

导读 随着大模型的发展和应用,文本的边界被拓宽,图像、视频、语音各种模态涌现,并给数据管理、检索、计算带来巨大挑战。火山引擎多模态数据湖解决方案则可实现海量结构化、半结构化及非结构化数据的统一精细化管理,全方位兼容各类数据格式,为 LLM 预训练、持续训练和微调全程各个环节提供更好的数据支持。
1. 数据湖在 AI 时代下的难点和挑战
2. 火山引擎多模态数据湖介绍
3. 未来演进和思
数据湖在 AI 时代下的难点和挑战
1. 计算资源从 CPU 扩展到 GPU
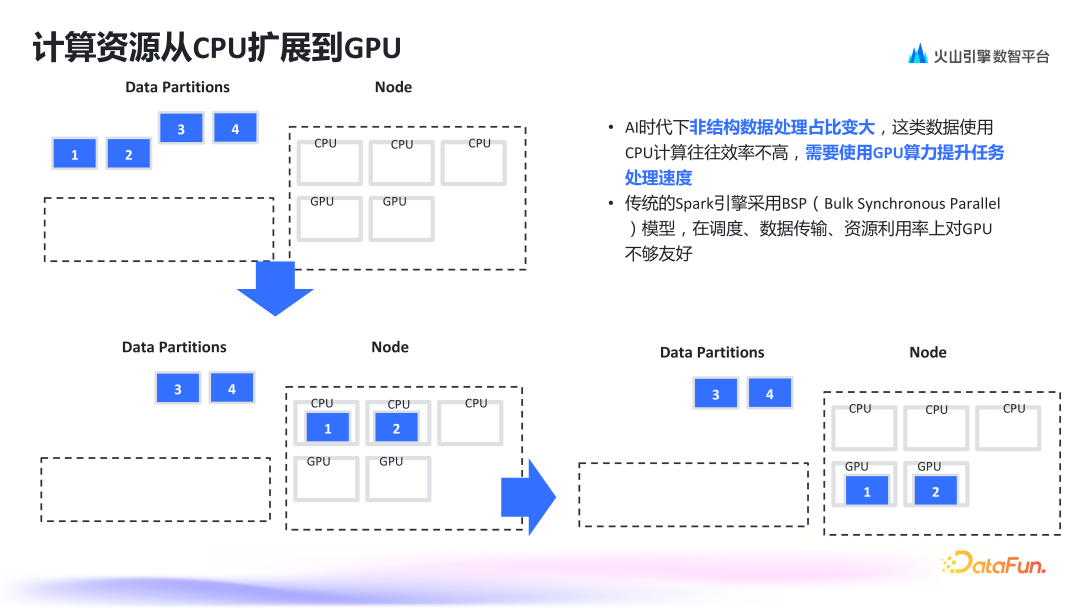
2. 数据处理任务对效率、稳定性和灵活性要求高

-
模型训练前的数据准备阶段,单次任务处理数据多,耗时长。一份数据在任务中会被多次读取加工。
-
任务直接读写对象存储 Bucket 数据,会产生很大的带宽和 QPS 压力。
-
单次任务的耗时、多任务并发时整体任务的吞吐量都受限于带宽和 QPS,会成为数据准备任务的瓶颈。
-
相对传统数仓而言,高负载和小文件问题呈指数级放大,模型训练场景下会产生百万级的 Spark partition shuffle 压力,原生 Shuffle、开源集中式 Shuffle 如 celeborn,均无法稳定高效处理。
-
高负载和高并发下,原生的 Spark history server 容易出现崩溃或者页面无法打开等问题。
-
任务失败后的重试成本高。
-
数据准备阶段的不同任务,往往需要一些第三方的库包,比如算法函数、硬件加速相关包等,不同任务依赖的库包甚至会是互相冲突。
-
传统大规模计算集群,在运行节点上预先安装好各种依赖包,提供环境级别的隔离,已无法满足需求,当下需要的是提供任务级别的自定义运行环境。
火山引擎多模态数据湖介绍
1. 火山引擎多模态数据湖架构

