
WASP:基于加权多预训练语言模型融合的对比式隐私数据合成
摘要:数据规模与质量是构建优质训练数据集的黄金准则,而样本隐私保护同样关键。在确保差分隐私(DP)这一形式化隐私保障的前提下,生成与高质量隐私数据相似的合成样本,具有可扩展性和实用价值。然而,现有基于预训练模型的数据合成方法在数据稀缺场景中表现欠佳,面临样本规模受限、生成噪声难以避免以及预训练模型偏差等问题。为此,我们提出 WASP 框架——一种基于加权多预训练语言模型(PLM)融合的对比式隐私数据合成方法。WASP 通过 Top-Q 加权投票机制,利用有限隐私样本实现更精准的隐私数据分布估计,并通过动态加权的多预训练模型协作,借助低质量合成样本进行对比式生成。在 6 个成熟数据集、6 个开源与 3 个闭源 PLM 上的实验表明,WASP 在提升多样化下游任务模型性能方面具有显著优势。代码已开源在 https://github.com/Lindalydia/WASP 。
一

引言
在 AI 模型与智能体快速发展的背景下,无论是大语言模型(LLMs)还是小规模任务专用模型(STMs),其性能都依赖于高质量训练数据的丰富性,然而实际可用的样本量往往有限。更复杂的是,跨学科任务如医疗记录摘要、个性化减重聊天机器人和指令微调 LLM 都依赖于从真实用户处收集的高质量隐私数据,这不可避免地带来显著的隐私问题。
差分隐私合成数据通过生成与真实隐私数据集相似的新数据集,同时为每个样本提供 DP 保障,成为了一种有前景的解决方案。当前生成 DP 合成数据的研究主要分为两类:第一类工作采用 DP-SGD 对预训练语言模型(PLM)进行微调,但这种方法计算成本高且需要大量数据进行有效微调;第二类工作——隐私进化(PE)则无需微调,仅通过预训练模型的API在隐私样本的 DP 保护指导下生成数据。这种基于 API 的特性使得 DP 合成数据生成更高效,并能同时利用开源和闭源预训练模型,使 PE 成为更实用的解决方案。
尽管现有 PE 方法有效,但这类方法仍面临三大挑战:
-
隐私样本稀缺:现有 PE 方法依赖至少数千个隐私样本以保证可靠的生成反馈选择,但实际场景中数据源可能仅提供数百个样本,导致选择指导信号含噪;
-
合成数据噪声:尽管 PE 方法鼓励生成接近真实隐私分布的高质量样本,低质量噪声样本仍不可避免,影响下游模型性能;
-
PLM 选择风险:不同 PLM 在不同任务中表现差异显著(见图1(b)),而现有 PE 工作主要关注单 PLM 设置,多 PLM 协作潜力尚未开发。
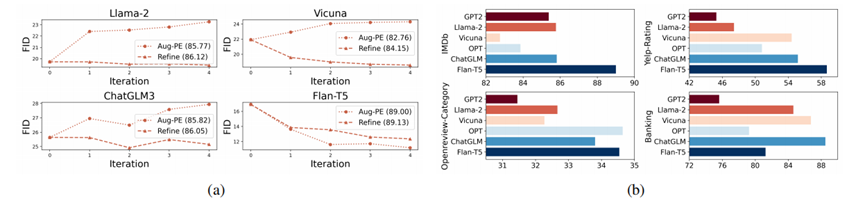
图1:
(a) 使用Top-$Q$投票前(Aug-PE)后(Refine)的合成数据与真实隐私数据相似度度量(FID)以及训练的小型任务专用模型的任务表现(括号中数据)对比;
