

概述
Jina在2024年推出了一种新的文本切分方法,在论文Late chunking: contextual chunk embeddings using long-context embedding models中做了系统阐述。
来源:https://jina.ai/news/late-chunking-in-long-context-embedding-models/对中文实现Late Chunking,本文应该是第一篇,本文尽可能简单地介绍这项工作的动机、原理以及中文实现,并对结果做一个分析。
动机
正常在撰写文章的过程中,使用一些代词是非常常见的,Jina指出,由于切分导致文本会切分到不同的片段中,而有些片段中只有代词而没有代词所指对象,这可能会导致检索失败。
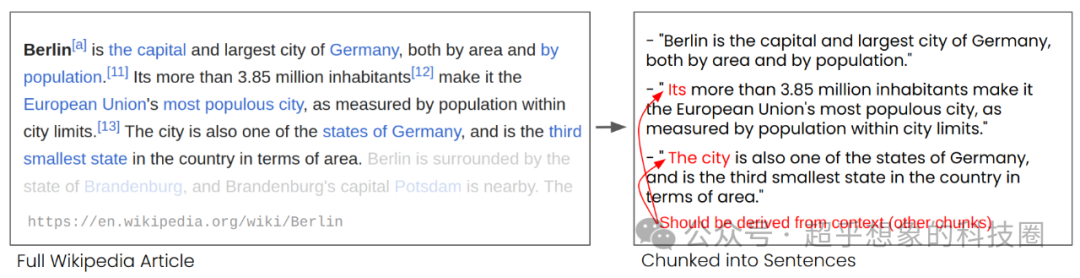
例如下面的这段文本,比如文档按下图右侧的方式切分,用户的问题是“柏林有多少居民”,很明显使用第二个片段可以回答是3.85百万,但由于它使用的是Its,导致这个片段有可能是检索不到的,或者即使检索到了,大模型也没有办法明确知道Its指代的是Berlin。
所以说,此处给了我们一个论文思路,是不是可以在切分前,统一做一个指代消解,然后再切分,这样第二段就会变“Berlin’s more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.” 这样检索时就不会有代词的问题了。感兴趣的朋友可以做个实验。
原理
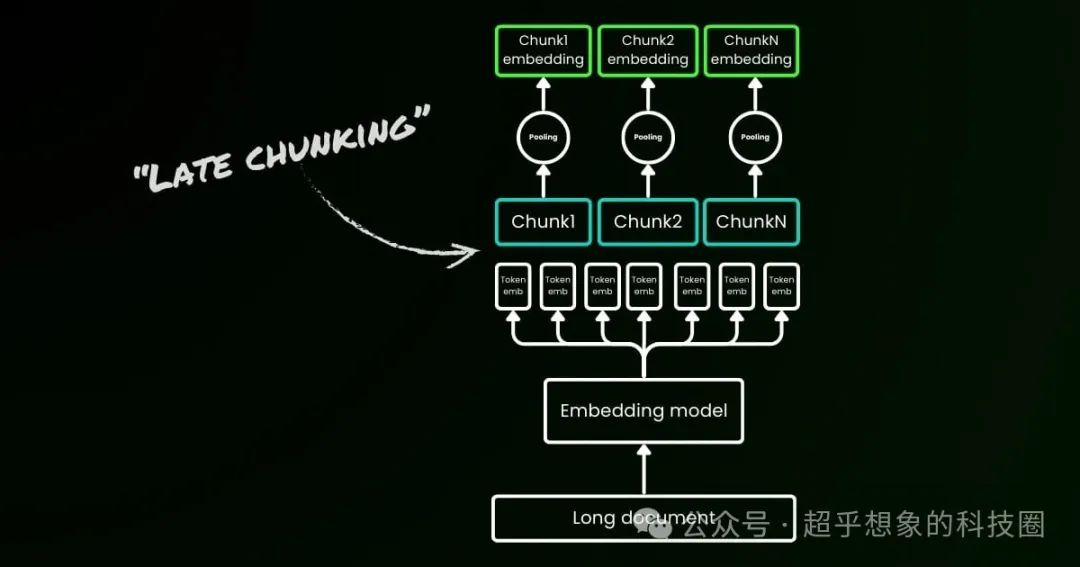
RAG一般的流程是先做文本切分,然后再向量化,而Jina给出的解决方案正如其名——Late Chunking,它是先直接对整段文本做向量化,然后再切分。
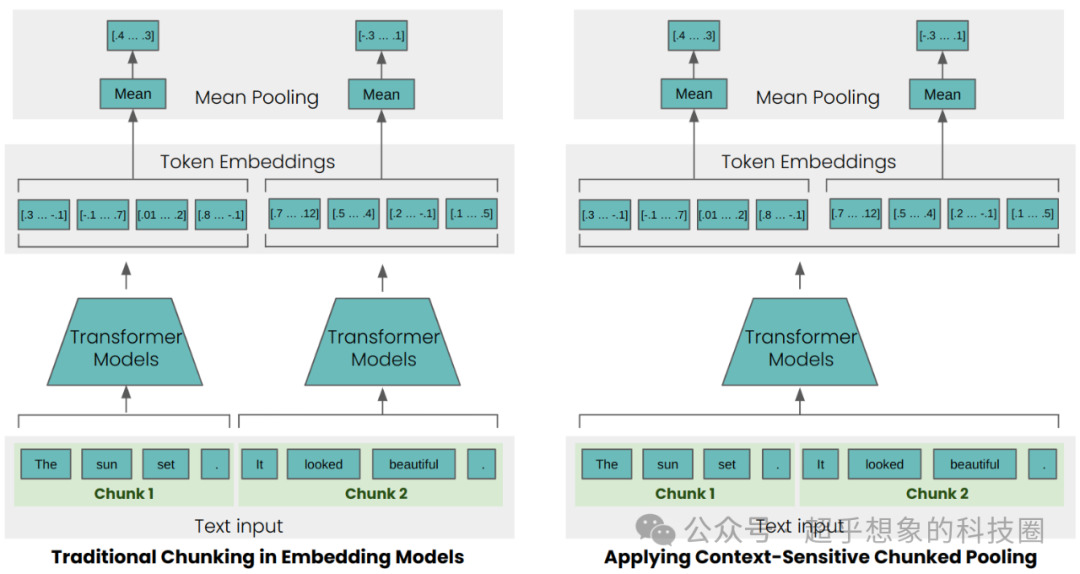
具体是怎么做的呢,首先取知识库中的一整篇文档过Embedding模型,然后会得到一整篇文档每个token位置的Embedding向量,然后按照选取的切分方式,取特定范围的向量做平均,从而得到这个片段的Embedding向量。
例如“DeepSeek是由杭州幻方量化所成立的子公司所开发的大语言模型。它真的很强大!”,
我们假设这段话tokenize后是这样的:
