

-
从现有候选文档集推断出模式。您可以选择稍后编辑此模式。
-
根据指定的模式(无论是从上一步推断出来的、由人类指定的,或两者兼有)从一组文档中提取值。
LlamaExtract 目前处于 beta 阶段,这意味着它是一个我们正在努力改进的实验性功能,使其更普遍可扩展和可用。请将任何问题报告到我们的 Github!
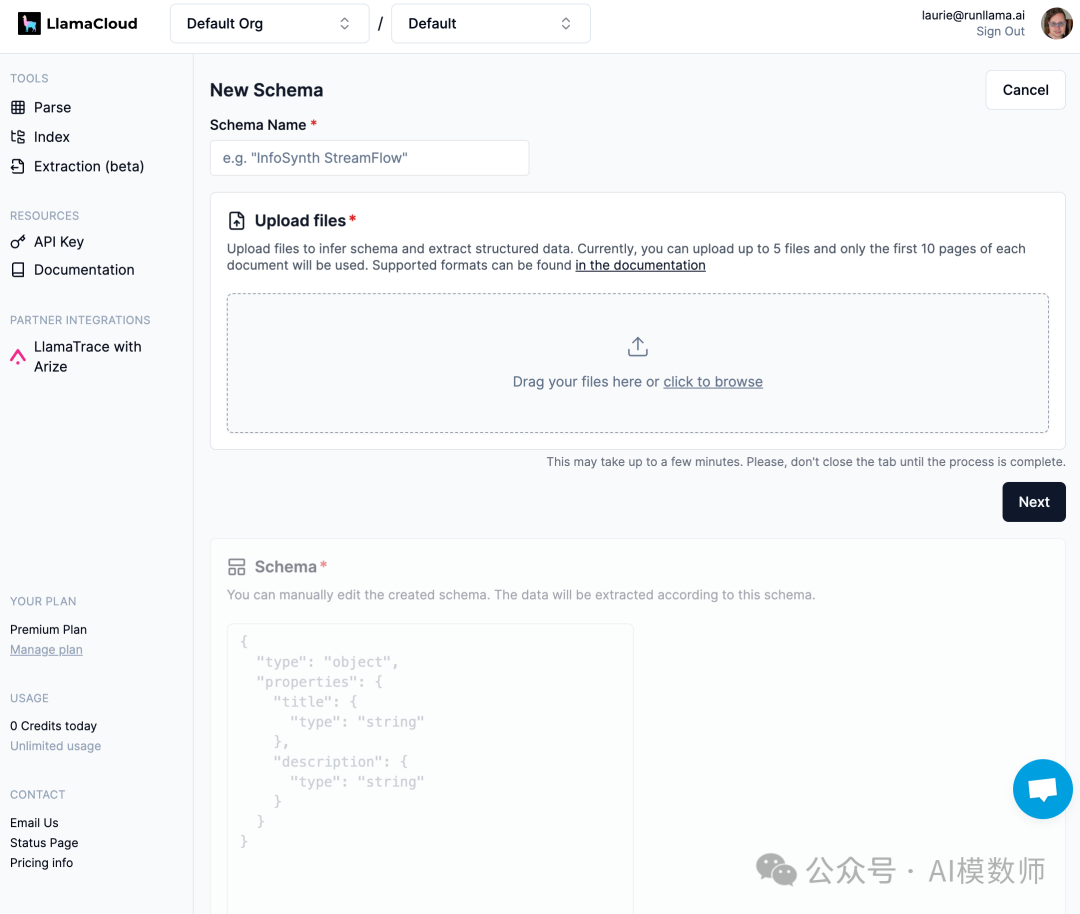
元数据提取是 LLM ETL 栈的关键部分

-
我们正在对 UI 进行一些核心改进,例如将模式推断和提取解耦,允许用户预定义模式等。有关更多灵活性,请查看下面的 API。
pythonfrom llama_extract import LlamaExtractextractor = LlamaExtract()extraction_schema = extractor.infer_schema("Test Schema", ["./file1.pdf","./file2.pdf"])from pydantic import BaseModel, FieldclassResumeMetadata(BaseModel):"""Resume metadata."""years_of_experience: int= Field(..., description="Number of years of work experience.")highest_degree: str= Field(..., description="Highest degree earned (options: High School, Bachelor's, Master's, Doctoral, Professional)")professional_summary: str= Field(..., description="A general summary of the candidate's experience")extraction_schema = extractor.create_schema("Test Schema", ResumeMetadata)
无论您如何获得模式,现在都可以执行提取:
-
简历:从候选人的个人资料中提取结构化注释,如学校、工作经历、工作经验年限。
-
收据和发票:提取行项目、总价和其他数字。
-
产品页面:根据用户定义的模式结构化和分类您的产品。