(b) 使用不同 PLM 生成合成数据训练的小型任务专用模型的任务表现对比。
针对这些挑战,我们提出 WASP 框架——通过加权多 PLM 融合实现对比式 DP 数据合成:
-
为解决隐私样本稀缺问题,将 PE 中的 Top-1 投票扩展为 Top-Q 衰减加权投票,在保证 DP 前提下提升隐私分布估计精度;
-
为降低噪声,利用投票结果筛选高/低质量样本,构建包含对比样本的提示词,引导生成更贴近高质量样本、远离低质量样本的数据;
-
为缓解模型偏差,基于隐私样本的集成投票动态调整各 PLM 权重,优先选择任务能力更强的 PLM。通过迭代生成,WASP 能在保证 DP 的前提下生成更贴近真实隐私分布的大规模合成数据,且 API 调用量与单 PLM 方法相当。
本文贡献如下:
-
提出隐私保护的协作框架 WASP,促进多 PLM 与隐私样本的协同,特别适用于隐私数据稀缺场景;
-
提出差分隐私 Top-Q 投票机制,利用有限隐私样本提升分布估计精度,通过对比高/低质量样本生成更优数据,并动态分配 PLM 权重;
-
在 6 个自然语言处理任务、6 个开源与 3 个闭源 PLM 上的实验验证了 WASP 的持续优越性,尤其在挑战性任务中表现突出。
二
理论基础
(一) 差分隐私(DP)
若两个数据集 $mathcal{D}$ 和 $mathcal{D}'$ 仅相差单个条目,则称为相邻数据集。机制 $mathcal{M}$ 满足 $(epsilon,delta)$- 差分隐私,当且仅当对任意相邻数据集 $mathcal{D},mathcal{D}'$ 及 $mathcal{M}$ 的任意输出子集 $E$,满足:
$$
Pr[mathcal{M}(mathcal{D}) in E] leq e^{epsilon} cdot Pr[mathcal{M}(mathcal{D}') in E] + delta.
$$
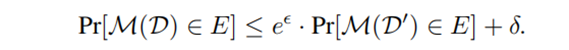
需注意,对 $(epsilon,delta)$-DP 机制输出的后处理不会引入额外隐私损失。
(二) 高斯机制
通过向统计量添加服从 $mathcal{N}(0, sigma^2)$ 的高斯噪声可实现 $(epsilon,delta)$-DP,其中 $sigma = Delta sqrt{2 ln(1.25/delta)} / epsilon$,$Delta$为机制 $mathcal{M}$ 的敏感度。
三
方法论
(一) 问题定义
本文目标是通过少量隐私数据 $mathcal{B} = {(mathbf{z}_j, u_j)}_{j=1}^M$ 生成 DP 合成数据集 $mathcal{D} = {(mathbf{x}_i, y_i)}_{i=1}^N$,并利用 $K$ 个黑盒 PLM 的 API 协作实现。具体而言:
$mathbf{z}_j, u_j$表示隐私样本$j$的特征和标签;
使用$mathcal{D}$训练小型任务专用模型(STM)$m$,并在未参与训练的真实测试集$mathcal{A}$上评估性能;
-
$M$ 表示隐私数据的数量,通常至多数百;
-
$mathbf{z}_j, u_j$ 表示隐私样本 $j$ 的特征和标签;
由于本文主要考虑隐私数据数量不足的场景,因此本文 $M$ 通常至多数百。
为实现这上述目标,我们通过 API 调用 $K$ 个黑盒预训练语言模型 ${mathcal{P}_k}_{k=1}^K$ 的协同生成能力,同时通过高斯差分隐私(Gaussian DP)机制保护隐私数据。在评估阶段,我们使用合成数据集 $mathcal{D}$ 训练一个小型任务专用模型(STM)$m$,并在包含真实样本的测试集$mathcal{A}$上评估模型性能,该测试集在训练过程中从未被使用过。
同时,这套框架可扩展至联邦数据场景(各数据方持有非独立同分布隐私数据),详见 3.3 节。

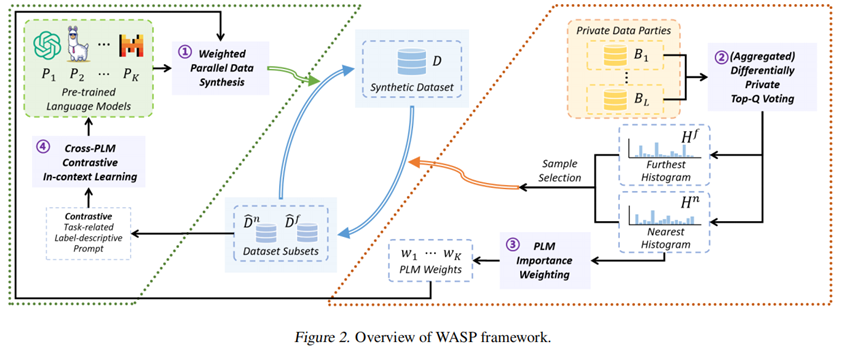
(二)WASP 整体流程
WASP 的工作流程如图 2 和算法 1 所示,共迭代执行 $T$ 轮,每轮包含四步:
1. 加权并行数据生成(算法 1 行 4-6):
-
各 PLM $mathcal{P}_k$ 根据权重 $w_k$ 生成 $N_k = lfloor (N/T) times w_k rfloor$ 个样本,初始迭代使用零样本提示,后续使用对比式上下文提示;
-
生成公式如下,其中 $mathcal{T}(cdot)$ 为生成提示:
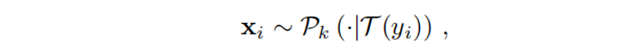
-
初始迭代:所有PLM使用零样本提示T(⋅)T(⋅)(描述任务和类别标签),权重均匀分配wk=1/Kwk=1/K;
-
后续迭代:使用对比式提示T(⋅)T(⋅),包含从D^nD^n和D^fD^f中随机选择的高/低质量样本,并添加以下指令:
(1)分析高低质量样本差异;
(2)确保新样本质量优于高质量样本且远离低质量样本;
(3)鼓励生成表达多样化的新样本。
2. 差分隐私Top-Q投票(算法 1 行 7-8):
-
计算隐私样本 $(mathbf{z}_j, u_j)$ 与同标签合成样本的 $ell_2$ 距离:
$$d(mathbf{z}_j, mathbf{x}_i) = |varphi(mathbf{z}_j) – varphi(mathbf{x}_i)|_2 $$
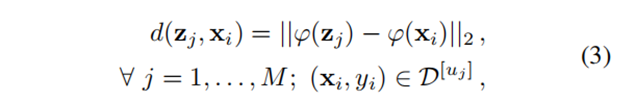
-
