

大家好,我是PaperAgent,不是Agent!
Meta/OpenAI/xAI联合发表了一篇在生产环境中规模化迭代优化高吸引力与可控的LLM的新成果:CharacterFlywheel。斯坦福最新OpenClaw论文:Agents of Chaos

当前大语言模型(LLM)的发展主要集中在助手型AI(如ChatGPT、Claude),目标是成为"全知全能的预言家"——知识渊博、乐于助人、真实无害。然而,另一类同样重要的场景——社交型AI(如Character.ai、Replika)——却缺乏系统性研究。
核心差异:
-
助手型AI:目标明确,有客观评测标准(MMLU、HumanEval等),奖励信号可验证 -
社交型AI:目标模糊主观("吸引力"、"像人"),缺乏标准化基准,难以进行强化学习
Meta等发现,社交聊天产品拥有数百万用户,但相关技术进展却"基本不透明"。CharacterFlywheel正是为了填补这一空白——如何在生产环境中,科学地、可测量地提升AI的社交对话能力。
二、核心贡献:15代迭代的"飞轮"方法论
从2024年1月到2025年4月,团队基于LLaMA 3.1进行了15个版本的迭代优化,最终部署在Instagram、WhatsApp、Messenger的AI角色聊天功能中。
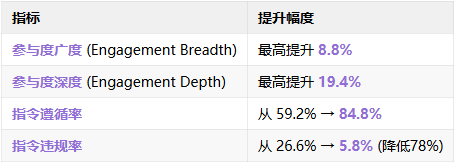
7/8的A/B测试显示正向提升,证明了该方法论的有效性。
三、方法论详解:CharacterFlywheel 架构
3.1 核心思想:爬山算法比喻
团队将整个优化过程比喻为在"吸引力地形"中爬山:
"Mountain identified. Time to climb." —— Ilya Sutskever

-
(a) Landscape Climbing: 整体优化轨迹,逐步攀登吸引力高峰 -
(b) Data Sampling: 在当前位置采样数据点,估计局部地形 -
(c) Pre-Herding: 训练奖励模型,插值出等高线(地形轮廓) -
