


近日,由香港科技大学、腾讯混元已经清华大学联合推出了Follow-Your-Emoji,一种基于扩散的肖像动画框架,它使用目标地标序列为参考肖像制作动画。
肖像动画的主要挑战是保留参考肖像的身份并将目标表情转移到此肖像上,同时保持时间一致性和保真度。
为了克服这些挑战,Follow-Your-Emoji采用了两项精心设计的先进技术,以增强其稳定扩散模型的性能。
该团队引入了一种新颖的表情感知地标,这是一种显式的运动信号,用于指导动画过程。
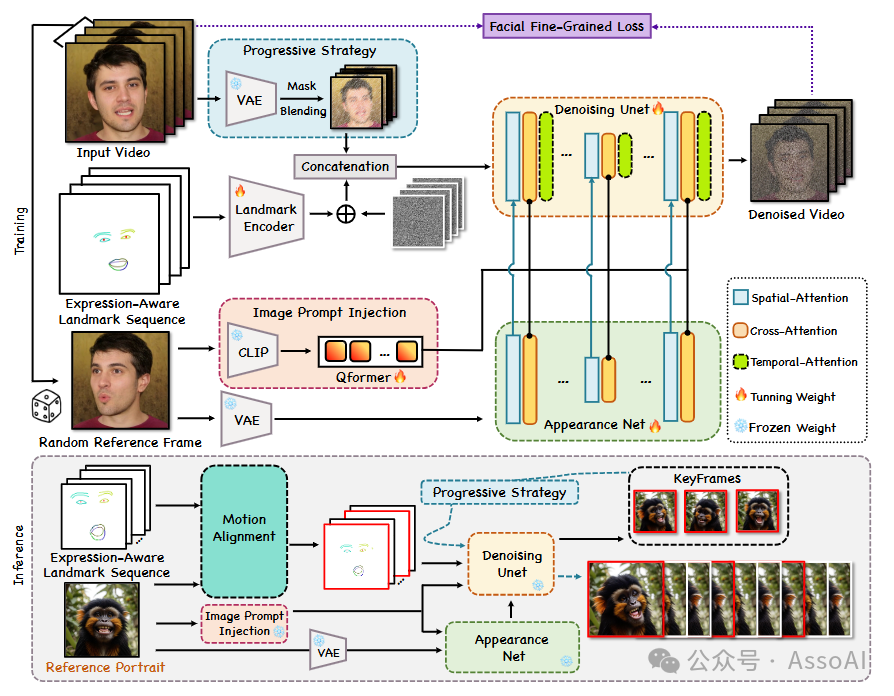
通过使用地标编码器提取表达感知地标序列的特征,并首先将这些特征与多帧噪声融合,然后利用渐进策略随机屏蔽输入潜在序列的帧。
最后,我们将此潜在序列与融合的多帧噪声连接起来,并将其馈送到 Denoising UNet 以进行视频生成的去噪过程。
外观网络和图像提示注入模块帮助我们的模型保留参考肖像的身份,并且时间注意力保持时间一致性。
这种地标不仅确保了推理过程中肖像与目标运动之间的精确对齐,还有助于提高模型在描绘夸张表情(例如大瞳孔运动)方面的能力,同时避免了身份泄露的风险。
其次,该团队还提出了一种面部细粒度损失函数,它利用表情和面部掩码来提高模型对微妙表情变化的感知能力,并改善对参考肖像外观的重建效果。
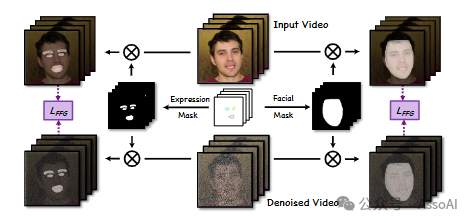
这使得该方法在控制各种风格肖像的表情方面展现出卓越的性能,包括真实人物、卡通角色、雕塑作品,甚至是动物形象。

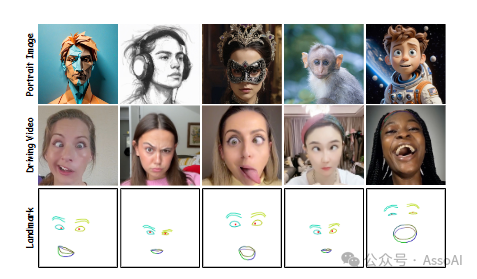
EmojiBench 的示例,在肖像图像中具有高表情多样性、夸张性和多种视觉风格