共计23个token,对Embedding模型设置参数,输出每个问题的hidden state(也是个向量,也就是下图中的Token Embedding),如果维度是1024,那就意味着“DeepSeek”这个位置就会有一个1024维的向量,“是”这个位置也是一样。因为是作为一整个句子送入Embedding模型的,所以“它”这个token的hidden state其实融合了整个句子的信息,知道“它”其实指代的是DeepSeek。那如果我们按照句子切分,取“它真的很强”对应位置(上面19-23位置)的hidden state然后做平均,那平均后得到的向量其实表达的含义是“DeepSeek真的很强大”。
这里面涉及3个问题:
-
为什么是取一整篇文档而不是整个知识库:因为实际情况几乎不会出现跨文档还使用代词指代的情况,Late Chunking要解决的是切分导致代词不知其所指的问题,取整个知识库拼接没有意义;
-
所以最后是怎么切分的:Jina官方的代码仓库中有几种方法,分别是按语意、按句子、按token长度,切分之后片段的Embedding,是对片段切分点范围内的Token Embeddings取平均得到的;
-
一整篇文档过Embedding模型不担心超长吗:所以此处Jina要求尽量使用支持长输入的Embedding模型,如果还是超长,那就按照Embedding模型支持的最大长度(例如8192)先切分,假设向量维度是1024,按8192切分后得到7个片段,最终把这7个片段的8192 个维度为1024的向量拼接起来,然后还是按2中提到的方法获取片段的Embedding。这里面其实涉及到很多操作问题,首先比如是按8192切分,其实是token的长度是8192,而不是句子长度,其次是切分后字符的索引要和token的索引对应,最后如果超过Embedding模型的最大长度,需要考虑模型的第一个位置是否有特殊字符,要把它移除。
结果
官方使用了“Berlin”作为Query,分别计算与下面3个句子的相似度。对这3个句子分别使用了两种方式做向量化,一种是传统的先切分再向量化,记为Traditional,另一种是Late Chunking。
第一个句子不存在指代不明的问题,所以两种方法计算的余弦相似度很接近,这个是符合预期的。