-
湖管理:
全域数据集成 DataSail:数据入湖。
AI 数据湖服务(Lake AI Service,LAS):提供了统一元数据及权限管理的能力。这一层之下需要接入不同的数据源,之上需要对接不同的计算引擎,要使一份数据可以被多个引擎处理,则需统一元数据管理,LAS 即为这样的平台。
大数据研发治理套件 DataLeap:提供了 Data+AI 的统一数据开发平台,具有找数助手、开发助手、运维助手等功能,例如可以通过自然语言生成 SQL 并检索展示数据。
-
湖存储:存储结构化和非结构化数据,支持开发的湖格式(Iceberg、Hudi、Paimon),以及湖存储加速引擎 Proton。
-
湖计算:支持火山引擎多款数据产品,包括大数据平台 E-MapReduce、流计算 Flink、自研支持向量化读写的 OLAP 引擎 ByteHouse。
2. 火山引擎多模态数据湖设计理念
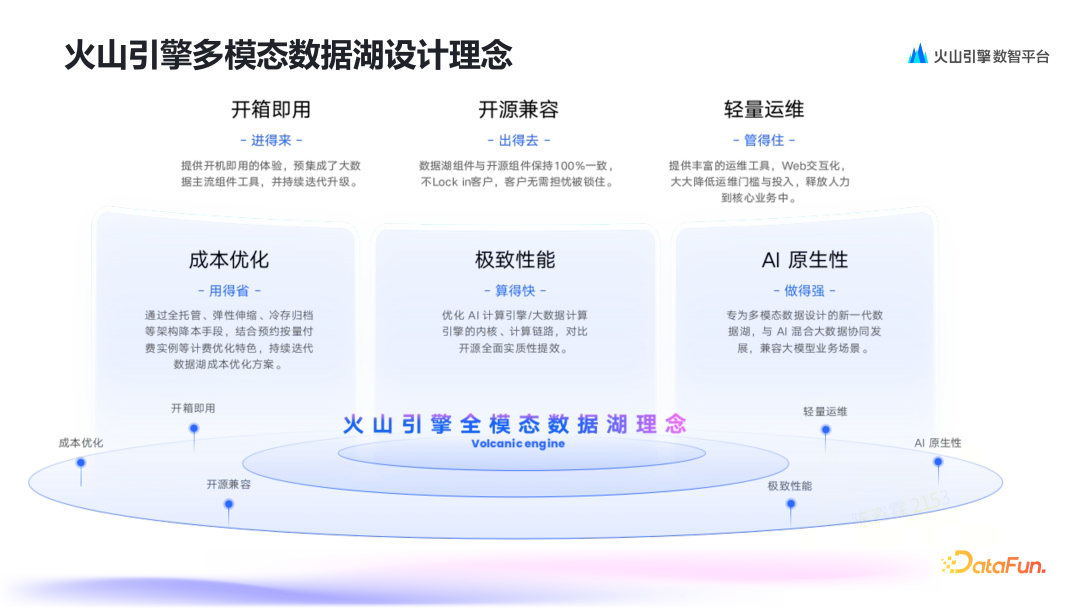
-
开箱即用(进得来):在传统企业上云场景下,已经有多云部署的趋势,在AI时代下,特别是模型算法公司,需要数据湖是透明、数据 Open。
-
开源兼容(出得去):与开源技术栈完全兼容,可无缝多环境迁移部署,不 Lock In 用户。
-
轻量运维(管得住):垂直类模型公司的工程师以算法为主,不擅长底层设施的维护,需要尽可能降低运维的门槛。
-
成本优化(用得省):通过全托管、弹性伸缩、冷存归档等手段,结合预约按量付费实例等计费方式,降低用户的使用成本。
-
极致性能(算得快):通过优化计算引擎内核、计算链路,实现实质性提效。
-
AI云原生(做得强):专为多模态数据设计,与AI混合大数据协同发展,以适应各种场景需求。
3. 火山引擎多模态数据湖方案产品