对每个分类中距离最小的 $Q$ 个样本、以及距离最大的 $Q$ 个样本投票。首先选取 Top-Q 最近(`topQ Smallest`)和最远(`topQ Largest`)合成样本如下公式所示。其中, $mathcal{D}^{[u_j]}$ 为标签都是 $u_j$ 的样本集合。
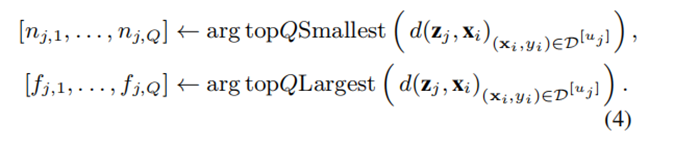
-
对选出的隐私样本进行权重衰减的加权投票,投票权重随着距离排名的增加指数衰减。即,衰减权重为 $1, frac{1}{2}, ldots, frac{1}{2^{Q-1}}$ 一次控制函数敏感度,确保 DP 可行性。使用这个权重更新最近直方图 $H^n$ 和最远直方图 $H^f$;
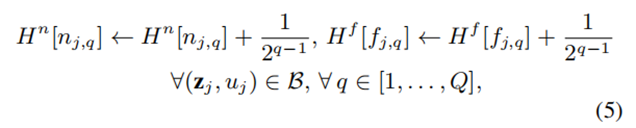
-
添加高斯噪声 $mathcal{N}(0, sigma^2)$ 以满足 DP,其中 $sigma = 4 sqrt{2 ln(1.25/delta_{iter})} sqrt{T-1} / epsilon$。
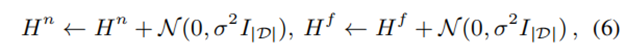
-
按类别 $c$从$H^n$和$H^f$ 中分别选择投票最高的 $S$ 个高/低质量样本,构成对比提示集 $hat{mathcal{D}}^n$和$hat{mathcal{D}}^f$。
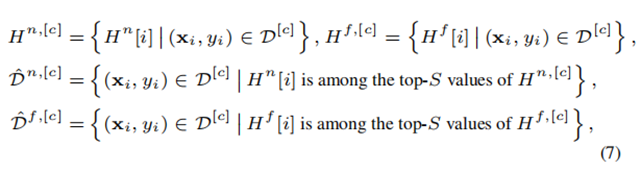
3. PLM 重要性加权(算法 1 行 10):
-
根据$H^n$计算各PLM权重,权重反映PLM生成样本与隐私数据的平均相似度。 每轮迭代后根据最新投票结果更新权重,使优质PLM在后续生成中贡献更多样本。
$$ w_k = frac{sum_{(mathbf{x}_i,y_i)inmathcal{D}_k} s_i}{|mathcal{D}_k| / |mathcal{D}|}, quad s_i = frac{H^n[i]}{sum_{i'=1}^{|mathcal{D}|} H^n[i']} $$
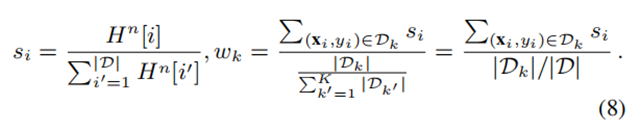
4. 跨 PLM 的对比式上下文学习(算法 1 行 5)
-
受 PE 方法生成的差分隐私合成数据集中仍存在低质量样本现象的启发,我们从$hat{mathcal{D}}^n$和$hat{mathcal{D}}^f$(4.5 节所得)中筛选跨 PLM 对比样本,构建任务相关、标签描述的对比式提示模板 $mathcal{T}(cdot)$,实现跨 PLM 对比式上下文学习。该提示模板包含以下序列化指令:
(1)差异分析:解析高低质量样本间的差异;
(2)质量约束:确保新样本质量优于给定高质量样本,更贴近真实隐私分布,同时与低质量样本的差异度高于高质量样本;
