

因项目需要,最近在学习阿里云新一代万卡集群网络架构HPN 7.0。
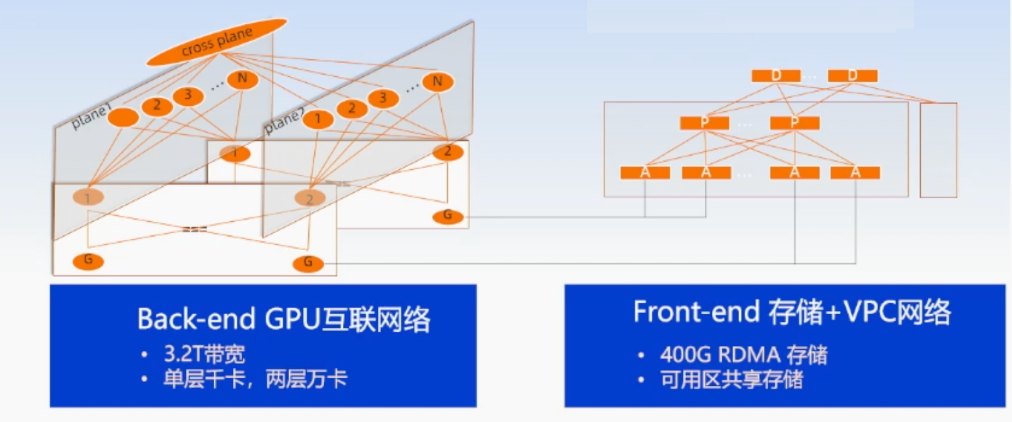
先说说从论文获取的信息,三层RoCE组网按1:1收敛比设计,整体组网拓扑如下图,每个Pod包含8个Segment。
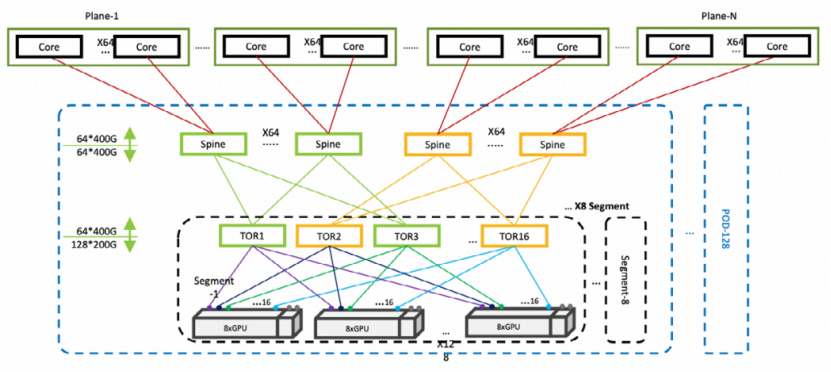
每个Segment包含16台Leaf交换机,总共2048个200Gbps下行端口,可连接128台GPU服务器(2048个200Gbps网口)。
因此,
每个Pod总共1024台GPU服务器(8192张GPU卡)。
每台Leaf 交换机有64个400Gbps上行端口和128个200Gbps下行端口,每个200Gbps下行端口对应GPU服务器的其中一个200Gbps网口。每台GPU服务器有16个200Gbps网口,上行需要对应16台Leaf交换机200Gbps端口。
每台GPU服务器采用8块双200Gbps网卡,一共16个200Gbps端口,采用双上联的方式,实现一个GPU对应两个上行链路,并且两个上行链路连接到不同的交换机,也就是每个Group内的128台GPU服务器,所有的1号NIC端口连接到Leaf交换机1号端口,16号NIC端口连接到Leaf交换机16号端口。
这种双上联设计,每个Segment的GPU数量及通信带宽翻番,
Segment内部GPU之间通信,只需要经过一个Leaf交换机,最多可以支持1024 张GPU卡互联,总通信带宽可以达到409.6Tbps。
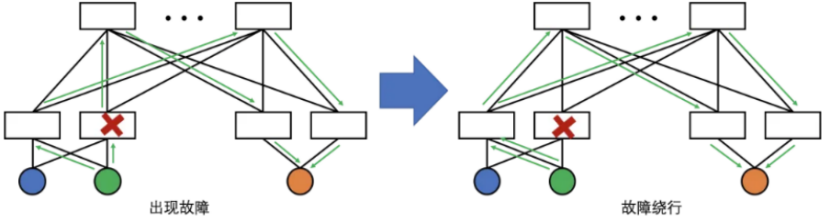
此外,双上联设计还
