

今天我们一起来聊聊一篇很有意思的论文,它深入探讨了大语言模型(LLMs)在多轮对话中的表现,提出了一个挺令人担忧的现象——LLMs在多轮对话中,竟然会“迷失方向”。
一、 多轮对话,一个被忽视的挑战?
我们都知道,过去几年的AI发展真是日新月异,特别是以ChatGPT和DeepSeek为代表的LLMs,一下子把我们带入了“AI对话”的新时代。我们跟AI聊天,常常不是问一个问题就结束,而是像跟真人交流一样,来回沟通好几轮,不断补充信息、调整需求。这就是多轮对话。
然而,虽然多轮对话越来越普遍,但现有的大多数针对LLMs的评估方法,却往往把对话看作是一系列可以独立评估的子任务,就像一集一集的电视剧,每集可以单独拎出来看。这种“情景式”(episodic)的评估方式,没有充分捕捉到真实人类对话中的一个关键特征:信息是逐步揭示的,常常是“欠规格的”(underspecification)。也就是说,我们在对话开始时不会把所有需求都说得清清楚楚,而是在后续交流中逐步完善和澄清。
比如,你可能先让AI写一个函数,然后才补充第一个要求,接着想起第三个要求,最后才把第二个要求补上。现有的评估方法很难模拟这种自然的、信息不完整的、逐步补充的对话流程。这就导致了一个问题:我们可能高估了LLMs在复杂、多轮、欠规格对话中的真实能力。 这篇论文的研究动机,就是要弥补这一评估上的不足,深入探究LLMs在这种更接近真实场景的多轮对话中的表现。

二、 LLMs真的会“迷失”?
这篇论文的核心发现非常直观且令人警醒:LLMs在多轮对话环境下的表现远不如单轮对话,平均性能下降了35%。更深入地分析,这种性能下降主要不是因为模型的“能力”(aptitude)大幅下降,而是因为它们变得非常“不可靠”(unreliable)。
论文中定义了两个关键指标来量化这种现象:
-
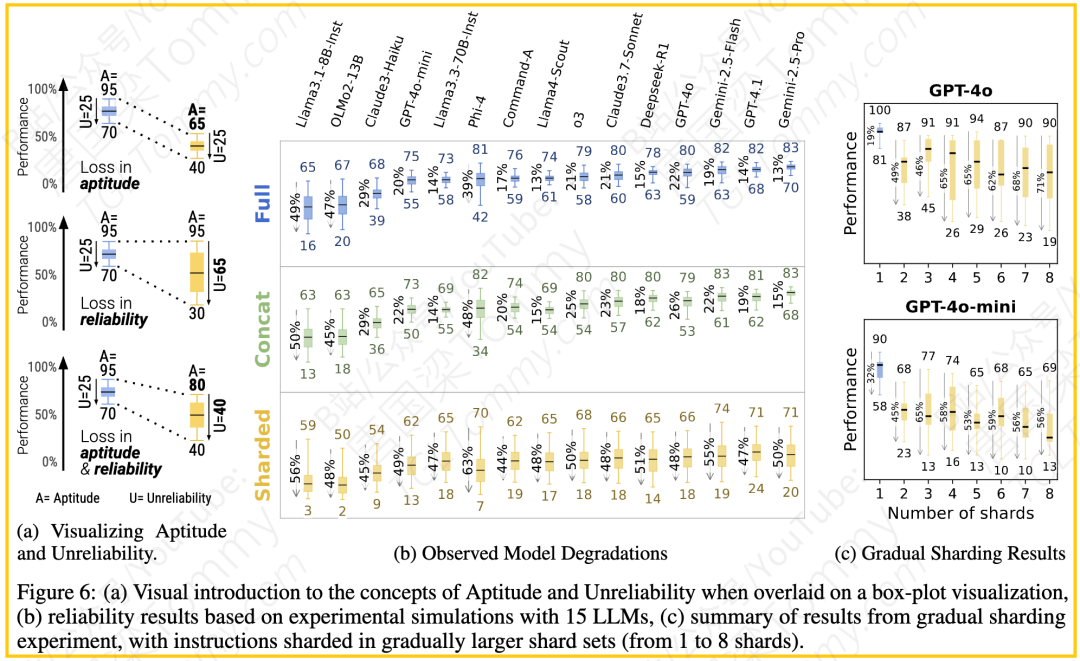
能力 (Aptitude, A90):衡量模型在“最佳情况”对话模拟中的表现,可以理解为模型在某个任务上的“上限”。在图的可视化中,它对应于箱线图上须的顶端高度。
-
不可靠性 (Unreliability, U90-10):衡量模型在最佳情况(90th百分位)和最差情况(10th百分位)模拟表现之间的差距。这个指标越高,说明模型的输出越不稳定,越依赖于随机因素,越容易“翻车”。在图的可视化中,它对应于箱线图上的顶端和底端之间的距离。可靠性(Reliability, R)可以简单理解为 100 – 不可靠性。
研究发现,在多轮欠规格对话(SHARDED)中,LLMs表现出的特点是:能力有所下降,但不可靠性急剧飙升(提高了112%)。这意味着即使是那些在单轮对话中表现出高能力和高可靠性的模型,在面对多轮、信息逐步揭示的对话时,它们的表现会变得极其不稳定。用论文的话说,LLMs在多轮欠规格对话中“迷失了方向”。
