
之前阿里开源了多模态模型,在审计作业过程中针对大量的合同、单据检查,利用多模态大模型的能力,可以对不同形态、不同语言的各种非标合同完成关键信息抽取,并将结果结构化到底稿中。
其实雏形早就弄好了,田川老师也用了一段时间,不过是Python版的(Python代码在最后),搬到小帮手要考虑交互和易用等问题,每天写一点硬是写了一个月…忙到崩溃
小帮手本次更新做了3件事
1、接入阿里的qwen-vl-max
2、实现在Excel中自定义字段的信息抽取(提示词会动态根据表头生成)
3、侧边框直接预览合同方便复核
效果预览:


图文教程:
1. 获取API KEY,参考手册中阿里APIkey申请教程,合同助理使用的是阿里的多模态大模型,只能使用阿里的Key
2. 将Key填写至配置框体中
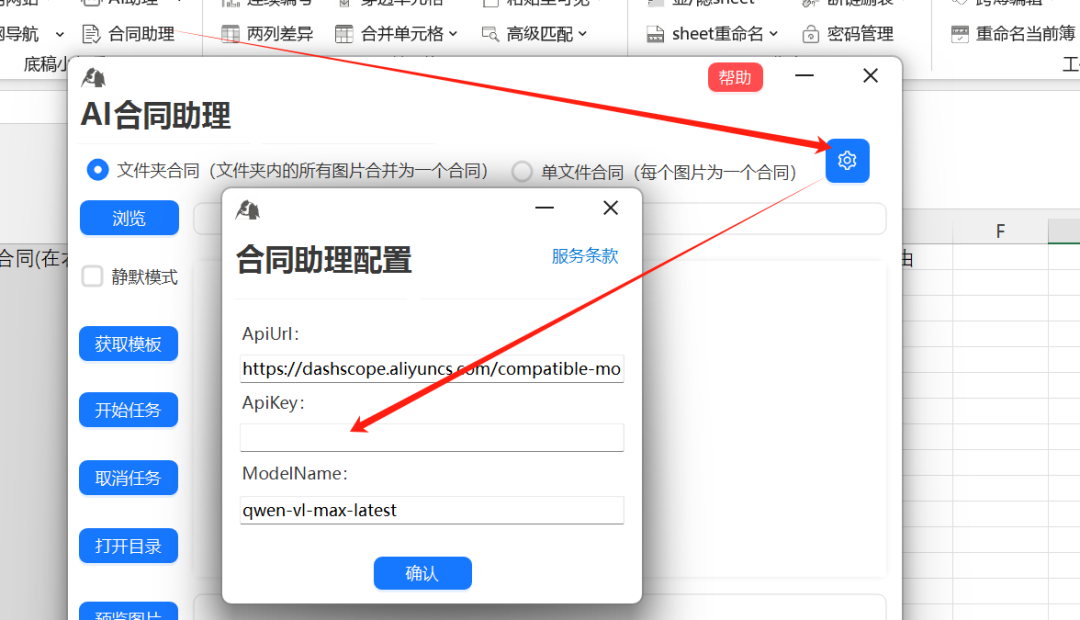
3. 点击获取模板,自定义需要提取的字段

4. 选择文件形式
文件夹合同:当一个合同有多个图片,将读取某文件夹下的所有图片,整合至一起发送给AI进行识别
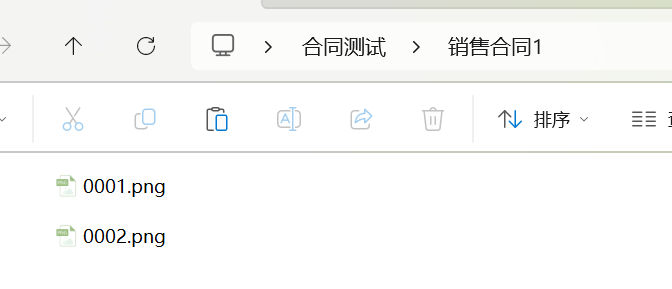
此时,直接选择该文件夹即可
单文件合同:当一个合同只有一张图片时,将读取该图片文件直接发送AI进行识别
此时直接选择该文件即可