(3)表达多样性:生成在表达方式上区别于给定高质量样本的新样本。
-
为提升生成多样性,每次生成时从 $hat{mathcal{D}}^{f,[c]}$和$hat{mathcal{D}}^{n,[c]}$ 中分别随机抽取 50% 样本构建 $mathcal{T}(c)$ 的最终上下文示例。与 PE 系列算法不同,我们避免逐次修改单个现有样本,而是通过一次性使用 $S$ 个示例鼓励多样化生成。
最后,本文给出WASP的安全性定理及证明。
定理4.1:WASP(算法1)满足隐私预算为$epsilon$的差分隐私。详细证明见论文原文:openreview.net/pdf?id=CPOFZJ8DlT。
(三)WASP 在联邦数据场景下的应用
WASP 算法框架除了可以在单数据方设定下工作,页可轻松扩展至联邦数据场景。在此场景中,每个数据方仅持有少量隐私数据,并通过协作完成隐私任务。这种设定在现实场景中极为常见,例如医疗公司间的联合研究。
具体而言,我们考虑存在( L )个数据方({mathcal{C}_l}_{l=1}^L),每个数据方持有真实隐私数据集(mathcal{B}_l = {(mathbf{z}_{l,j}, y_{l,j})}_{j=1}^{M_l})(规模为( M_l ))。这些数据方的目标是协作生成一个**差分隐私合成数据集**,同时保护本地数据隐私。完整算法详见算法2。
当扩展至联邦数据场景时,各数据方(mathcal{C}_l)使用本地隐私样本 (mathcal{B}_l) 执行**差分隐私 Top-Q 投票**,其中噪声参数设置为:
$$ sigma = frac{4sqrt{2 ln(1.25/delta_{iter}) sqrt{T-1}}{epsilon sqrt{L}} $$
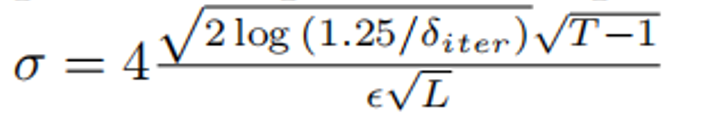
以此保障隐私。生成的本地最近邻与最远邻投票直方图({H_l^n}_{l=1}^L)和({H_l^f}_{l=1}^L)将通过安全聚合协议汇总。


四
实验分析
(一) 实验设置
1. 模型选择
-
开源 PLM:GPT-2-xl、Llama-2-7b-chat-hf、Vicuna-7b-1.5v、OPT-6.7b、ChatGLM3-6b-base、Flan-T5-xl;
-
闭源 PLM:GPT-3.5-turbo-instruct、GPT-4-turbo-preview、GPT-4o;
-
下游小型任务模型(STM):基于 BERT-base-uncased 微调的分类模型;
-
嵌入模型:sentence-t5-base(用于特征距离计算)。
2. 数据集
实验覆盖 6 个任务:
-
IMDb(电影评论情感分析,2 类);
-
Yelp-Category(商业评论领域分类,10 类);