论文通过一个形象的例子说明了能力下降和可靠性下降的区别:同样是平均性能从90%下降到60%,可能完全是由于能解决的问题变少了(能力下降),也可能完全是由于在原本能解决的问题上变得不稳定了,时好时坏(可靠性下降),或者两者兼有。而这项研究观察到的情况更接近第三种,可靠性下降对性能损失的贡献远大于能力下降。
三、 方法解析:“分片模拟”环境的构建
为了模拟这种接近真实人类交流的多轮、欠规格对话,论文构建了一个名为“分片模拟”(sharded simulation)的环境。这个环境的核心在于“指令分片”(sharding process)。
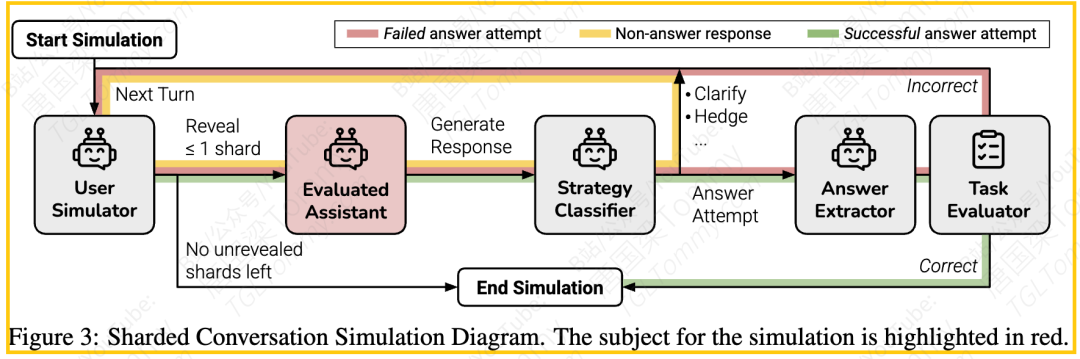
具体来说,研究人员从现有的高质量单轮指令数据集(如代码生成的HumanEval、文本到SQL的Spider、数学题的GSM8K 等)出发。他们设计了一个半自动化的分片流程来构建“分片指令集”。这个流程包括四个步骤:
1. 分割(Segmentation):使用LLM(如GPT-4o)将原始的完整指令分割成更小的信息单元(Atomic Content Units, ACU)。要求分割后的片段不重叠,尽量细化,每个片段代表一个信息单元。
2. 重塑(Rephrasing):再次使用LLM,将分割后的信息单元重塑成更具对话性的“指令分片”(shards)。第一个分片通常是代表高级目标的初始意图,后续分片提供澄清和细节。重塑后的分片应保留原始信息内容,且除了第一个分片外,其他分片应尽可能“去语境化”,使其顺序无关。
3. 验证(Verification):使用LLM验证分片后的指令集是否完整地包含了原始指令的所有必要信息。
4. 人工检查与编辑(Inspect and Edit):研究人员对LLM生成的分片结果进行人工审查、编辑,确保高质量和有效性。这一步是确保数据质量的关键,因为仅依赖LLM输出不足以满足高精度实验的要求。
通过这个流程,一个原本在单轮中给出的完整指令,被转换成了一系列更小的、逐步揭示的指令分片。
在“分片模拟”环境中:
-
系统使用一个基于LLM的用户模拟器 来进行多轮对话。
-
在对话的每一轮,用户模拟器最多揭示一个指令分片。
-
助理LLM接收当前的指令分片以及之前的对话历史,然后生成响应。
-
助理LLMs并没有被告知这是一个多轮、欠规格的对话,也没有被鼓励采取特定的对话策略(例如,先澄清再回答)。这是为了评估模型在默认行为下的表现。
-
助理LLM的响应会被分类(例如,回答尝试、澄清、讨论等)。如果是回答尝试,则会被评估。
-
对话持续进行,直到助理LLM给出正确答案,或者所有指令分片都已揭示完毕。
为了对比,论文还设置了另外两种模拟类型:
-
完全指定(FULL):单轮对话,直接给出原始的、完整的指令。用于评估基线性能。
