但也绝非无路可走。在需要强推理和高可追溯性的任务中(如法律咨询),它仍有发展空间。关键在于:
-
明确分工:检索交给专业嵌入模型,生成交给DeepSeek。 -
场景适配:避免将其用于速度敏感的简单任务,而聚焦复杂推理场景。 -
持续优化:通过提示工程、文档处理和硬件加速提升整体表现。
未来,随着模型能力提升和用户需求变化,DeepSeek+RAG的组合可能会找到更广阔的舞台。你认为这种技术还有哪些可能性?欢迎留言讨论!
引用:
https://blog.skypilot.co/deepseek-rag/ https://arxiv.org/pdf/2502.07555 https://github.com/deansaco/r1-reasoning-rag
{
"target":"简单认识我",
"selfInfo":{
"genInfo":"大厂面试官,中科院自动化所读研(人工智能)ing,从事数据闭环业务、RAG、Agent等,承担技术+平台的偏综合性角色。善于调研、总结和规划,善于统筹和协同,喜欢技术,喜欢阅读新技术和产品的文章与论文",
"contactInfo":"abc061200x, v-adding disabled",
"slogan":"简单、高效、做正确的事",
"extInfo":"喜欢看电影、喜欢旅游、户外徒步、阅读和学习,不抽烟、不喝酒,无不良嗜好"
}
}