(d) Herding: 基于估计地形,更新模型位置
3.2 完整开发流程
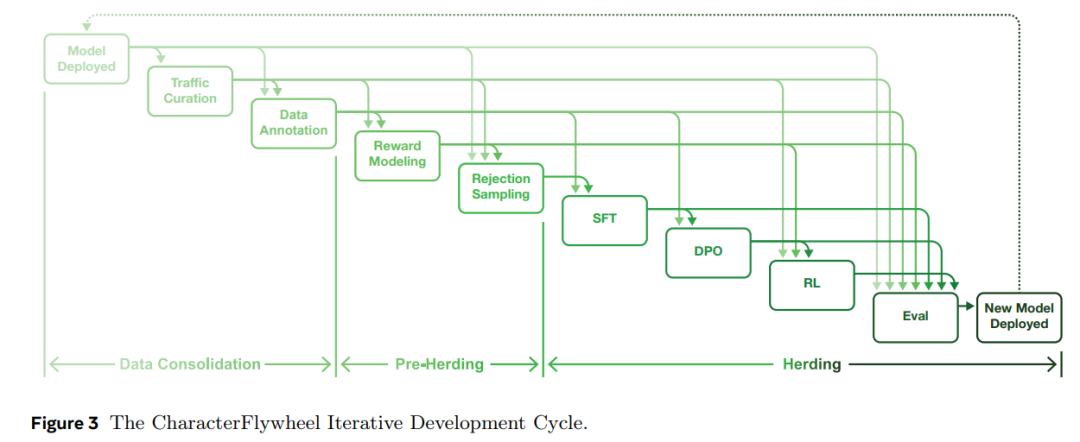
整个流程分为三个阶段:
1. 数据整合 (Data Consolidation)
-
流量筛选 (Traffic Curation) -
数据标注 (Data Annotation)
2. 预放牧 (Pre-Herding)
-
奖励模型训练 (Reward Modeling) -
拒绝采样 (Rejection Sampling)
3. 放牧 (Herding)
-
监督微调 (SFT) -
直接偏好优化 (DPO) -
强化学习 (RL) -
评估 (Eval) → 部署新版本
3.3 数据管道:从真实用户到训练数据
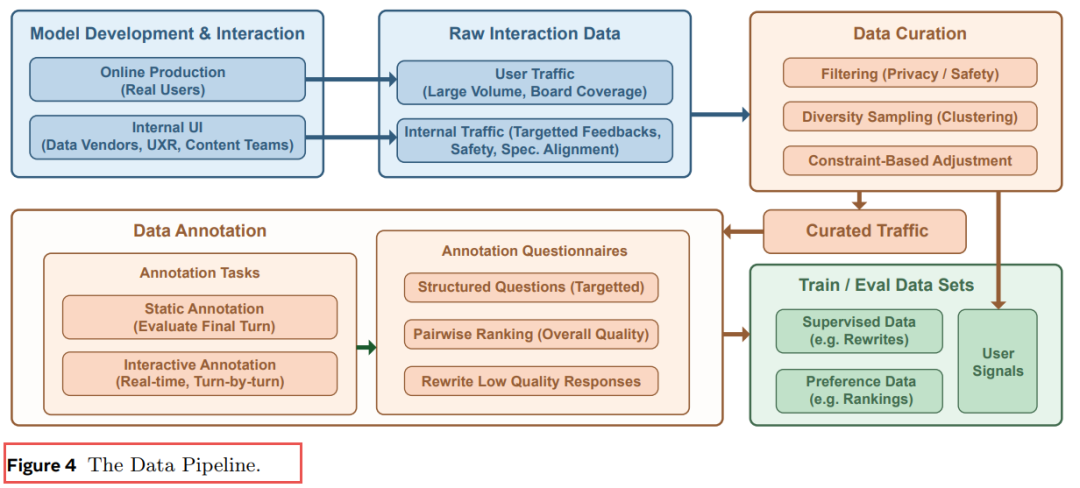
数据来源:
-
线上生产流量 (Online Production): 大规模、广泛覆盖的真实用户交互 -
内部UI流量 (Internal UI): 数据供应商、UX研究团队、内容团队的目标反馈
数据筛选三阶段:
|
|
|
|
|---|---|---|
| Phase I: 过滤 |
|
|
| Phase II: 多样性采样 |
|
|
| Phase III: 约束调整 |
|
|
四、奖励模型:如何量化"吸引力"?
4.1 双轨制偏好模型
由于"吸引力"不可微分,团队训练了替代模型来提供可微分的奖励信号:
Pointwise模型:独立为每个回复打分,通过比较分数确定偏好
-
损失函数:
Pairwise模型:联合编码两个回复,直接分类哪个更好
-
损失函数:
为什么需要两种?
-
Pointwise用于RL训练指导 -
Pairwise+Pointwise联合评估,缓解奖励黑客问题
4.2 用户信号模型
从真实用户行为中提取信号:
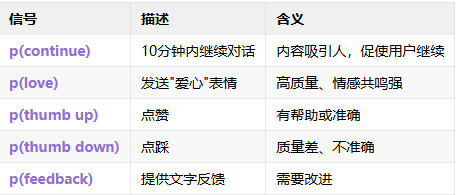
重要发现:用户信号模型不适合直接用于RL优化(易受奖励黑客攻击),但适合用于拒绝采样排序。