-
拼接(CONCAT):单轮对话,将分片后的指令简单地拼接在一起,一次性给出。用于验证性能下降是否由指令分片本身导致的信息损失或重塑引起。如果模型在FULL和CONCAT上表现接近,但在SHARDED上表现差,则说明问题在于欠规格和多轮交互本身,而非分片过程。
通过这三种模拟类型,研究人员可以有效地隔离和研究多轮、欠规格对话对LLMs性能的影响。

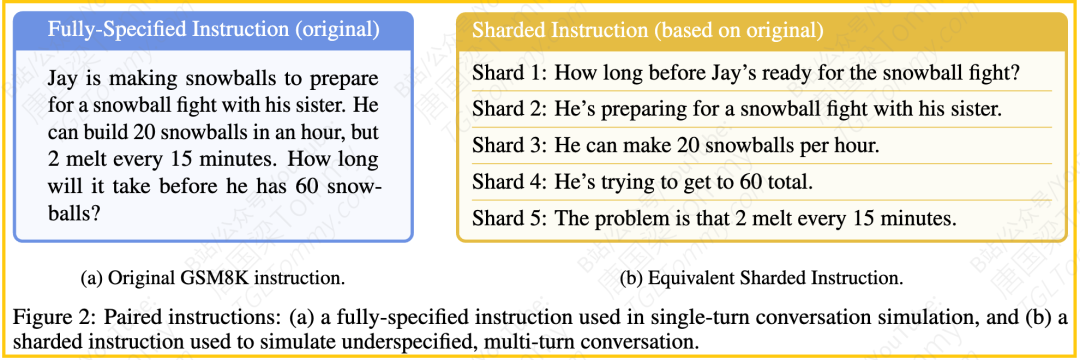
举例-1 :FULLY-SPECIFIED (完全指令)
-
描述:这是传统的单轮对话设置。在这种模拟中,用户指令是“完全指定的”,意味着任务的所有要求和信息都在一轮指令中一次性提供给 LLM。这模拟了一种实验室环境下的理想情况。
-
信息呈现:所有必要的信息都在单轮用户输入中。例如,原始的、完全指定的指令可以是一个长句,一次性引入所有内容,如一个高级问题、上下文和条件。
-
示例:来自 GSM8K 数据集的一个数学问题: "Jay is making snowballs to prepare for a snowball fight with his sister. He can build 20 snowballs in an hour, but 2 melt every 15 minutes. How long will it take before he has 60 snow-balls?"。在 FULL 模拟中,整个问题会在第一轮作为用户指令提供给 LLM。图 5 也展示了其他任务(如 Code, Database, Actions 等)的完全指定指令示例。

举例-2:CONCATENATED SHARDED (拼接):
-
描述:这是一种基于分片指令的单轮模拟。原始的完全指定指令首先被分解成多个“分片”。然而,与多轮设置不同,在 CONCAT 模拟中,所有的分片都被串联(concatenated)起来,形成一个单独的指令,通常以项目列表(bullet-point)的形式呈现。这个串联指令会在一轮中提供给 LLM。
-
目的:CONCAT 模拟旨在作为一个验证基准。通过比较 LLM 在 FULL 和 CONCAT 设置下的表现,研究人员可以判断 LLM 的性能下降是否是由于指令分片过程中可能的信息丢失或改写所致,而不是由于多轮和欠规范的对话本身。如果模型在 FULL 和 CONCAT 上表现相似,但在 SHARDED 上表现差,则表明问题在于欠规范和多轮性。
-
信息呈现:所有分片信息都在单轮用户输入中,但以串联的分片形式呈现。
-
示例:使用与 FULL 示例相同的“滚雪球”数学问题。原始指令被分片成几个更小的部分,例如:
▪ Shard 1: How long before Jay’s ready for the snowball fight?
