
导读 本文将分享平安人寿自研的大模型智能化报表——ChatBI 产品的实践与思考。
1. 项目背景和目标
2. 解决方案
3. 产品效果
4. 落地挑战
5. 总结和展望
6. 问答环节
分享嘉宾|刘行行 中国平安人寿保险股份有限公司 财企及产品数据服务组分组经理
编辑整理|杨生
内容校对|李瑶
出品社区|DataFun
01
项目背景和目标
1. 项目背景:大模型赋能智能 BI
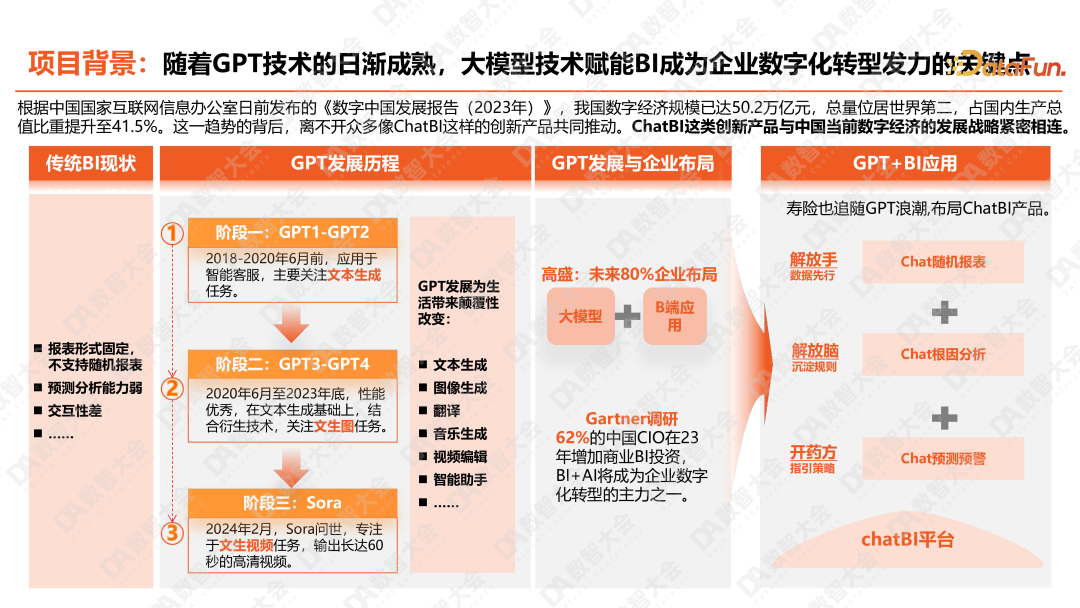
-
第一,传统的 BI 产品在数据指标、预测能力方面遇到了技术瓶颈,用户体验也不够友好; -
第二,随着 GPT 的发展,GPT 技术在文本和图像生成上取得了突破性进展,为 ChatBI 在企业中的落地提供了坚实的基础; -
第三,许多企业对数字化和 BI 的发展也越来越重视。

-
一是语言能力,大模型已经能够理解自然语言的语法结构和词的含义; -
二是学习能力,我们可以通过 RAG 技术让大模型快速学习特定领域的知识; -
三是工具调用,我们可以通过 Agent 编排,可以快速调用现有工具,并生成代码; -
四是逻辑推理,我们可以通过大模型结合人工对数据进行洞察分析,检查出异常点和问题。
2. 项目目标:智能 BI 3.0

-
智能化意味着需要大模型为用户提供智能的分析建议; -
自动化则是自动生成可视化报表; -
实时化要求秒级返回底层数据库的所有数据。

-
第一,我们拥有完善的数据中台,包含丰富的数据域; -
第二,我们进行了长期的数据治理,拥有上万个规范的数据指标供用户使用; -
第三,我们拥有丰富的可视化组件可以复用; -
第四,我们的服务平台也已经实现了数据服务的 API 化; -
最后,我们内部已经具备私有部署大模型和模型调优的能力。
3. 项目愿景:人人都是数据分析师

