
1. 背景介绍
2. 产品架构介绍
3. 落地实践
4. 未来展望
分享嘉宾|陈叶超 喜马拉雅 数据平台负责人
编辑整理|薛明慧
内容校对|李瑶
出品社区|DataFun
背景介绍
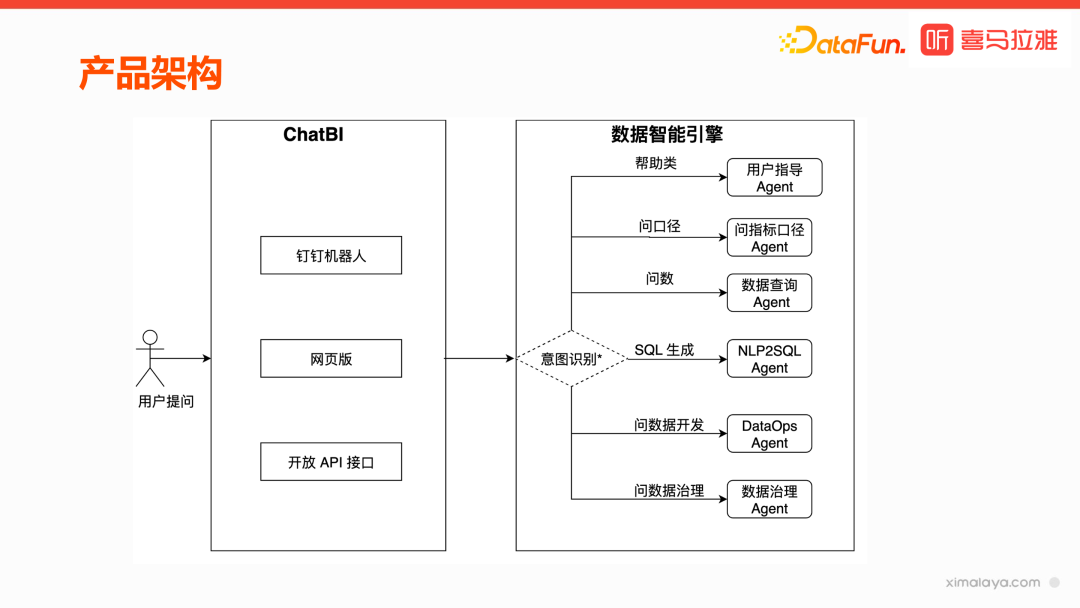
产品架构
2. 产品结构
-
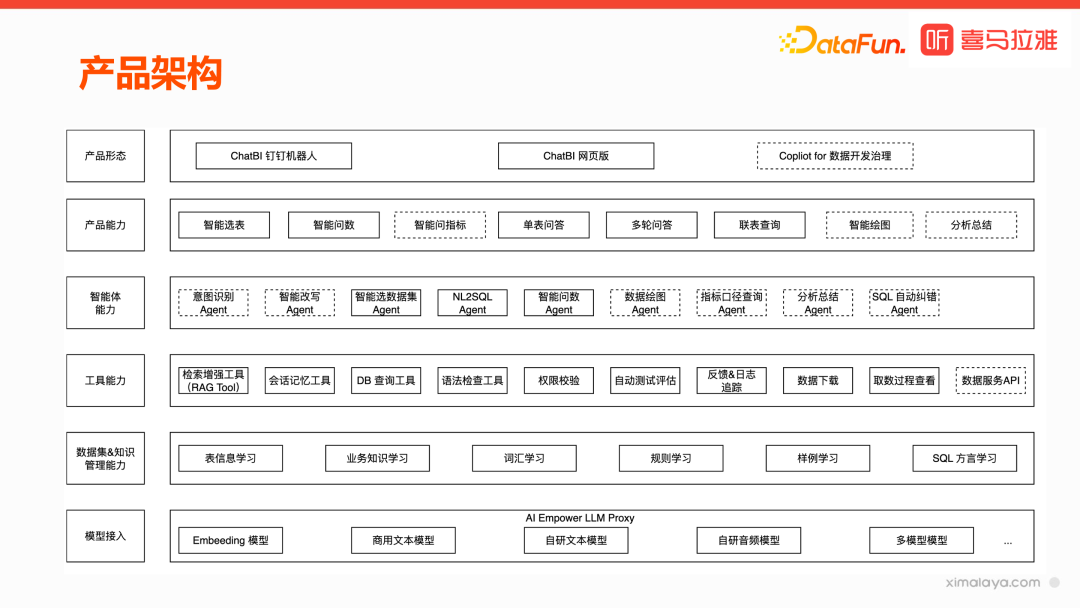
模型接入层:借助公司的大模型平台,接入了 embedding 模型、商用文本模型、自研文本模型和自研音频模型等。
-
数据集和知识管理能力层:大模型生成 SQL 的准确性至关重要,而准确性非常依赖于 prompt 上下文,知识处理就是为了更好地表达上下文。在这一层,使大模型学习数据库中的表信息、业务知识、专业词汇、规则和一些 SQL 方言,可以更好理解 prompt,从而做出更为准确的回答。
-
工具能力层:提供了解决用户问题要使用的工具,包括检索增强、会话记忆、DB 查询、语法检查、权限校验等工具。同时为了保证质量,我们还构建了一套自动测试评估体系,以及反馈和日志追踪体系。
-