▪ Shard 2: He’s preparing for a snowball fight with his sister.
▪ Shard 3: He can make 20 snowballs per hour.
▪ Shard 4: He’s trying to get to 60 total.
▪ Shard 5: The problem is that 2 melt every 15 minutes.
在 CONCAT 模拟中,用户指令会将这些分片串联起来,可能形如:“请考虑以下所有要点来完成任务:- 如何准备好打雪仗? – 他正在和妹妹准备打雪仗。 – 他每小时可以做 20 个雪球。 – 他想总共有 60 个。 – 问题是每 15 分钟融化 2 个。” 这样的指令会在单轮中提供给 LLM。

举例-3: SHARDED (分片模拟)
-
描述:这是研究关注的核心多轮、欠规范对话模拟类型。与前两种不同,用户指令是逐步揭示的。原始的完全指定指令被分解成多个分片。在模拟对话的每一轮中,用户模拟器最多只会揭示一个分片的信息给 LLM。
-
信息呈现:信息是逐步通过多轮对话呈现的。第一轮通常提供初始意图(如 Shard 1),后续轮次逐步提供额外的澄清信息(Shard 2, Shard 3 等)。这种方式模拟了现实世界中用户开始时指令欠规范,然后通过多轮交互来进一步明确需求的情境。
-
示例:同样使用“滚雪球”数学问题。分片指令如上所示。在 SHARDED 模拟中,对话会是多轮的:
▪ 回合 1:用户提供 Shard 1: "How long before Jay’s ready for the snowball fight?"
▪ LLM 回应…
▪ 回合 2:用户提供 Shard 2: "He’s preparing for a snowball fight with his sister."
▪ LLM 回应…
▪ 回合 3:用户提供 Shard 3: "He can make 20 snowballs per hour."
▪ 以此类推,直到所有分片信息被揭示或任务完成。图 2 和图 11 展示了 SHARDED 模拟中多轮交互的示例流程,信息在不同回合中逐步增加。
四、 实验结果与分析:迷失的实证证据
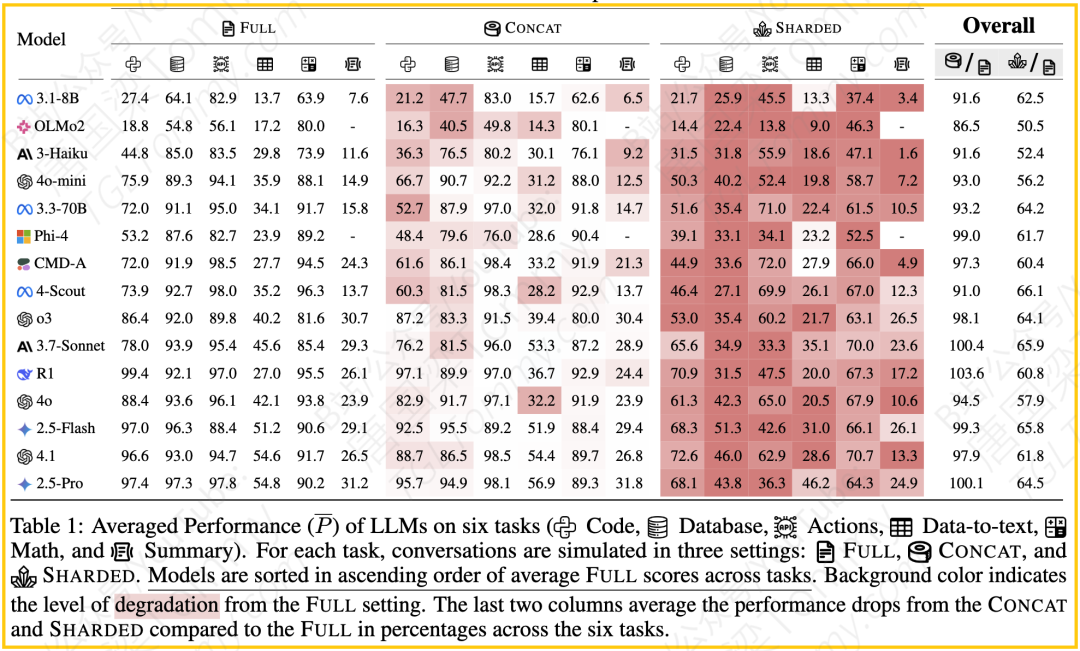
