

标题:Agent 持续学习不只是训练模型:解读 Harrison Chase 的三层框架
摘要:Agent 持续学习落地路径:先做 Traces,再做 Context,最后才微调模型
本文来自投稿。
作者:Daniel,DeerFlow 联合作者。DeerFlow 是基于 LangGraph 的开源 SuperAgent 框架,专注多智能体编排,GitHub 60K+ Stars。长期深耕智能体工作流设计与有状态图执行,致力于将自主 Agent 真正推向生产环境的能力边界。
Agent 系统到底该怎么"持续变强"?
它依赖训练数据、训练基础设施和评测闭环,更像平台级能力,而不是普通产品团队可以频繁迭代的日常手段。
近期, LangChain 创始人 Harrison Chase 发布了一条 X 帖子出发,将 Agent 持续学习系统拆解为三层:Model(模型权重)、Harness(执行机制)、Context(可配置记忆),并结合 Meta-Harness、LangChain Deep Agents 等前沿工作,逐层分析每一层的学习方式、落地成本与适用场景。
基于这个分析,一套面向产品团队的可能行动路径是:先把 Traces 做对,再做 Context learning,然后建立 Harness optimization loop,最后才考虑模型微调。
锦秋基金认为,这对正在考虑把"持续学习"纳入 Agent 产品路线图的读者很有帮助,因此也做了转载。
一、Harrison Chase的一条 X
2026 年 4 月 5 日(北京时间),LangChain 创始人 Harrison Chase 发布了一条 X 帖子:

-
原帖地址:https://x.com/hwchase17/status/2040467997022884194?s=20
这篇内容的核心观点很明确:
对 AI agent 而言,“持续学习”不应只被理解为更新模型权重。一个 agent 系统实际上可以在三个层面持续进化:Model、Harness、Context。
二、核心框架:Agent 的三层学习
Harrison 把 agentic system 拆成三层:
-
Model:底层模型本身,也就是权重
-
Harness:驱动模型运行的“外壳”,包括 agent 代码、固定工具、固定提示、执行循环等
-
Context:位于 harness 外部的可配置上下文,例如记忆文件、技能、用户配置、团队配置
这一定义的价值在于,它把“学习”从单一的模型训练问题,扩展成了一个完整系统工程问题。
三、逐层解读
1. Model 层:最传统,但也是最重的一层
这一层对应大家最熟悉的持续学习:
-
用 SFT、RL 等方法更新权重
-
也可能采用更细粒度的适配方式,例如 LoRA
-
目标是让模型在新任务上做得更好
但这里有一个老问题没有消失:catastrophic forgetting。也就是模型在学习新东西之后,旧能力反而退化。
我的判断是:
-
对大多数团队来说,Model 层持续学习成本最高
-
它依赖训练数据、训练基础设施、评测闭环和模型发布机制
-
这更像平台级能力,而不是普通产品团队可以频繁迭代的日常手段
所以 Harrison 虽然承认模型层很重要,但他的真正重点并不在这里。
2. Harness 层:这是近一年 agent 工程最被低估的增益点
Harness 指的不是模型,而是“模型怎么被使用”:
-
系统提示词怎么写
-
工具怎么暴露给模型
-
调用循环怎样组织
-
什么时候截断上下文、什么时候重试、什么时候判断任务完成
-
哪些日志和 traces 被保存下来,供后续分析
Harrison 在文中点名了 https://yoonholee.com/meta-harness/ 这篇工作。它的思路可以概括为:
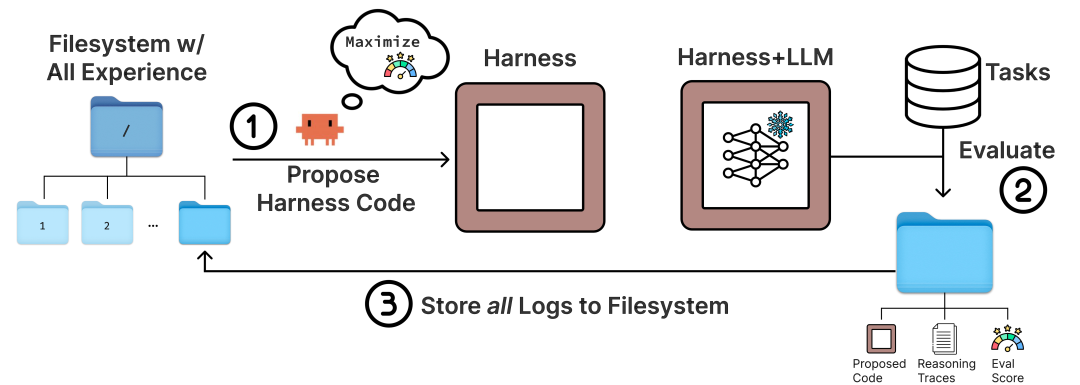
- .让 agent 在一批任务上运行
