

在快速发展的人工智能领域,将视觉功能集成到大型语言模型中,可以用于解读图片语义, 从图片中提取出结构化数据。

一、环境配置
在Python中调用大模型, 先要配置好相应的环境。
1.1 安装python包
pip3 install ollama
pip3 install pydantic
pip3 install instructor
1.2 安装Ollama
Ollama是一款开源应用程序,可让您使用 MacOS、Linux 和 Windows 上的命令行界面在本地运行、创建和共享大型语言模型。
Ollama 可以直接从其库中访问各种 LLM,只需一个命令即可下载。下载后,只需执行一个命令即可开始使用。这对于工作量围绕终端窗口的用户非常有帮助。Ollama的安装、配置、使用的详细教程可阅读 教程 | 如何使用 Ollama 下载 & 使用本地大语言模型
1.3 安装大模型
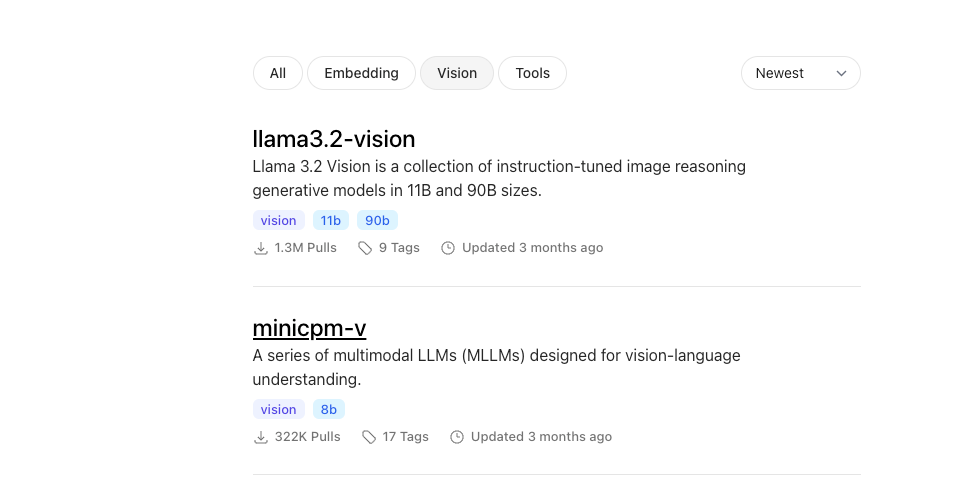
截止2025.2.22, 在 Ollama 网站中公开的 视觉类大模型 有7个, 这里简单介绍其中的两个
-
llama3.2-vision 更擅长识别图片中的英文信息 -
minicpm-v 模型基于qwen, 更擅长识别图片中的中文信息
打开命令行 cmd (在mac中对应terminal) , 执行安装命令
ollama pull llama3.2-vision:11b
ollama pull minicpm-v:8b
1.4 启动Ollama服务
打开命令行 cmd (在mac中对应terminal) , 执行启动服务命令
ollama serve
二、实验代码
2.1 非结构化输出
截图的文件名 test_screen.png

import ollama
#论文的截图文件 test_screen.png
#注意,代码文件与截图文件同处于一个文件夹内
response = ollama.chat(
model='minicpm-v',
messages=[{
'role': 'user',
'content': '这是一篇什么领域的论文?',
'images': ['test_screen.png']
}]
)
print(response)
Run
ChatResponse(model='minicpm-v', created_at='2025-02-22T13:11:25.766017Z', done=True, done_reason='stop', total_duration=12956488125, load_duration=819433041, prompt_eval_count=461, prompt_eval_duration=9630000000, eval_count=147, eval_duration=2499000000, message=Message(role='assistant', content='这张图片是关于一篇题为“开或关在轨:如何(破碎)的线索影响消费者决策”的文章标题页。该文章由杰基·西尔弗曼和亚历山德拉·巴拉斯奇撰写,探讨了消费者行为的新技术追踪的后果。研究发现,在七项研究中,持续的行为轨迹会引发高消费后的强化,并且如果打破了这些轨迹,则会产生相反的效果,从而影响消费者的决策。所用的研究方法包括跟踪、行为分析以及追踪和监测等工具和技术,以了解线索对不同领域(如体育、学习)的影响。关键词列出了文章的焦点领域:断路器、行为追踪和记录、消费者动机、参与度。', images=None, tool_calls=None))
2.2 结构化输出
设计更详细的提示prompt, 通过使用typing 和pydantic 设计数据结构,输出为字典类数据。
import instructor
import os
from typing import List
from pydantic import BaseModel
PROMPT = """请分析提供的图片,并从中提取以下信息:
- 标题(title)
- 学科(subject)
- 领域(field)
请以如下格式返回结果:
{
"title": "论文的标题",
"subject": "论文所属学科",
"field": "论文的研究领域",
}"""
#本地已安装大模型minicpm-v
model_name = 'minicpm-v'
base_url = 'http://127.0.0.1:11434/v1'
api_key = 'NA'
#论文的截图文件test_screen.png
#注意,代码文件与截图文件同处于一个文件夹内
image = instructor.Image.from_path("test_screen.png")
client = instructor.from_openai(
OpenAI(
base_url=base_url,
api_key=api_key, # required, but unused
),
mode=instructor.Mode.JSON,
)
classPaper(BaseModel):
title: str
subject: List[str]
field: List[str]
# Create structured output
result = client.chat.completions.create(
model=model_name,
messages=[
{"role": "asistant", "content": PROMPT},
{"role": "user", "content": image},
],
response_model = Paper,
temperature=0.0
)
result.model_dump()
Run
{'title': 'On or Off Track: How (Broken) Streaks Affect Consumer Decisions',
'subject': ['streaks, behavioral tracking and logging, technology, goals and motivation'],
'field': ['consumer behavior', 'marketing research', 'engagement strategies']}
三、讨论
大邓测试发现 结构化输出 很容易出错, 相比之下 非结构化输出 更稳定一些。