论文在六种不同的生成任务上进行了大规模实验,包括:代码生成 (Code)、数据库查询 (Database, Text-to-SQL)、API调用 (Actions, Function Calling)、数学解题 (Math)、数据到文本 (Data-to-text) 和文档摘要 (Summary)。这些任务涵盖了编程和自然语言生成,使用了各自领域的高质量数据集和评估指标。研究人员共构建了600条分片指令。

他们测试了15个不同的LLMs,包括来自OpenAI (GPT-4o-mini, GPT-4o, o3, GPT-4.1)、Anthropic (Claude 3 Haiku, Claude 3.7 Sonnet)、Google (Gemini 2.5 Flash, Gemini 2.5 Pro)、Meta (Llama3.1-8B-Instruct, Llama3.3-70B-Instruct, Llama 4 Scout) 等知名模型。对于每个模型、每条指令和每种模拟类型,他们都运行了10次模拟以捕捉随机性,总计超过20万次模拟对话。所有模拟默认使用温度 T=1.0 。
关键实验结果如下:
1.性能大幅下降:如前所述,所有模型在SHARDED(多轮欠规格)设置下的平均性能都显著低于FULL(单轮完整)和CONCAT(单轮拼接)设置。平均而言,SHARDED性能仅为FULL性能的65%。这表明多轮欠规格对话确实是LLMs的一个难点。
2.CONCAT vs FULL:CONCAT设置的性能与FULL设置接近,平均达到FULL性能的95.1%。这证实了性能下降的主要原因在于多轮交互和信息逐步揭示(欠规格),而不是分片过程本身可能导致的信息损失或重塑。较小的模型在CONCAT设置下表现出更明显的性能下降(86-92%),这可能说明小型模型对指令的微小重塑更不鲁棒。
3.能力 vs 不可靠性:对能力 (A) 和不可靠性 (U) 的分析(图 6b)显示:
-
在单轮设置(FULL和CONCAT)下,能力越强的模型通常越可靠。
-
然而,在SHARDED设置下,不可靠性急剧增加。例如,原本能力最强的GPT-4.1和Gemini 2.5 Pro,其不可靠性大幅度提升。尽管能力也有所下降,但可靠性的大幅损失是导致平均性能下降的主要因素。这印证了“迷失方向”的说法,模型变得更加不稳定和不可预测。
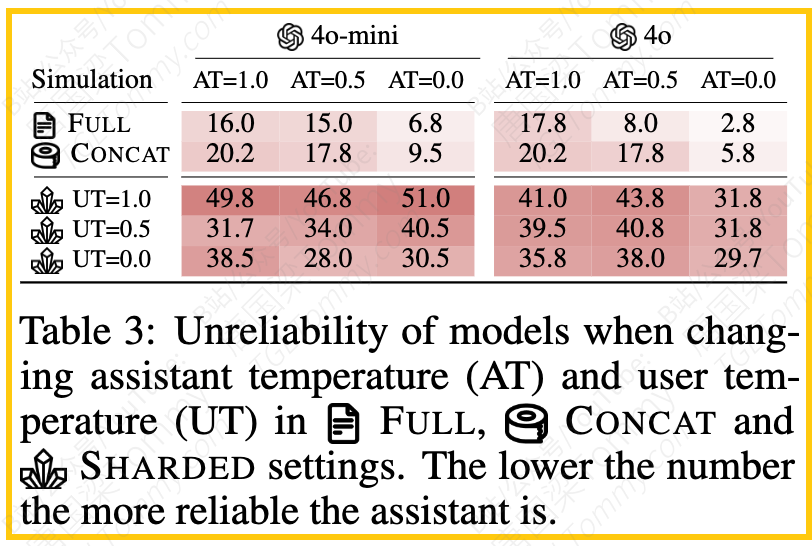