注意:当前只支持图片识别,不支持PDF直接识别(模型要求),可以使用工具PDFPatcher批量提取+分类汇总PDF中的图片
PDFPatcher下载地址:
https://wwnw.lanzouo.com/b00uz2ehpa
密码:9xkb
5. 点击开始任务,等待数据写入
6. 预览图片
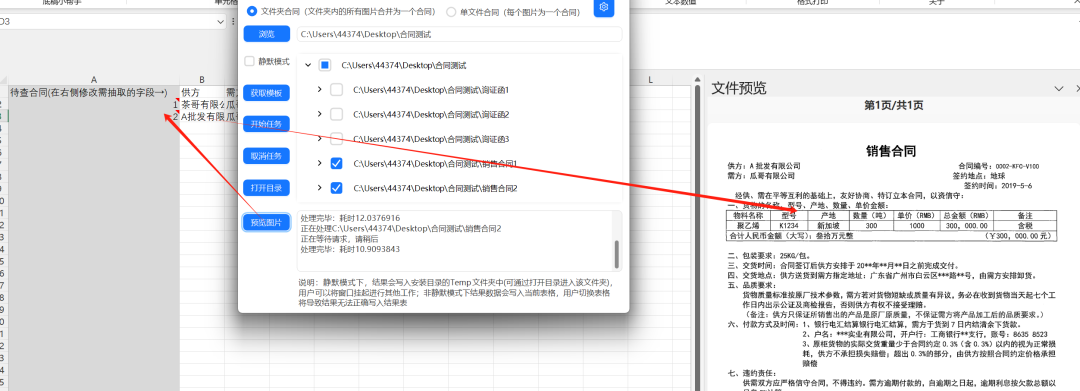
在A列会自动标记文件类型和对应路径,在选中该行时点击预览图片,即可在Excel右侧窗体中直接查看该文件,方便用户复核识别结果
7. 静默模式
在默认非静默模式下,数据会写入当前的表格,用户需要等待数据写入,时间可能较长,在此期间内不要切换Sheet,因此可能耽误其他工作
勾选静默模式后,程序将在后台将数据写入默认文件夹的Csv文件中,用户可以在跑数据期间自由操作Excel
注意:使用静默模式时,无法在A列单元格打路径锚点,因此无法使用预览图片的功能
CPAHelper For Excel(底稿小帮手)下载地址:
www.cgzcpa.com

Python版本:
# %%import osfrom openai import OpenAIimport base64import pandas as pdimport json# %%client = OpenAI( # 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx", api_key="", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)# Base64 编码格式def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode("utf-8")# %%def extract_info(img_path): base64_image = encode_image(img_path) completion = client.chat.completions.create( model="qwen-omni-turbo-latest", # model="qwen-vl-max-latest", messages=[ { "role": "system", "content": """你需要提取出买方、卖方、合同号、签订日期、产品、规格型号、数量、含税单价、不含税总额、交货时间、交货方式、交货地点,请输出JSON 字符串,不要输出其它无关内容。 示例: ```json { "买方": "???", "卖方": "???", "合同号": "???", "签订日期": "???", "产品": "???", "规格型号": "???", "数量": "???", "含税单价": "???", "不含税总额": "???", "交货时间": "???", "交货方式": "???", "交货地点": "???" } ``` """, }, { "role": "user", "content": [ { "type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}, } ], }, ], # 设置输出数据的模态,当前支持两种:["text","audio"]、["text"] modalities=["text"], response_format={"type": "json_object"}, # stream 必须设置为 True,否则会报错 stream=True, ) content = "" for chunk in completion: # print(chunk.choices[0].delta) if chunk.choices[0].delta.content: content += chunk.choices[0].delta.content # print(content) return json.loads(content)# %%record_list = []for root, dirs, files in os.walk("./imgs"): for file in files: print(os.path.join(root, file)) res = extract_info(os.path.join(root, file)) res["文件名"] = file record_list.append(res)# %%df = pd.DataFrame(record_list)df.to_csv("data.csv", index=False)
end
最后还是提醒一下,这个模型是阿里的模型,如果数据非常敏感,最好经充分评估以后再使用该工具,否则最好的方案应该是所里私有化部署以后再使用。