第二个句子中有代词Its、it,第三个句子中有The city,使用传统方式计算的余弦相似度就相对较低,而使用Late Chunking方式计算的余弦相似度比较高,这就体现出了Late Chunking的优势。
| Text | Similarity Traditional | Similarity Late Chunking |
|---|---|---|
| Berlin is the capital and largest city of Germany, both by area and by population." | 0.84862185 | 0.849546 |
| Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.7084338 | 0.82489026 |
| The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.7534553 | 0.84980094 |
相似度高意味着什么,意味知识库比较大时,如果输入“柏林的常驻人口有多少”,使用Late Chunking第2个句子会排在候选中更靠前的位置,从而有更大的概率被召回,而传统方法则会排在比较靠后的位置。
效果
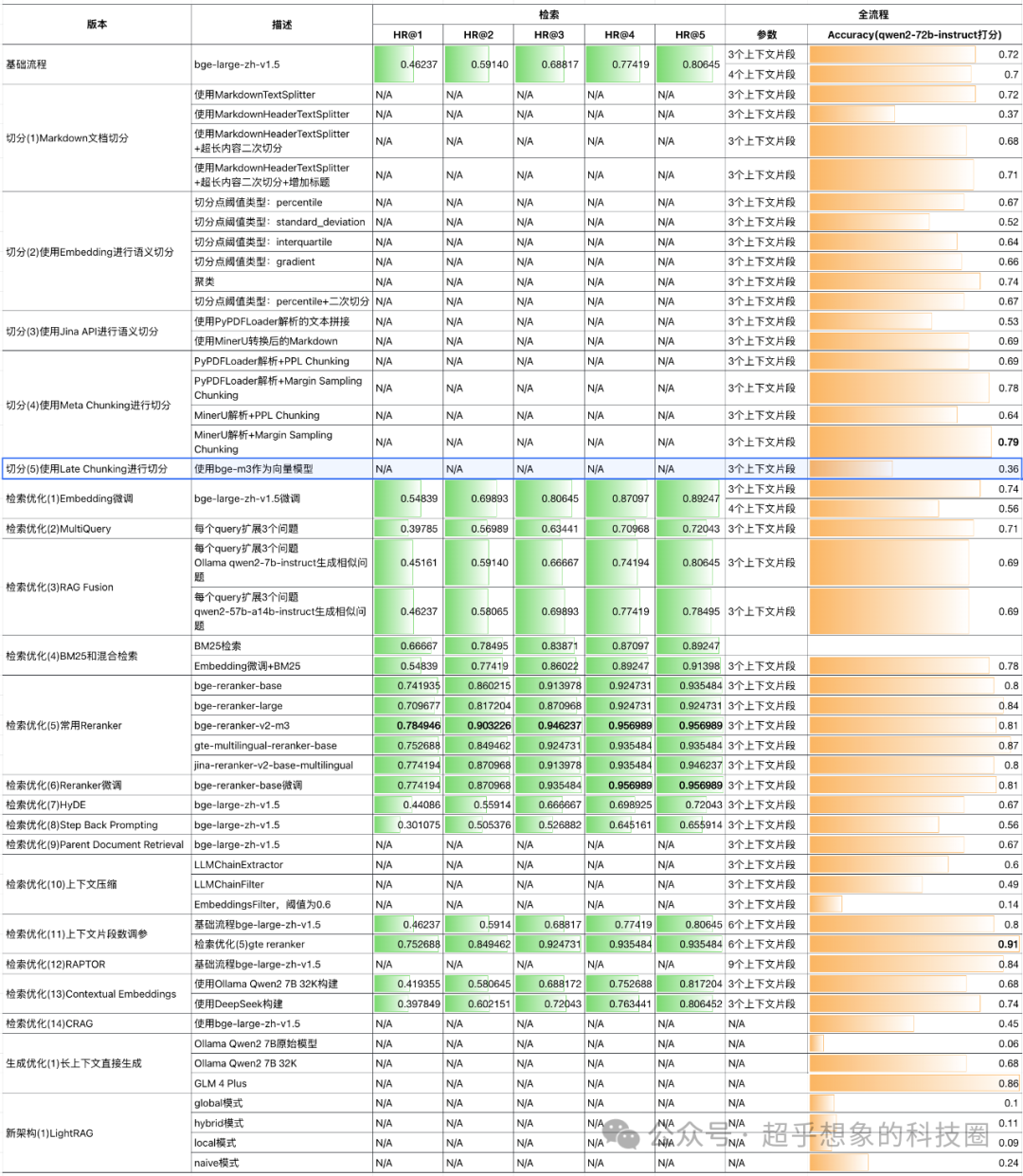
虽然动机看起来站得住脚,原理好像也说得通,但实验的结果却表现很差。后文会进行分析。此处不是完全控制变量实验,有两个变量,除了切分方法不同外,向量模型也不同,其余的生成模型、评估模型与其他实验保持一致。
核心代码
本文代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/split/05_late_chunking.ipynb
Late Chunking最核心的部分,其实不是切分动作在前还是在后,而是片段中的向量表示,要能融合上下文。源代码提供的是按照英文句子、token数等方式的切分,与中文习惯差异较大,所以本文中的实现还是按换行进行了切分,但每个片段的Embedding使用的是融合了整个文档语意信息的。
结果分析
考虑到我们的测试集是中文的,而Jina的官方代码是英文的,所以我一度以为是我的实现有bug,但对英文的数据分析后,发现同样存在一样的问题。
