


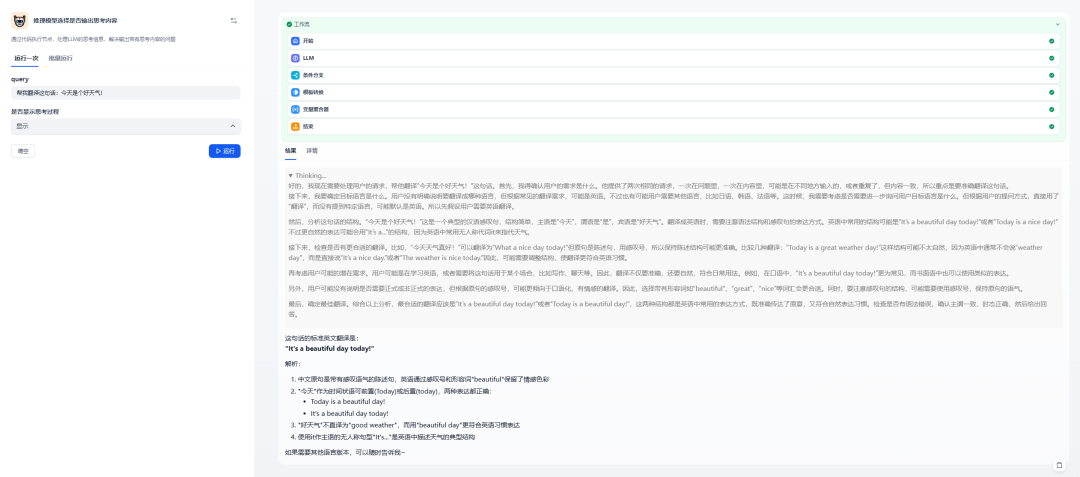
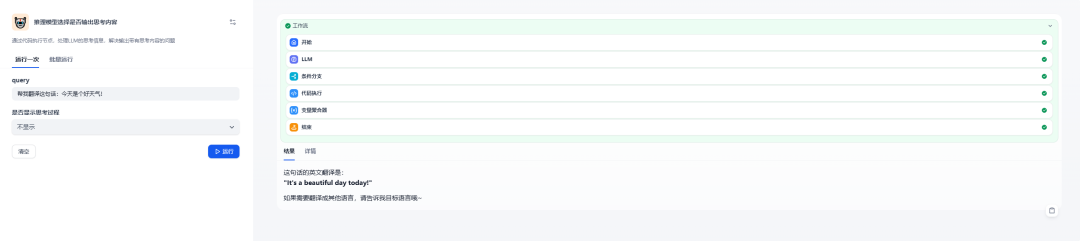
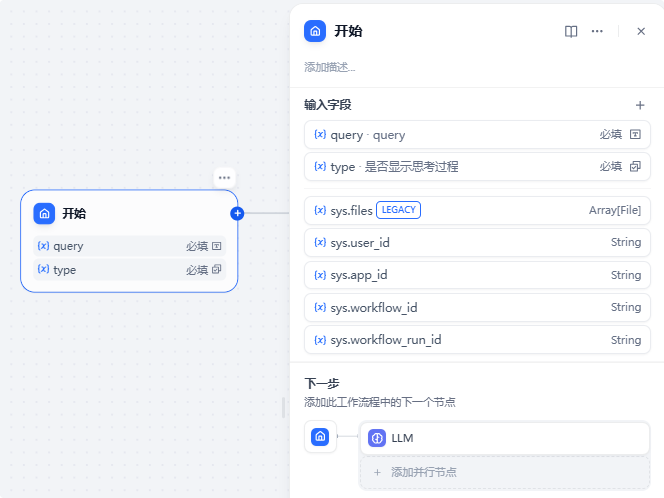
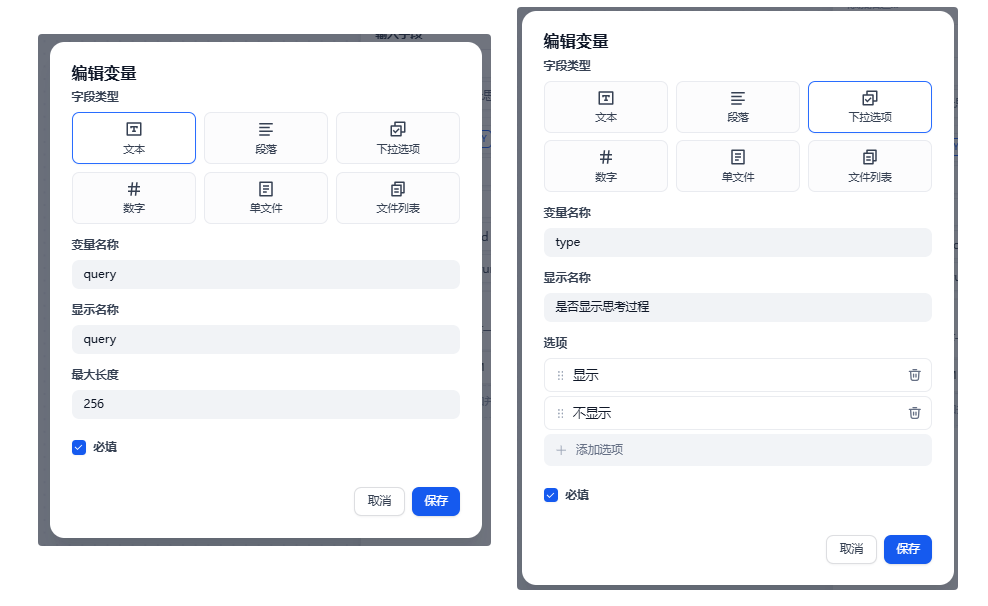
我们创建两个必填的变量:query和type,其中query是文本类型的,是用户输入的信息,这里如果需要大段的文字,可以考虑使用段落类型,这样字符会可以设置更大;type是下拉选择类型的,是选择是否显示思考过程的一个选项,包含“显示”和“不显示”:
在LLM节点中,我们选择的模型是deepseek-reasoner,这个就是DeepSeek官网的API对应的思考模型即满血版DeepSeek-R1。
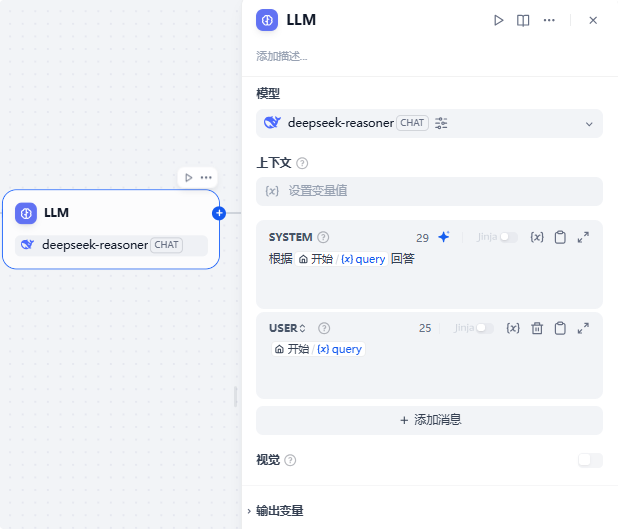