智能体能力层:包括意图识别、智能改写、智能选择数据集、NL2SQL、智能问数、数据绘图、指标口径查询、分析总结和 SQL 自动纠错等智能体。
-
产品能力:基于上述大模型、Agent 和工具的能力,产品提供了智能选表、智能问数、智能问指标、单表问答、多轮问答、联表查询、智能绘图、分析总结等功能。
-
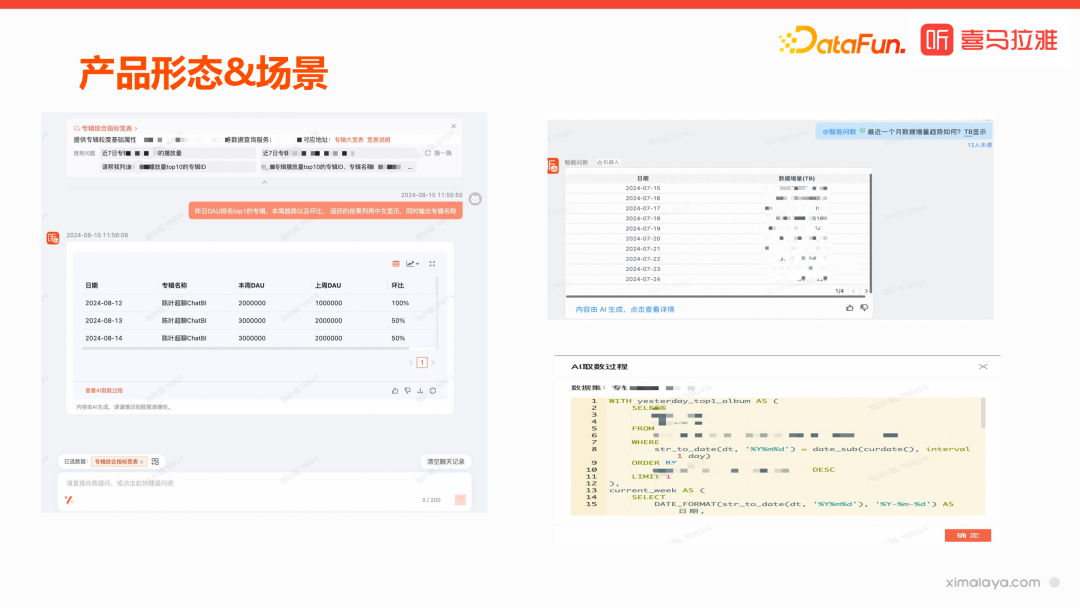
产品形态:通过钉钉机器人、网页版和开放 API 接口提供给用户使用。
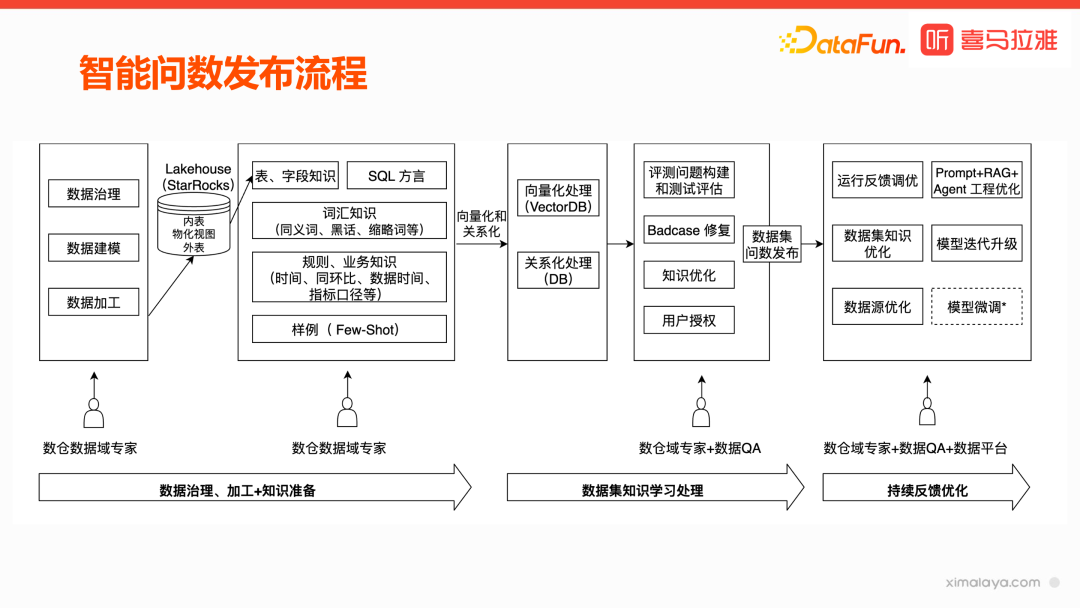
3. 智能问数发布流程
落地实践
1. 人是怎么写 SQL 的?

2. 大模型推理优化
-
Prompt Engineering:为大模型提供好的角色、指令和上下文; -
RAG:为大模型提供更加精准的知识,限定上下文输入,解决模型幻觉等问题; -
Fine-Tuning:指令遵循等; -
RAG+Fine-Tuning; -
智能体 Agent:将复杂的工作规划为多智能体的结构,对各部分分别进行优化,从而提升整体效率; -
大模型迭代升级。
3. 上线效果
未来展望
