


-
明确任务需求:开发者需要明确自己的业务需求和预期目标。这包括理解任务的性质、所需的输出类型以及期望的准确度水平。 -
数据集分析:分析可用的数据集,确定它们是否足够丰富,能够覆盖Llama 3需要训练的领域。数据集的多样性和质量直接影响模型的适应性。 -
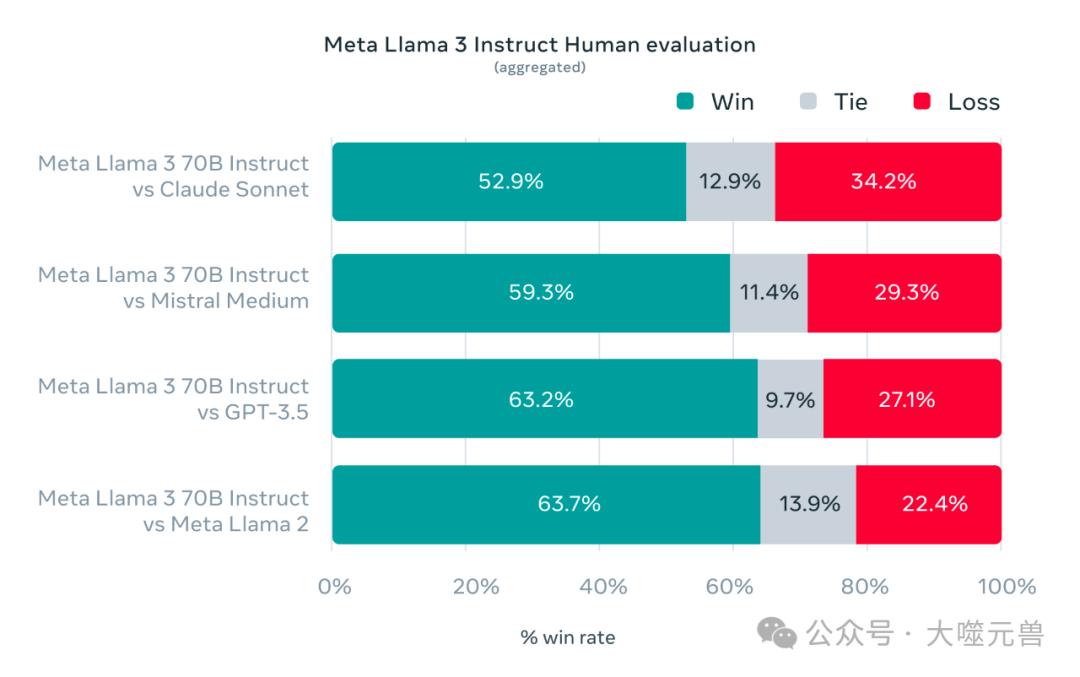
性能基准测试:在特定的数据集上运行Llama 3的基准测试,评估其在各项任务上的表现,如文本分类、问答系统、文本生成等。 -
微调效果评估:对Llama 3进行微调后,评估模型在特定任务上的表现是否有所提升,以及微调是否能够满足特定业务场景的需求。 -
资源消耗评估:考虑到运行大型模型可能需要大量计算资源,开发者需要评估所需资源与预算限制之间的平衡。 -
长期维护:评估模型在长期运行过程中的维护成本,包括定期更新数据、模型迭代和系统稳定性维护。 -
社区和文档支持:考虑到开源社区的支持和文档的完善程度,这些因素将在解决问题和模型优化过程中发挥重要作用。 -
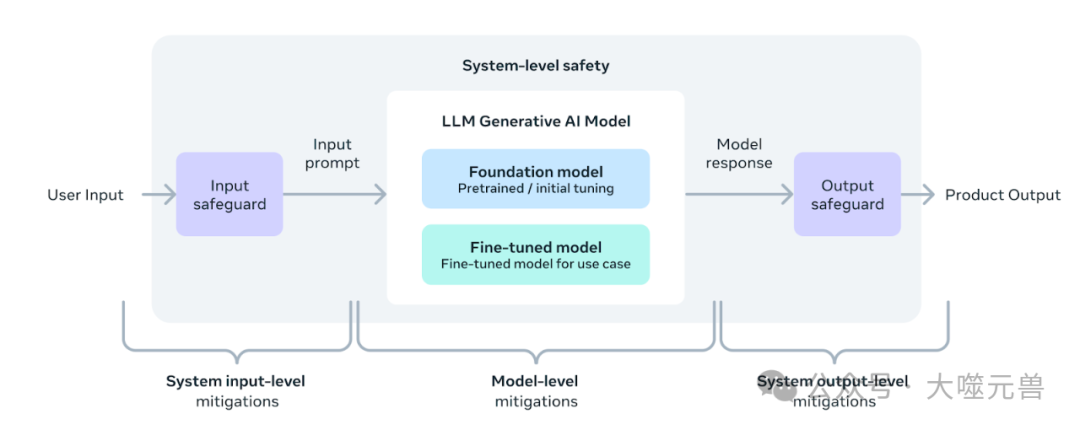
伦理和合规性:确保模型的使用符合伦理标准和法律法规,特别是在处理敏感数据时。 
-
数据准备:收集并准备好与垂直领域相关的高质量数据集。 -
环境设置:确保开发环境中安装了必要的软件和库。 -
模型加载:从Meta Llama网站或Hugging Face平台加载Llama 3模型权重和分词器。 -
选择微调策略:根据任务需求和资源限制,选择合适的微调技术。 -
微调执行:运行微调脚本,开始在特定数据集上训练模型。 -
性能评估:使用验证集评估模型的性能,确保微调效果达到预期。 -
迭代优化:根据评估结果,调整微调策略和参数,进行迭代优化。 -
模型部署:将微调后的模型部署到实际应用中,开始提供服务。
transformers、datasets等。此外,还需要有稳定的网络连接,以便下载模型权重和访问在线资源。
-
访问Meta Llama 3的官方GitHub页面或Hugging Face平台。 -
遵循页面指南,下载模型权重和分词器。
-
确保开发环境中安装了必要的软件和库,如Python、transformers、datasets等。
-
使用适当的代码库加载下载的模型权重和分词器。
-
根据项目需求选择合适的微调策略,如Freeze、P-Tuning或LoRA。 -
在特定数据集上运行微调脚本,开始训练。
-
使用验证集评估模型的性能。 -
根据评估结果调整微调策略和参数。
-
将微调后的模型集成到目标应用中。 -
确保模型的输出符合应用需求。
-
部署应用到生产环境。 -
监控应用性能,确保稳定运行。
-
根据用户反馈和应用数据持续优化模型。 -
定期更新模型以适应新的数据和需求。
社区资源和支持
-
加入Meta Llama 3的官方社区,参与讨论和交流。 -
访问在线论坛和文档,获取技术支持和最佳实践。 -
参加相关的线上或线下活动,与其他开发者建立联系。
负责任的AI使用指南
-
数据隐私:在处理用户数据时,遵守数据隐私和保护法规。 -
公平性:确保模型的输出不含有偏见,对所有用户公平。 -
透明度:向用户清晰说明模型的功能和限制。 -
安全性:保护模型不被恶意使用,确保应用的安全性。