这个节点的system prompt和user prompt的内容我就写的很随意,主要是让根据query变量来回答问题即可,为的是让输出有数据。LLM模型也不需要做任何设置,就默认就行,主要是为了处理思考模型,这些设置不影响。
条件分支作用就是基于开始节点用户选择的type变量的内容,来做条件判断,选择“显示”则直接走到模板转换节点,选择“不显示”则后续节点连接代码执行节点:
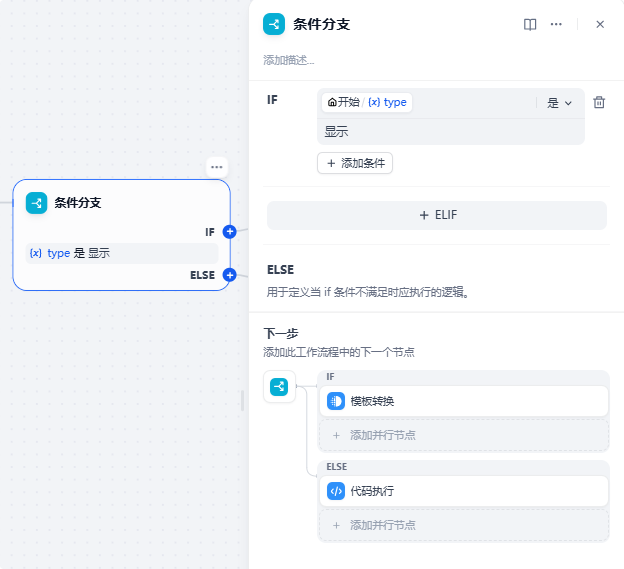
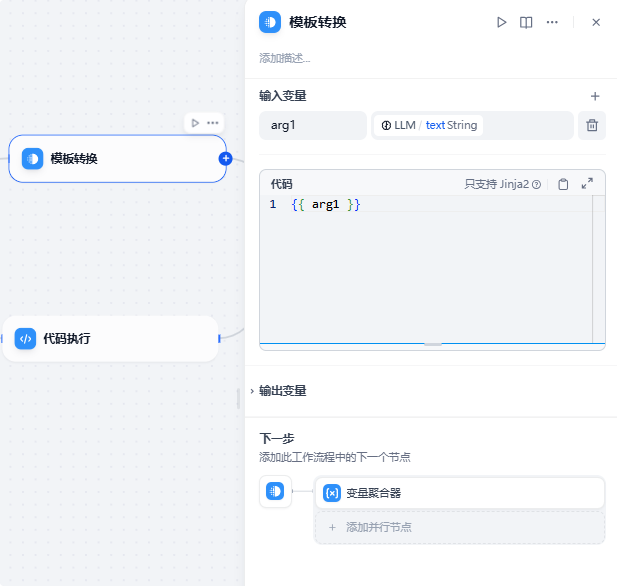
模板转换节点是为了让分支节点的两条分支不同时进入,所以这边只是做了一个转换,不然直接接入结束节点则会导致两个节点同时输出给后续节点。
代码执行节点是本次案例分享的关键节点,这里只有一个输入变量,就是LLM节点的输出变量,用于节点代码编辑部分的参数,通过简单的python对思考过程的数据进行过滤:
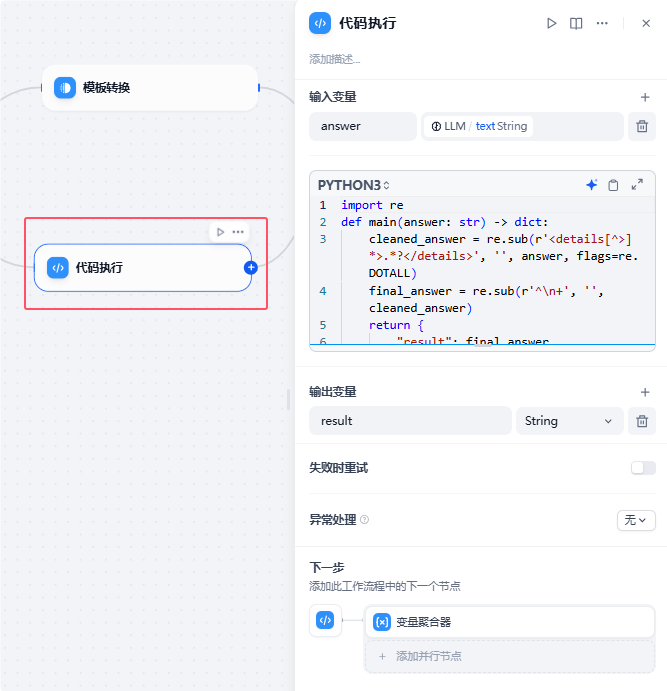