4. EMR 多产品形态提供 Data 和 AI 计算引擎
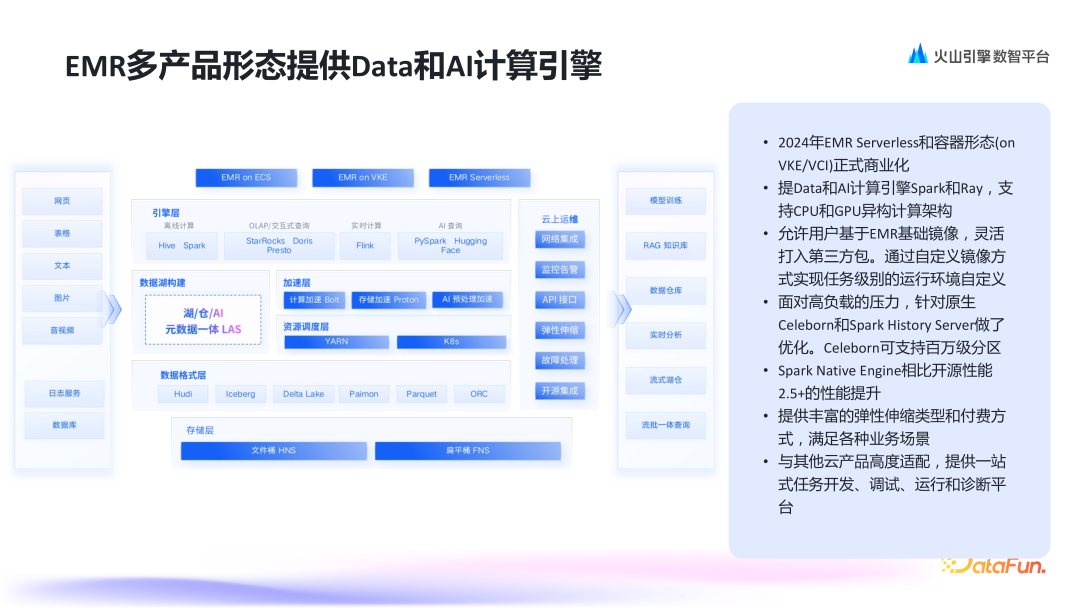
-
允许用户基于 EMR 基础镜像,灵活打入第三方包。通过自定义镜像方式实现任务级别的运行环境自定义。 -
针对高负载和小文件等问题,进行了性能优化。基于原生 Celeborn 实现优化,支持 500 万级别的 Partition Shuffle,远超传统数仓容量规模,并提高了 Spark History Server 的稳定性。 -
抖音集团内部孵化 Spark Native Engine,相比 Spark 开源版本,性能提升达到了 2.5 倍以上。 -
此外,针对用户体验进行了优化,提供了丰富的弹性伸缩类型和付费方式,满足各种场景需求。 -
EMR 产品可以与其它云产品,如数据集成 DataSail、大数据研发治理套件 DataLeap 等高度适配,提供一站式 Data+AI 开发、调试、运行和诊断平台。
5. 使用 Ray 对多模态数据做高效处理
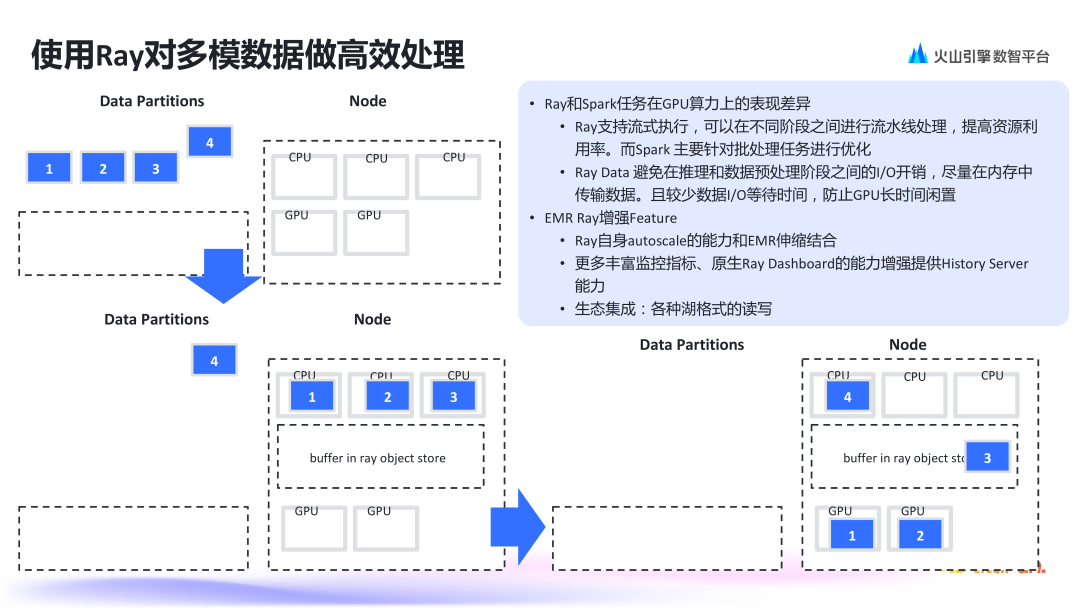
6. 使用 Proton 实现数据湖加速

未来展望与思考