- .收集完整执行日志与得分
- .把这些历史候选、源代码、执行 traces 都保存在文件系统里
- .再让一个 coding agent 阅读这些材料,提出新的 harness 改动
- .评测新 harness,继续迭代
这很重要,因为它说明:
-
agent 的进化可以不改模型,只改运行框架
-
真正高价值的优化对象,往往是“执行机制”而不是“参数”
-
traces 越完整,harness 优化越像工程迭代,而不是拍脑袋改 prompt
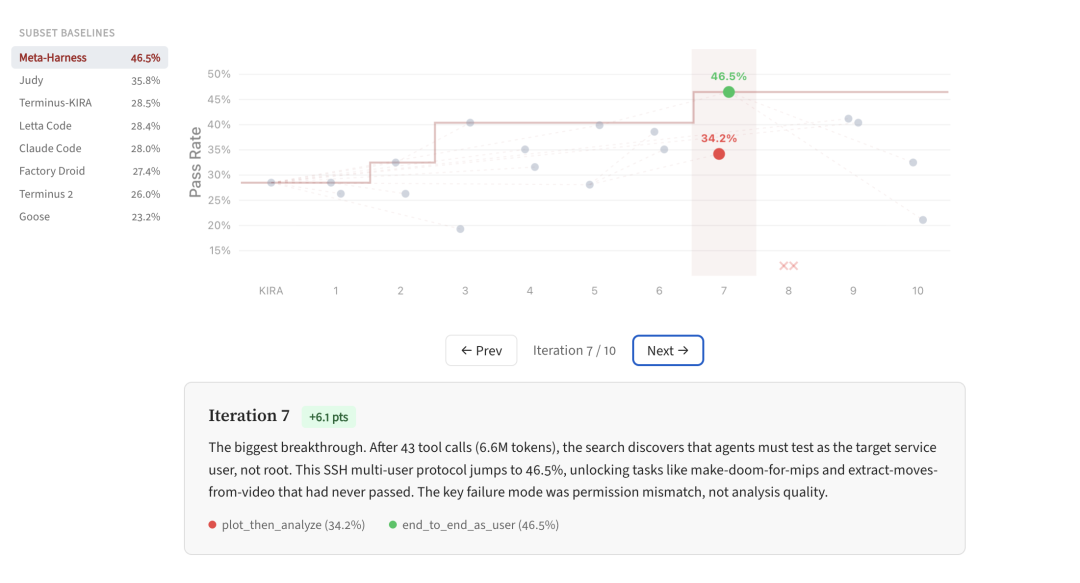
Meta-Harness 官方页面给出的结果也很强:它强调自己的关键差异是让优化器看到完整历史代码、分数与执行 trace,而不是只看摘要。作者称这种“文件系统级上下文”能把每轮优化可用诊断信息提升到远高于传统做法的量级。
3. Context 层:离业务最近,也最适合先落地
Harrison 把 Context 定义为位于 harness 之外、用来配置 agent 的内容,例如:
-
instructions
-
skills
-
tools
-
memory files
-
用户偏好
-
团队规则
这层的关键不在“模型学到了什么”,而在“系统记住了什么,并在之后的会话中如何继续使用它”。
LangChain Deep Agents 的官方文档把这件事讲得非常具体。它支持:
-
agent-scoped memory:所有用户共享同一份 agent 记忆
-
user-scoped memory:每个用户拥有独立记忆
-
在线更新:会话中直接写入记忆
-
后台整理:在会话外做 consolidation
-
skills 作为一种程序性记忆,只在需要时按需加载
这说明 Context 层并不是“多塞一点提示词”那么简单,而是一套可持久化、可分层、可读写、可检索的记忆系统。
四、作者举的两个例子
Harrison 在文章里用了两个 mapping:
Claude Code
-
Model:Claude Sonnet 等模型
-
Harness:Claude Code 本身
-
User context:CLAUDE.md、/skills、MCP.json
这个拆法非常实用,因为它直接说明:
-
你觉得“Claude Code 变聪明了”,未必是模型权重变了
-
也可能是 harness 改了
-
或者是你给它的上下文配置更好了
OpenClaw
-
Model:可以接多个模型
-
Harness:Pi 加上一些运行脚手架
-
Agent context:SOUL.md 与来自 ClawHub 的技能
我额外核对了 OpenClaw 的公开文档:
-
SOUL.md 被官方定义为 agent 的人格与语气配置文件
-
ClawHub 被定义为 OpenClaw 的 skills / plugins 公共注册表
这恰好印证 Harrison 的观点:很多 agent 系统的“持续学习”,本质上发生在可配置上下文层,而不是模型微调层。
五、这篇文章真正想推动的范式转移
如果把这篇文章提炼成一句话,我会写成:
Agent 的持续学习,正在从“训练模型”转向“优化完整系统”。
这里至少有三个变化:
1. 学习目标从权重转向系统行为
传统 LLM 持续学习更关注:
-
loss 有没有下降
-
benchmark 有没有提升
而 agent 持续学习更关注:
-
是否更会使用工具
-
是否更会规划步骤
-
是否更能从过去的失败里改进执行策略
-
是否更了解当前用户、团队或组织的偏好
2. 学习单位从单模型转向分层架构
同一个 agent 系统里,不同层的学习频率与代价完全不同:
-
Model:低频、高成本、平台级
-
Harness:中频、工程驱动、可评测
-
Context:高频、业务驱动、最容易在线发生
这意味着持续学习不该只有一个总开关,而应该是三套不同机制。
3. traces 成为统一燃料