-
Yelp-Rating(商业评论评分分类,5 类);
-
Openreview-Category(论文评审领域分类,12 类);
-
Openreview-Rating(论文评审推荐等级分类,5 类);
-
Banking(银行查询分类,选自 Banking77 的 10 类)。
3. 基线方法
-
Aug-PE:基于单 PLM 的文本生成 PE 方法;
-
Pre-Text:联邦数据场景下的 PE 扩展;
-
OnlyPrivate:仅用隐私数据进行集中式训练(无 DP,性能上界);
-
FuseGen:零样本多 PLM 融合方法;
-
DP-SGD+Gen:DP 微调 PLM 之后进行数据生成的方法。
4. 实现细节
-
隐私设置:默认总样本量 $M=100$(单数据方),$L=10$ 时(联邦场景),总样本量 $M=300$;使用 Dirichlet 分布划分非独立同分布数据($alpha=1.0$);
-
合成数据量:$N=6,000$,分 $T=5$ 轮生成;
-
隐私参数:默认使用样本级 DP(sample-level DP);主实验及消融实验中默认使用$delta_{iter}=1times10^{-5}$,$epsilon=4.0$。
(二)主要结果
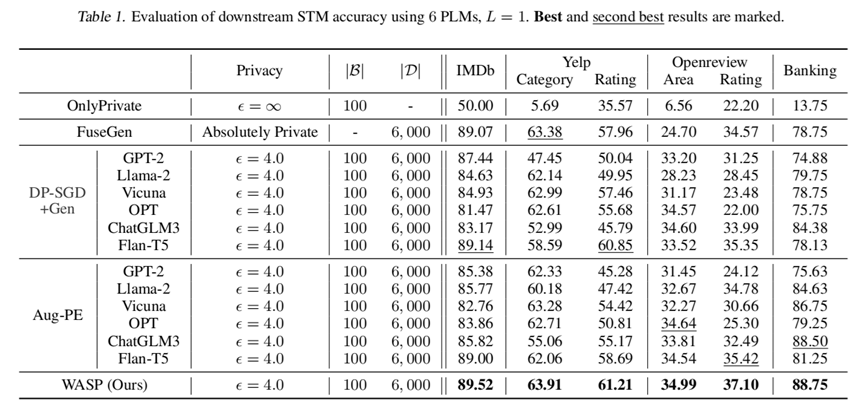
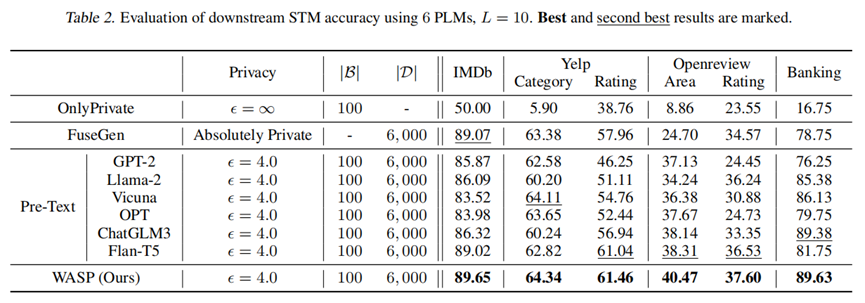
1. 单数据方场景(表 1,3)
-
在 6 个任务中均超越基线,例如 Openreview-Rating 任务准确率提升 1.68%(37.10% vs. Aug-PE 最佳35.42%);同时,强大的闭源 PLM 也会带来更优的性能。例如,在 Yelp-Rating 数据集中,使用 Aug-PE 时,GPT-4o 表现最佳。
-
在所有任务中,当使用不合适的单预训练语言模型(PLM)时(例如在 IMDb 任务中使用 OPT 模型、在 Openreview-Rating 任务中使用 GPT-2 模型),Aug-PE 在隐私样本有限的情况下表现欠佳。与之不同,WASP在跨任务中表现稳定,且相较于基线方法实现了更低的FID值(参见论文原文openreview.net/pdf?id=CPOFZJ8DlT 附录 E.1 图 5),验证了其在隐私样本稀缺场景下的有效性。此外,Aug-PE 中最佳 PLM 模型因任务而异,凸显了 PLM 选择的随意性;而 WASP 无需依赖先验知识选择特定 PLM 协作,即可跨任务持续取得更优性能,表现出 PLM 无关性(PLM-agnostic)。
-