可以缓解网卡、交换机、光模块、光纤等导致的故障,例如,某一个上行链路故障或对应交换机故障时,流量可以切换到另一个端口提供服务而不至于训练任务中断(当然,可能会影响训练速度)。出现故障的情况下,流量绕行路径如下图所示。
以上是Core交换机与Spine交换机按1:1收敛比设计。对于我近期接触的一个Case,按1:15收敛比设计,可能是阿里基于自身流量的长期观测和建模。网络拓扑图如下所示(只画了3个Unit)。
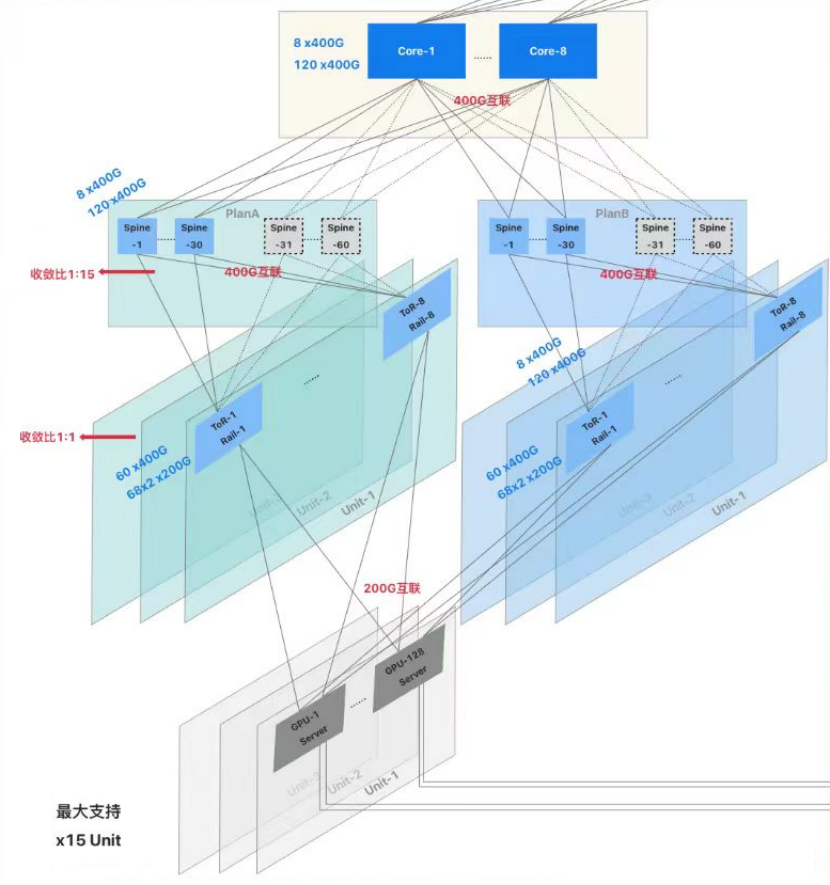
整个集群分为15个Unit,每个Unit一般128-136台GPU服务器。按双平面设计(Plan A和Plan B),每台GPU服务器16个200Gbps端口中,其中8个上联到Plan A,另外8个上联到Plan B。因此,整个集群最大可以支持2040台GPU服务器,1.6万张GPU卡。
每个Unit配16台Leaf交换机(Plan A、Plan B各8台),15个Unit满配240台。每台Leaf交换机的上、下行分别为60、68个400Gbps端口,其中下行的68个400Gbps端口可1分2为200Gbps,即每台Leaf交换机136个下行200Gbps端口。
满配情况下,Plan A和Plan B各配60台Spine交换机。每台Spine交换机的上、下行分别为8、120个400Gbps端口,Spine交换机下行的每个400Gbps端口对应1台Leaf交换机的上行400Gbps端口。
整个集群配置8台Core交换机,每台Core交换机的上、下行分别为8、120个400Gbps端口,下行的每个400Gbps端口对应1台Spine交换机。