Harrison 在文末反复强调 traces。这是全文最关键的基础设施判断之一。
原因很直接:
-
想改模型,要有 traces 作为训练/偏好数据来源
-
想改 harness,要有 traces 作为失败诊断材料
-
想改 context,要有 traces 作为经验提取素材
换句话说,没有高质量 traces,就没有高质量 agent learning loop。
六、个人的一些判断
1. Context 层会最先普及
我认为三层里最先大规模落地的是 Context 层,而不是 Model 层。
原因:
-
不需要训练 infra
-
对业务回报最直接
-
可按 user / team / org 做隔离
-
易于做权限管理和回滚
-
更容易符合企业系统对可控性的要求
很多今天被包装成“agent 会记忆了”的能力,本质上都属于这一层。
2. Harness 层会成为下一轮 agent 基建竞争焦点
如果 2024 年大家主要比拼“谁先把 agent 跑起来”,那么 2026 年更像是在比:
-
谁的 harness 更稳
-
谁的 traces 更完整
-
谁的评测与回放体系更闭环
-
谁能更快把失败案例沉淀为下一版 agent 行为改进
这也是为什么 Meta-Harness 这种工作值得重视。它代表一种很工程化的方向:让 agent 帮你改 agent。
七、对团队做 Agent 产品的实际思考
如果一个团队准备把“持续学习”纳入 agent roadmap,我建议按下面顺序推进:
第一阶段:先把 traces 做对
-
统一记录任务输入、工具调用、关键中间状态、输出结果、人工反馈
-
为失败任务保留可复盘证据,而不只是最终报错
-
给 traces 加上 user / org / task / version 维度标签
第二阶段:优先做 Context learning
-
从用户偏好、团队规则、术语表、操作 SOP 开始
-
区分只读记忆与可写记忆
-
明确作用域:哪些是 user 级,哪些是 org 级
-
支持在线写入与离线整理两种更新路径
第三阶段:建立 Harness optimization loop
-
把 agent 在标准任务集上持续运行
-
对 harness 版本做 A/B 对照和自动评测
-
让 coding agent 读取 traces,辅助提出 harness 改动候选
-
建立回滚机制,避免“改 prompt 一时爽,整体稳定性变差”
第四阶段:最后才考虑 Model-level learning
-
只有当你已经积累了足够多高质量 traces
-
并且 harness / context 层优化已经逼近上限
-
再进入微调或更系统的模型训练,投入产出比才更合理
八、一个可以直接复用的判断框架
遇到“agent 该怎么学”这个问题时,可以先问四个问题:
- .这次要改的,是模型能力、运行机制,还是可配置记忆?
- .这个改动,应该作用在 agent、user,还是 org 作用域?
- .这个更新,应该在运行中即时发生,还是在离线任务中整理后再生效?
- .有没有足够完整的 traces,支持评估这次学习是否真的有效?
如果这四个问题答不清楚,所谓“持续学习”大概率只是一个模糊口号。
九、结论
Harrison Chase 这条帖子和配套文章的价值,不在于提出某个全新算法,而在于把 agent 持续学习重新拆解为一个更实用的三层框架:
-
Model learning 解决底层能力
-
Harness learning 解决执行机制
-
Context learning 解决记忆与个性化
其中最值得产品团队立即行动的,不是训练模型,而是两件事:
-
建好 traces 基础设施
-
把 context 和 harness 的 learning loop 产品化
这也是我对这篇文章最核心的结论:未来更强的 agent,不一定先来自更大的模型,而更可能先来自更会“复盘、记忆、重构”的系统。