4.温度的影响:研究人员还进行了辅助实验,改变了助理LLM(AT)和用户模拟器(UT)的生成温度。结果显示,在单轮设置(FULL和CONCAT)下,降低温度(AT=0.0)能显著提高模型的可靠性,不可靠性下降50-80%。然而,在SHARDED(多轮)设置下,降低温度对提高可靠性效果微乎其微,GPT-4o-mini几乎没有改善,GPT-4o也只有15-20%的微小提升。即使AT和UT都设为0.0,仍然存在大约30%的不可靠性。这说明多轮对话中的微小偏差会在后续轮次中级联放大,导致即使理论上是确定性的设置也无法保证可靠性。降低温度并不能解决LLMs在多轮交互中的可靠性问题。
5.过早回答的问题:对模拟对话日志的定性分析发现,模型在对话早期就尝试给出完整答案会显著损害性能。等待用户提供更多信息(在对话的后20%进行首次回答尝试)的模型,其平均性能(64.4%)远高于在对话早期(前20%)就尝试回答的模型(30.9%)。这可能是因为模型在信息不完整时做出了错误的假设,这些假设与后续轮次的用户指令冲突,导致最终失败。
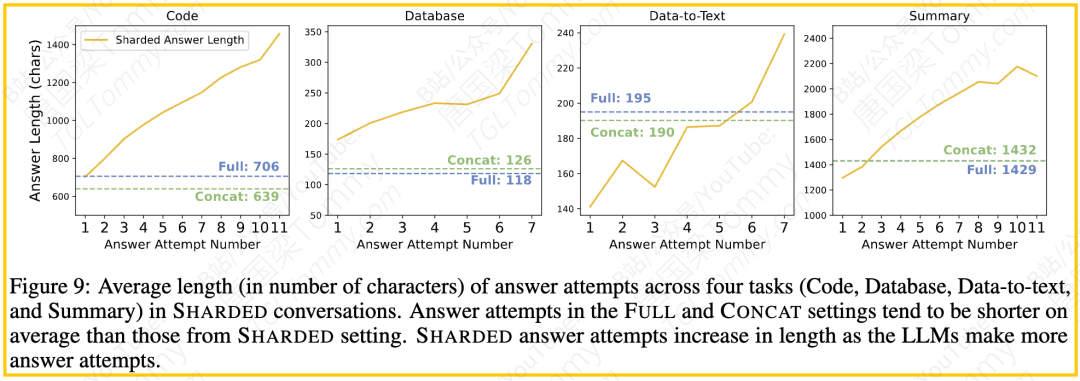
6.“答案膨胀”效应: 在SHARDED多轮对话中,模型可能进行多次回答尝试。随着对话轮次的增加,模型的回答尝试平均长度显著增加,最终回答尝试可能比单轮设置下的答案长20-300%。研究人员将此命名为“答案膨胀”效应。他们推测,这是因为模型在早期尝试中根据不完整信息做出了假设,在后续用户补充信息时,模型没有完全抛弃或纠正之前的假设,而是试图在旧答案的基础上修补和叠加新信息,导致答案变得冗长且可能包含错误或不一致之处。一个数学任务的案例就展示了模型如何在对话中做出不相关的假设,并最终只完成了一半的计算。
7.冗余输出与性能:另一项分析发现,在六个任务中的五个上,模型响应越长(越冗余),平均性能越低。这与“答案膨胀”效应相互印证,说明简洁、准确的响应更有可能成功。只有Actions任务是例外,过短的响应反而有害。
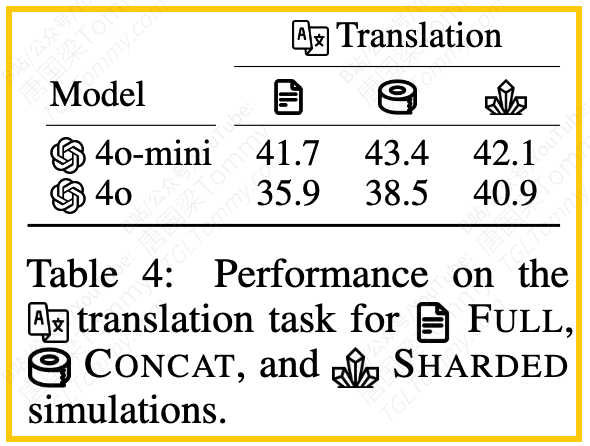
8.翻译任务的特例:有趣的是,在翻译任务上,GPT-4o-mini和GPT-4o在SHARDED设置下没有出现性能下降。论文分析认为,这可能是因为翻译任务即使在文档层面,也可以很大程度上分解为句子级别的独立子任务。如果一个任务本质上是“情景式”的,可以分解成一系列独立的子任务,那么模型就可以通过解决每个子任务来避免在多轮对话中“迷失”。这也反过来佐证了,性能下降是由于任务的“非情景式”和“欠规格”特性导致的,模型需要跨轮次地理解和整合信息。