此处只展示最关键的分析,更多分析大家可以查看分析部分的源代码:https://github.com/Steven-Luo/MasteringRAG/blob/main/split/05_late_chunking_en_debug.ipynb
对于一个知识库片段,使用它自身作为Query去检索,如果只保留Top1,绝大多数情况下应该检索到它自身才对,而在Late Chunking中却不是这样。
下面的分析使用维基百科中DeepSeek词条的部分文本作为知识库,使用Jina公布的代码切分得到片段,然后分别拿每个片段作为Query,分别过Embedding模型得到Query的向量,与作为知识库片段的向量两两之间计算相似度,从这个结果来看,最相似的片段,并不总是自己,前5个句子,似乎都跟第一个句子最相似。
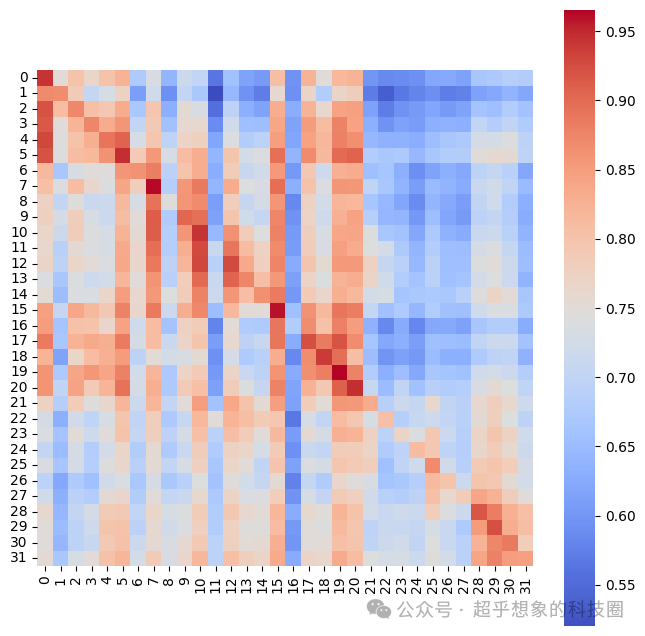
由于Late Chunking是将整个片段每个位置的hidden state做平均,所以可以想想,短句、代词较多的句子,应该会跟其他句子更相似。简便起见,此处检查句子长度。
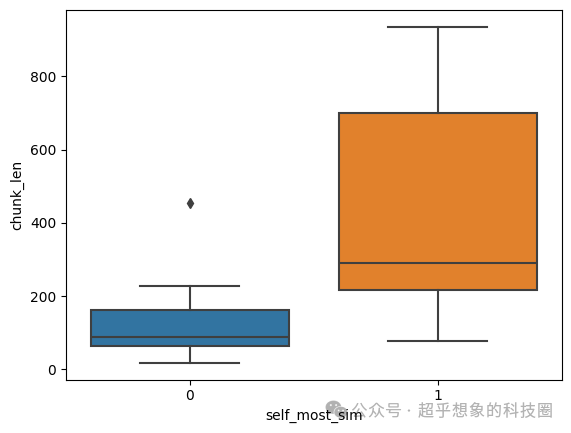
下图中,横轴的0表示以每个片段作为Query,最相似的不是自身,1表是是自身,从结果可以看出,长句普遍都和自身最相似,而短句则和其他句子最相似。这也好理解,因为短句大都要借助前面的内容作为上下文,其中会有相对较多的代词。
从RAG全流程评估结果和英文的分析结果来看,这种方法似乎不是一种非常通用的能提升切分效果的方法,欢迎大家尝试,如果发现了我代码中的bug,欢迎反馈。
往期文章
数据准备
使用RAG技术构建企业级文档问答系统之QA抽取
Baseline
使用RAG技术构建企业级文档问答系统之基础流程
评估
使用TruLens进行评估
使用GPT4进行评估 解析优化 解析(1)使用MinerU将PDF转换为Markdown 切分优化 切分(1)Markdown文档切分 切分(2)使用Embedding进行语义切分 切分(3)使用Jina API进行语义切分 切分(4)Meta Chunking
检索优化
检索优化(1)Embedding微调
检索优化(2)Multi Query
检索优化(3)RAG Fusion
检索优化(4)BM25和混合检索
检索优化(5) 常用Rerank对比
检索优化(6) Rerank模型微调
检索优化(7)HyDE
新架构(1)LightRAG