-
第一,通过零学习成本,降低报表的使用门槛,让数据的使用变得极其简单; -
第二,提供智能的分析建议,使数据分析变得智慧化; -
第三,通过嵌入方式将 ChatBI 产品整合到多个内部平台中,实现快速查询数据,提升用户体验,让每个人都能成为数据分析师。
解决方案
1. 总体架构方案

-
最底层是数据中台,包含各种数据域和指标。 -
往上一层是平台层,集成了 API 服务、知识管理、大模型以及 Cube 和 GS 平台,以及北斗可视化平台。这些平台主要覆盖从用户提问到代码生成,再到可视化等功能点。 -
在 Agent 这一层,我们分为四类:问数、分析、数据解读以及公共能力 Agent。 -
最后是应用层,我们实现了三个核心功能:What(解放手)、Why(解放脑)和How(开药方)。 What 指的是用户可以通过对话方式查询数据,实现零代码和实时数据获取,并通过图表进行可视化生成,数据获取速度从以前的天级提升到现在的秒级。
Why 主要指通过大模型实现根因分析、数据洞察、维度分析等,替代人工进行数据分析,将数据分析流程从原来的"提需求→分析需求→获取数据→进行数据分析→制作分析报告"变成现在的一步到位,通过自然语言提问即可直接生成分析报告。
How 则是开药方,通过大模型的洞察能力和分析能力,提供数据建议和措施,让洞察分析从依赖人工经验变成自动化智能生成。
2. 业务架构

-
在产品功能方面,业务用户不仅需要查询数据,还需要了解指标口径、元数据等信息,并希望有指标推荐、代码生成、可视化以及通过多轮对话提升体验等。 -
在问法方面,除了简单问题,还支持复杂问题的查询,如同比、环比、累计和排序等。 -
在指标方面,我们提供全域数据指标,并能支持日频、月频和年频指标的查询能力,最关键的是指标权限管理,确保每个用户根据账号确定其指标使用范围,保障数据安全。

3. 技术架构

-
第一是前端用户,我们可以通过插件的形式插入到不同的平台,支持用户访问、提问、鉴权和网关控制。
-
第二是多轮对话,多轮对话部分通过上下文理解能力捕获业务客户的意图,为下一步的任务编排做准备。
-
第三是 Agent 编排,其中任务执行是整个系统的大脑,通过任务编排调用不同的工具和知识库。
-
第四是 AI+BI 工具箱,这是我们开发过程中面临的最大挑战,需要针对不同场景开发不同的小模型,比如预测预警、时间序列预测和指标分析等,通过定制化的模型来适应不同的场景。
-
最后是可视化系统,我们通过可视化平台和一些可视化布局的插件快速生成可视化图表。

-
RAG 技术用于提高准确率,大模型在进行语义解析后会调用知识库进行检索,然后用这些知识进行文本和数据的语义分析和生成,从而大幅提高准确率。 -
知识库分为常见知识库和进阶知识库,常见知识库包含常见名词、知识和 SQL 语法等,而进阶知识库则是垂直领域内的知识,如 BI 知识库的同环比、累计等术语,保险知识库的各种保险行业名词,以及 SQL 知识库的 SQL 编写规范。
产品效果
落地挑战
-
第一是大模型的幻觉问题,即同一个问题可能会出现不同的回答,我们的解决方案是通过知识库和数据中台进行兜底策略。 -
第二是根因分析,这是我们认为最难的问题,当分析指标变动的深层原因时,需要在后台有大量的指标图谱和知识库支撑,需要花费大量的精力建设小模型,这也是我们未来重点的方向。 -
第三,用户权限管理也是一个重要但容易被忽略的点,我们需要长期的数据治理和盘点,以确保每个用户只能使用其授权的指标,避免出现数据安全问题。
总结与展望
-
首先,我们的产品不仅限于管理层使用,而是可以覆盖到所有员工和客户。 -
其次,我们可以实现 7×24 小时的在线应用。 -
第三,我们可以无缝衔接到不同的客户端。 -
第四,我们提供的是标准一致的全域数据。 -
第五,我们能提供智能化的分析,降低分析门槛。 -
最后,我们能提供数据洞察的结论或建议,使数据洞察成为一个完整的分析过程。
问答环节
Q2:关于数据权限的管理,您是如何控制行列权限的?
