文档RAG的未来是多模态的
LlamaCloud多模态特性概述
-
减少价值实现时间:激活多模态索引就像在创建RAG索引时点击一个开关一样简单。
-
在非结构化数据上高性能:在复杂的文档如PDF和PowerPoint中实现卓越的检索质量,无论是文本还是图像。
-
全面理解:利用文本和视觉信息,获得更准确、更有上下文意识的AI响应。
-
简化数据集成:轻松将不同类型的数据集成到你的RAG管道中,无需广泛的预处理。
真实世界示例:分析公司演示文稿
1. 创建多模态索引
2. 将索引集成到你的代码中
from llama_index.indices.managed.llama_cloud import LlamaCloudIndex
index = LlamaCloudIndex(
name="<index_name>",
project_name="<project_name>",
organization_id="...",
api_key="llx-..."
)3. 设置多模态检索
retriever = index.as_retriever(retrieve_image_nodes=True)4. 构建自定义多模态查询引擎
from llama_index.core.query_engine import CustomQueryEngine
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
class MultimodalQueryEngine(CustomQueryEngine):
"""自定义多模态查询引擎。
接受一个检索器来检索一组文档节点。
还接受一个提示模板和多模态模型。
"""
qa_prompt: PromptTemplate
retriever: BaseRetriever
multi_modal_llm: OpenAIMultiModal
def__init__(self, qa_prompt: Optional[PromptTemplate] =None, **kwargs) ->None:
"""初始化。"""
super().__init__(qa_prompt=qa_prompt or QA_PROMPT, **kwargs)
defcustom_query(self, query_str: str):
# 检索文本节点
nodes = self.retriever.retrieve(query_str)
img_nodes =[n for n in nodes ifisinstance(n.node, ImageNode)]
text_nodes =[n for n in nodes ifisinstance(n.node, TextNode)]
# 从文本节点创建上下文字符串,将其转储到提示中
context_str ="\n\n".join(
[r.get_content(metadata_mode=MetadataMode.LLM) for r in nodes]
)
fmt_prompt = self.qa_prompt.format(context_str=context_str, query_str=query_str)
# 从格式化的文本和图像中合成答案
llm_response = self.multi_modal_llm.complete(
prompt=fmt_prompt,
image_documents=[n.node for n in img_nodes],
)
return Response(
response=str(llm_response),
source_nodes=nodes,
metadata={"text_nodes": text_nodes, "image_nodes": img_nodes},
)
return response
query_engine = MultimodalQueryEngine(
retriever=retriever, multi_modal_llm=gpt_4o
)5. 查询你的多模态索引
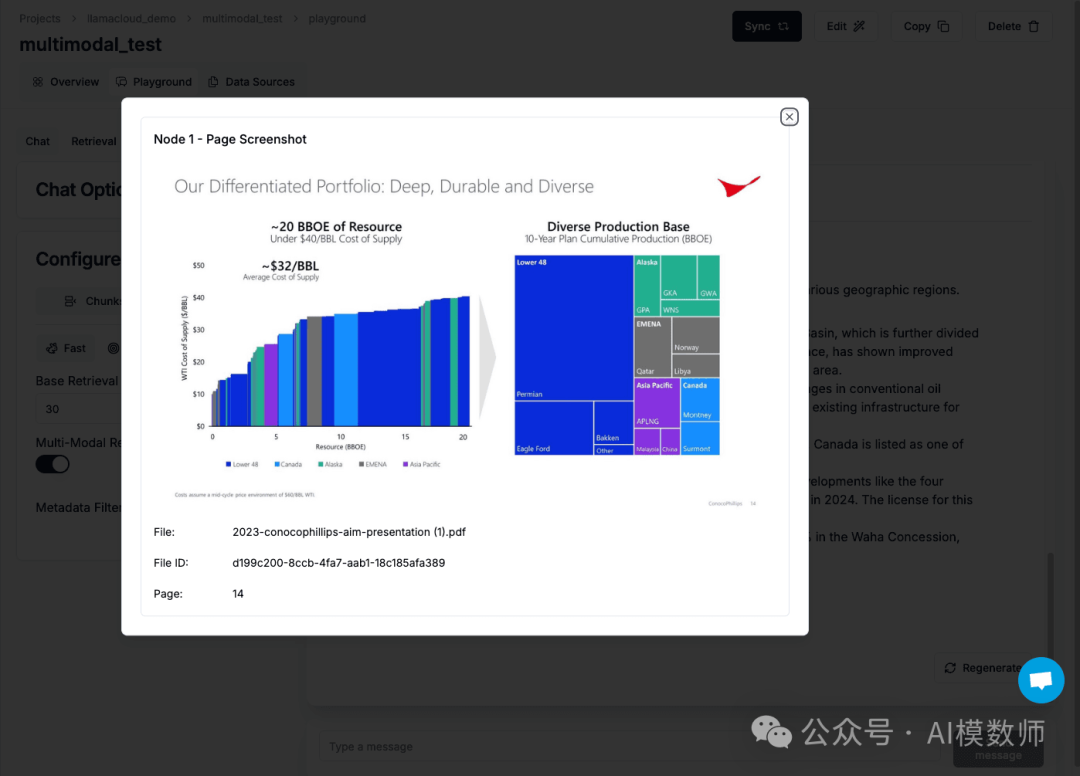
response = query_engine.query("Tell me about the diverse geographies which represent the production bases")
下48州(美国)
加拿大
阿拉斯加
EMENA(欧洲、中东和北非)
亚太地区