另一方面,与零样本设定下无法访问隐私数据的基线方法 FuseGen 相比,WASP 通过利用真实隐私样本及更具针对性的 PLM 重要性加权方法,实现了更优性能。此外,“OnlyPrivate”(仅用隐私数据)方法的显著低效表明,完全依赖隐私数据集 $mathcal{B}$ 训练的 STM 几乎无法使用——即使未在训练中应用差分隐私(DP),其性能也会进一步恶化。
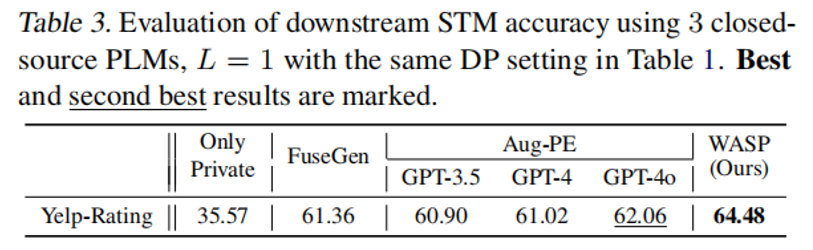
2. 联邦数据场景(表 2)
-
表 2 结果显示,相较于专为联邦数据设计的基线方法 Pre-Text,WASP 在不同任务与设定下均表现更优,这进一步验证了其扩展至联邦数据场景的有效性。
3. 计算与通信开销
-
计算开销方面,WASP 的计算复杂度与 PE 系列基线方法同阶,并且测算的运行时(单位秒 s)与上述基线方法非常接近。这说明,WASP 在提升性能的同时,没有引入过多的计算开销。
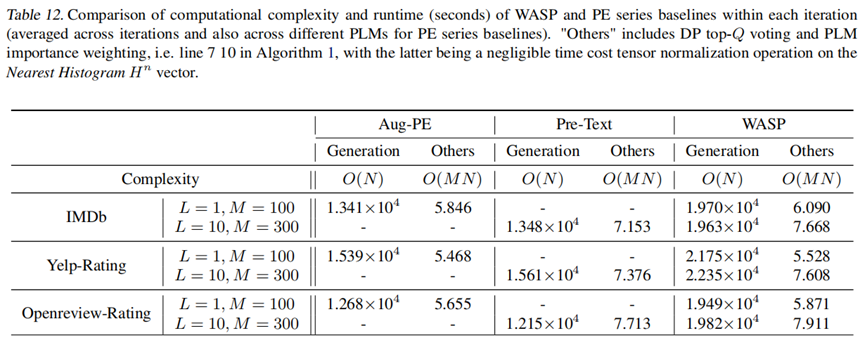
-
通信开销方面,WASP 仅需额外传输 $L$个$N$ 维向量,因此通信量增幅几乎可忽略。

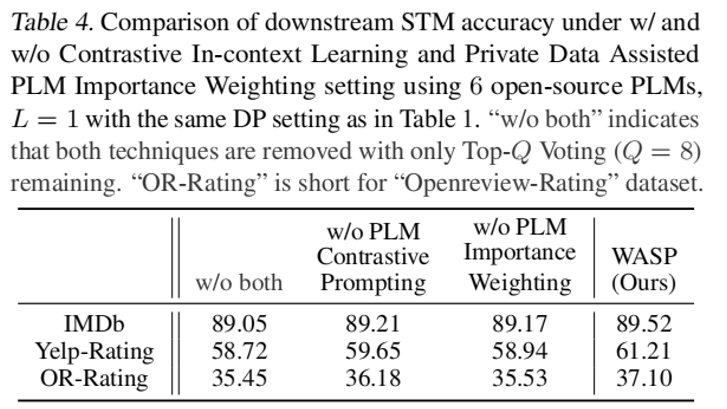
(三) 消融实验
1. 各部分有效性(表 4)
-
可以看到,对比式上下文学习以及 PLM 动态加权都对于提升最终的小型任务模型在任务上的表现有帮助作用。
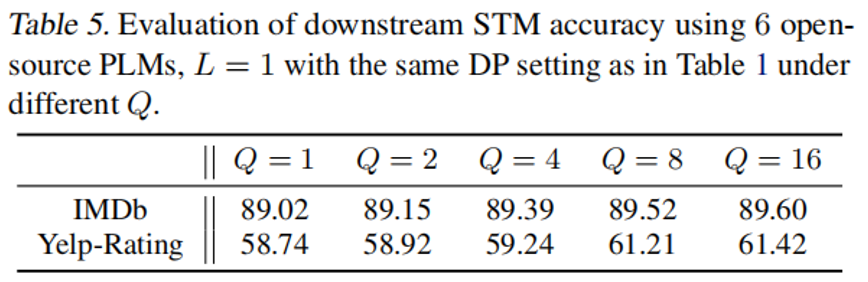
2. 投票数 $Q$ 影响(表 5)
-
可以看到,增大 $Q$ 可提升小型任务模型的最终性能,验证了差分隐私 Top-Q 投票的有效性。但 $Q>8$ 时收益饱和。
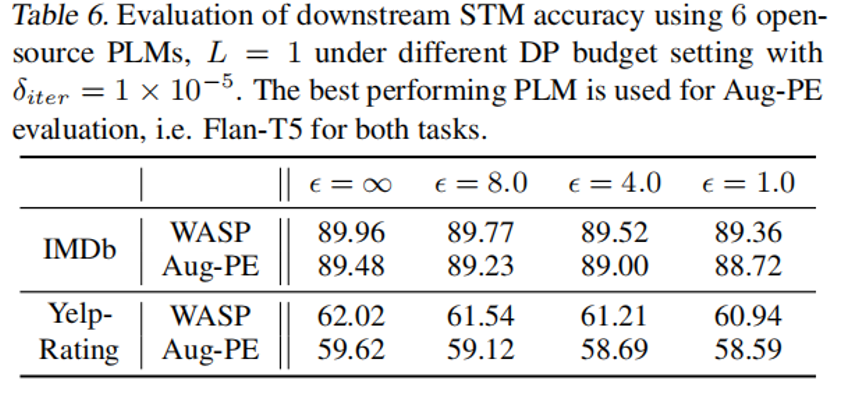
3. 隐私预算 $epsilon$ 敏感性(表 6)
-
在比较宽松的隐私预算($epsilon=8.0$)下,WASP 性能接近非隐私场景($epsilon=infty$);
-
在比较严格的隐私预算($epsilon=1.0$)下,WASP 性能下降可控。
五
结论与未来工作
本文提出了一种新颖的差分隐私(DP)合成数据生成框架 WASP,该框架通过利用多个预训练语言模型(PLM)的协同能力,解决现实场景中隐私样本有限的问题,同时严格遵守差分隐私约束。在 6 个任务上的实验表明WASP具有以下性质:
-
高效性:WASP在各类任务中均表现卓越;
-
PLM 无关性:不依赖特定 PLM 选择;
-
可扩展性:对隐私预算具有良好适应性;
-
挑战场景优势:在复杂任务中显著优于基线方法。
这些特性使 WASP 成为实际应用中实用且可扩展的解决方案。
未来工作方向包括:
-
精细化样本级加权/选择:通过更精确的样本级权重分配或筛选策略,进一步提升 DP 合成数据集质量;
-
非分类任务验证:探索 WASP 在生成、序列标注等非分类任务中的有效性。