总的来说,实验结果提供了强有力的证据,表明当前的LLMs在处理需要跨轮次理解、信息逐步完善的欠规格多轮对话时存在严重的可靠性问题,它们难以有效追踪和整合所有信息,容易受到早期假设和历史信息的影响,导致性能不稳定和错误发生。
五、 启示:前路漫漫,任重道远
这篇论文的研究结果对AI社区,特别是LLM的构建者和应用开发者具有重要启示。
-
评估方法的演进:传统的单轮或情景式多轮评估不足以反映LLMs在真实复杂对话中的表现。我们需要更多能够模拟欠规格、跨轮次依赖的对话评估方法,例如本文提出的分片模拟。论文鼓励大家采纳并改进分片流程,构建更多这类评估数据集。
-
模型能力的提升方向:LLM构建者不仅要提升模型在单轮任务上的能力(Aptitude),更要迫切关注其在多轮对话中的可靠性(Reliability)。仅仅提升能力并不能解决多轮对话中的迷失问题。模型需要更好地管理对话状态,跟踪用户需求的变化和补充,避免过早下结论和不必要的假设。防止“答案膨胀”,生成更简洁、准确且及时修正的响应,也是一个重要方向。
-
应用开发的思考:对于基于LLMs构建对话产品的开发者,应当意识到当前模型在复杂多轮对话中的局限性。在设计交互流程时,可能需要加入额外的机制来帮助模型,例如在每一轮或关键轮次对之前的对话内容进行总结或重述(Recap),将所有已知的要求或信息汇总提供给模型,减轻模型的记忆负担。但需要注意的是,简单的用户模拟重述(如论文在附录中探索的Recap和Snowball)并非万灵药,效果有限。也许需要更智能的、由模型自己生成的或由系统辅助的重述机制。
-
用户教育:最终用户也需要了解LLMs在复杂对话中可能表现出的不稳定性,管理好自己的预期。
论文作者强调,由于他们使用的自动化模拟环境相对简化和理想化(例如,对话总能提供足够信息解决任务,用户模拟器行为模式有限),因此实验中观察到的性能下降和不可靠性很可能低估了LLMs在真实世界、更混乱、更少约束的人机对话中“迷失”的程度。
总而言之,虽然LLMs在单轮任务上取得了惊人的成就,但在多轮、欠规格的真实对话场景下,它们仍然面临着显著的挑战。如何让LLMs在复杂、动态的对话流程中保持稳定、可靠、不“迷失”,是未来AI研究和发展亟待解决的关键问题。这篇论文为我们揭示了问题的严重性,并提供了一种有价值的评估工具,为未来的改进指明了方向。
