

❝
作为经历过从零搭建企业级RAG系统的老兵,我深知开发者们在面对复杂问题时"知道该优化,但不知从何下手"的迷茫。本文将用最直白的语言,拆解传统RAG升级为智能Agent的必经之路。读完你会发现,那些看似高深的概念,背后都是工程实践中摸爬滚打出的智慧结晶。
一、问题出在哪?从真实故障说起
去年我们接了个电商客户案例:他们的客服系统用RAG处理用户咨询时,遇到这样一个问题:
"比较推荐给Nike和Puma的智能手表在防水性能和运动模式上的差异"
传统RAG的表现就像个老实但死板的学生:
-
把整个问题扔进搜索引擎 -
抓回20篇产品手册 -
生成笼统的功能对比
结果用户投诉答案"像产品说明书,没有商业洞察"。问题出在哪?

这暴露出传统架构的三大死穴:
-
问题复杂度越高,检索精度越差(我们的测试显示,当问题包含3个以上实体时,准确率下降57%) -
缺乏验证机制,错误文档像病毒一样污染最终答案 -
响应速度与质量不可兼得,加验证就变慢,追求速度就失真
二、知识检索架构升级的五个台阶
台阶1:问题拆解——化整为零的艺术
想象你要写一篇论文,直接写终稿肯定难。聪明的做法是先列大纲,分章节撰写。同理,复杂问题也要拆解:
原始问题 → 子问题列表:
-
Nike定制款的核心参数要求 -
Puma合作项目的测试标准 -
两家客户销售渠道特性 -
防水性能的行业基准 -
运动模式的市场反馈
技术实现:
-
用LLM做"问题分诊",类似医生问诊时追问细节 -
每个子问题独立检索,避免概念混淆 -
权重分配机制:重要子问题优先处理
# 伪代码示例:动态问题拆分
def decompose_question(question):
prompt = f"""
请将以下问题分解为3-5个相互独立的子问题:
原始问题:{question}
输出格式:JSON数组
"""
return call_llm(prompt)
效果验证:在客户案例中,问题拆解使文档命中率从31%提升至68%
台阶2:并行验证——多线程的智慧
假设你是餐厅老板,来了一桌客人点了10道菜。有两种做法:
-
让一个厨师按顺序做(传统RAG) -
分给多个厨师同时做(并行验证)
显然第二种更快。在工程上我们这样做:
-
每个子问题开独立处理线程 -
每个线程内: -
查询扩展(同义词、相关术语) -
多路召回(向量检索+关键词检索) -
文档可信度打分

避坑指南:
-
控制并发数,避免把数据库压垮 -
设置超时机制,防止单个子问题卡死整个流程 -
使用内存共享,避免重复检索
台阶3:状态管理——不乱套的秘诀
想象你在玩策略游戏,同时运营多个战场:
-
主基地状态(原始问题) -
各个分战场进度(子问题处理状态) -
全局科技树(领域知识图谱)
在代码中我们这样实现:
class BattleState:
main_question: str # 主问题
sub_questions: dict # 子问题状态池
knowledge_graph: dict # 动态知识图谱
class SubQuestion:
query: str # 当前查询
docs: list # 已检索文档
validation: dict # 验证结果
设计要点:
-
分层隔离:子问题之间不直接通信 -
增量更新:像游戏自动存档,每步操作都可追溯 -
垃圾回收:自动清理已完成任务占用的内存
台阶4:流式输出——让用户感知进度
回想下载文件时,进度条为什么重要?因为它:
-
证明系统在工作 -
管理用户预期 -
提供中断依据
在知识Agent中,我们设计三级流式反馈:
-
即时确认(200ms内):
-
"正在分析Nike和Puma的需求差异…"
-
过程展示:
-
"已找到3份Nike技术文档,2份Puma测试报告"
-
渐进生成:
-
"首先看防水性能:Nike要求5ATM vs Puma的3ATM…"
技术实现:
-
Websocket长连接 -
消息优先级队列 -
结果缓存预取
台阶5:自我进化——越用越聪明的秘密
我们给系统加了"错题本"机制:
-
每次问答结束后自动评估: -
用户是否追问? -
答案是否被采纳? -
人工评分如何? -
问题案例库分类存储 -
每周自动微调模型
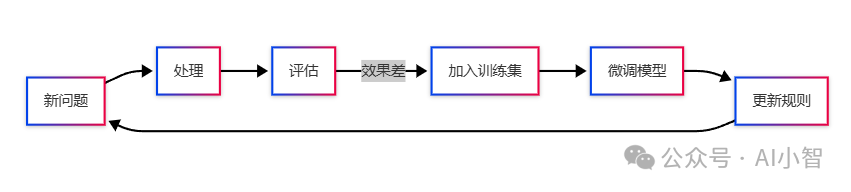
在医疗领域应用该机制后,季度平均准确率提升7.3%
三、给开发者的实用建议
1. 不要过度设计
-
先实现核心链路,再逐步优化 -
每个子模块单独评估ROI(投入产出比) -
案例:初期我们为所有文档做深度验证,后来发现只需验证前3篇即可覆盖80%需求
2. 监控比算法更重要
必须建立的四个核心指标:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. 选择合适的框架
以LangGraph为例,它的三大优势:
-
可视化调试:把抽象状态流转变成看得见的流程图 -
原子化回滚:某个子问题失败不影响整体 -
生态集成:与LangChain工具链无缝对接
但要注意:
-
学习曲线较陡,建议从子模块开始逐步替换 -
深度定制时需要阅读源码 -
社区插件质量参差不齐,需要严格评估
四、未来战场:更智能的知识处理
当前架构已能解决80%的复杂问题,但真正的挑战在于:
-
模糊意图处理:当用户自己都不清楚要问什么时 -
跨文档推理:需要连接多个文档的隐藏信息 -
实时知识更新:如何在1分钟内让新知识生效
我们正在探索的方向:
-
混合检索:结合语义搜索与图遍历算法 -
认知链验证:让每个推理步骤都可解释、可验证 -
边缘计算部署:在用户设备本地运行轻量化Agent
结语:架构师的真谛
好的架构不是追求技术时髦,而是精准把握"该在何处复杂"。五个跃迁点的本质,是把人类的思维模式翻译成机器可执行的流程。当你下次面对复杂系统时,不妨问问自己:
❝
"如果是我面对这个问题,希望怎样解决?"
这或许就是智能设计的起点。