import redef main(answer: str) -> dict: cleaned_answer = re.sub(r'<details[^>]*>.*?</details>', '', answer, flags=re.DOTALL) final_answer = re.sub(r'^n+', '', cleaned_answer) return { "result": final_answer, }
details
think
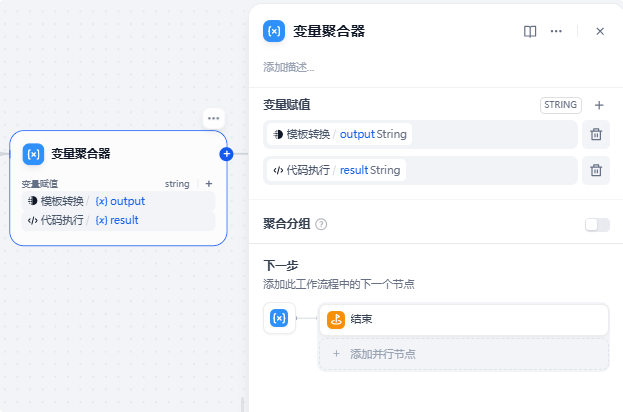
变量聚合器节点在之前的篇章也介绍过,今天就不着重讲解了,主要就是为了两个分支的输出结果进行统一的一个接收并输出给结束节点。
接收的变量为模板转换节点的输出和代码执行节点的输出:
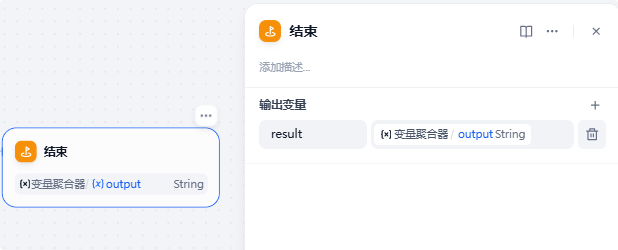
最后的结束节点就是把变量聚合节点的输出内容给用户展示:
好了,今天的案例分享就到这儿,希望这个小案例对你们有帮助,可以帮助本地化部署的推理大模型进行思考部分的屏蔽输出,有问题可以评论区留言或者进群一起讨论。