五、训练策略:SFT + DPO + RL 组合拳
5.1 拒绝采样 (Rejection Sampling)

核心逻辑:
-
从候选模型池中选择最适合当前提示的模型 -
生成k个候选回复 -
用奖励模型打分,只保留最高分 ≥ 阈值τ的样本 -
构建高质量SFT数据集
关键设计:虽然拒绝采样本质上是off-policy,但团队通过紧密的模型迭代循环(使用最新用户流量重建数据集),近似实现on-policy效果。
5.2 在线RL:从DPO到GRPO
团队对比了两种在线RL方法:
-
Online DPO: 标准在线直接偏好优化 -
GRPO (Group Relative Policy Optimization): 带重要性采样修正的变体
A/B测试结果:GRPO比Online DPO在参与度广度指标上提升**+1.52%**
原因在于GRPO能利用所有生成回复的奖励分数,提供更细粒度的监督信号。
5.3 风格伪影缓解
为了防止优化过度关注表面风格(如长度、表情符号),团队实施了伪影监控:
监控的特征包括:
-
回复长度 -
是否包含列表 -
表情符号数量 -
特定短语(如"I feel like…")
在偏好数据和拒绝采样数据中分别比较高低分回复的特征分布,防止风格与奖励信号虚假相关。
六、关键结果:15代迭代的演进轨迹
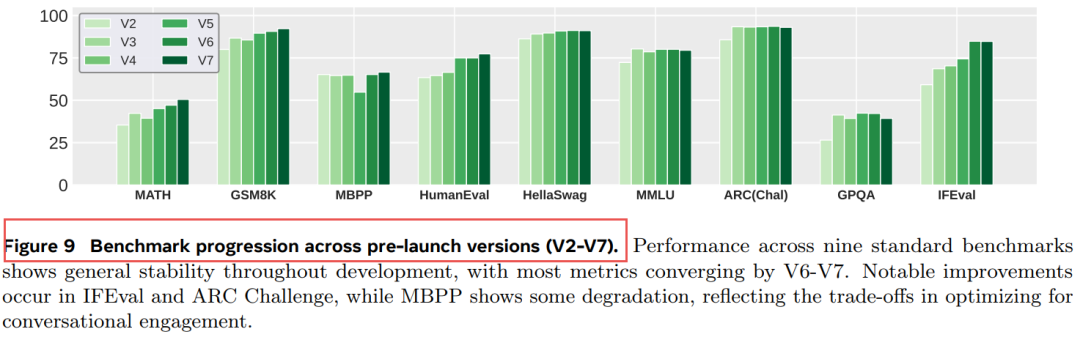
6.1 预发布阶段 (V1-V7):质量稳步提升
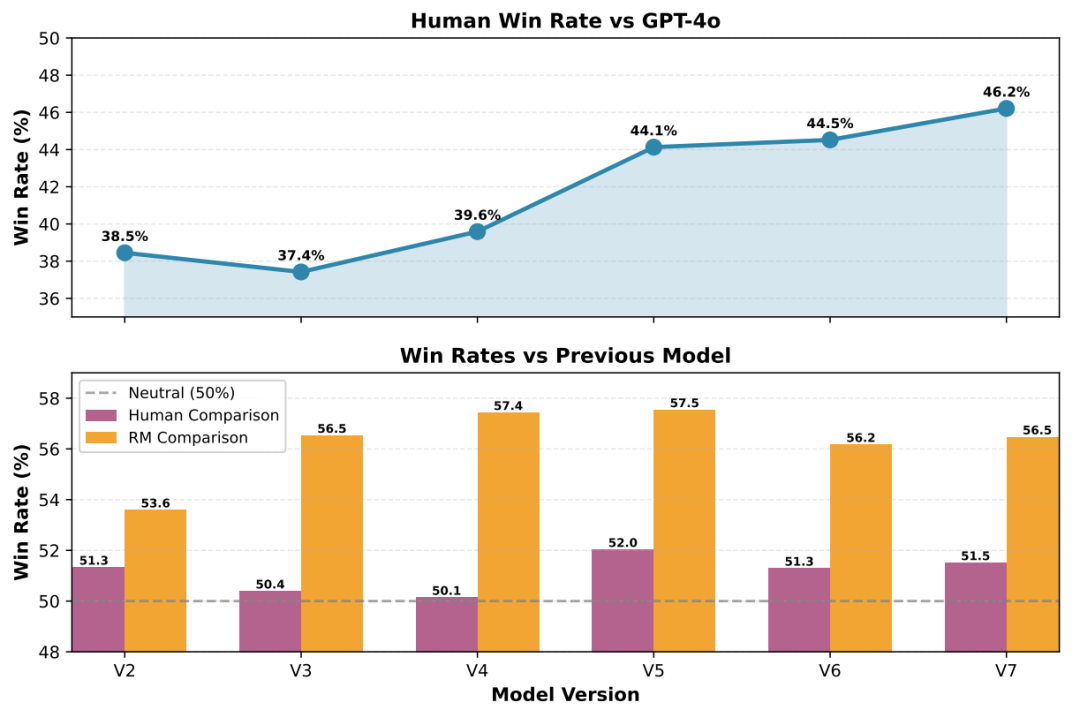
-
vs GPT-4o胜率:从37.4% (V3) → 46.2% (V7) -
vs 前一版本胜率:人工评估 50.2%-52.5%,RM评估 53.6%-57.6%,均超50%中性线
小规模A/B验证(Figure 7):
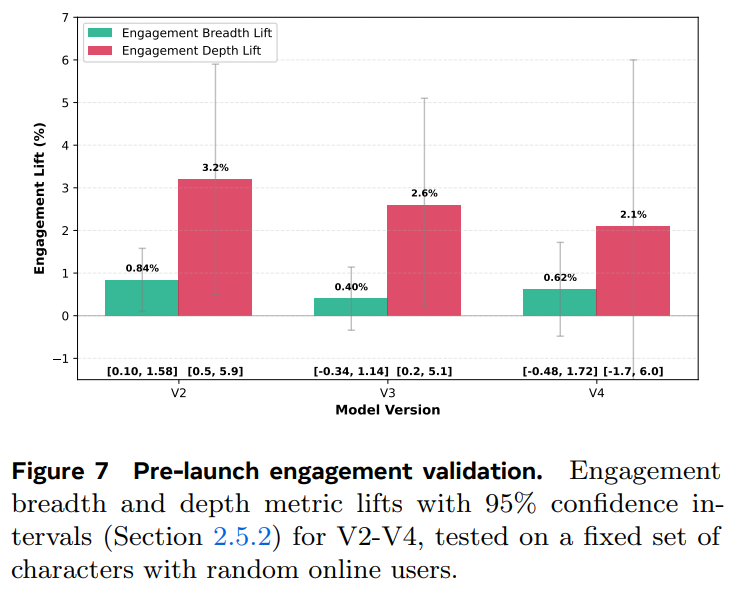
V2-V4均显示正向提升(尽管置信区间较宽),验证了离线优化与在线目标的一致性。
6.2 发布后阶段 (V8-V15):持续优化与关键教训
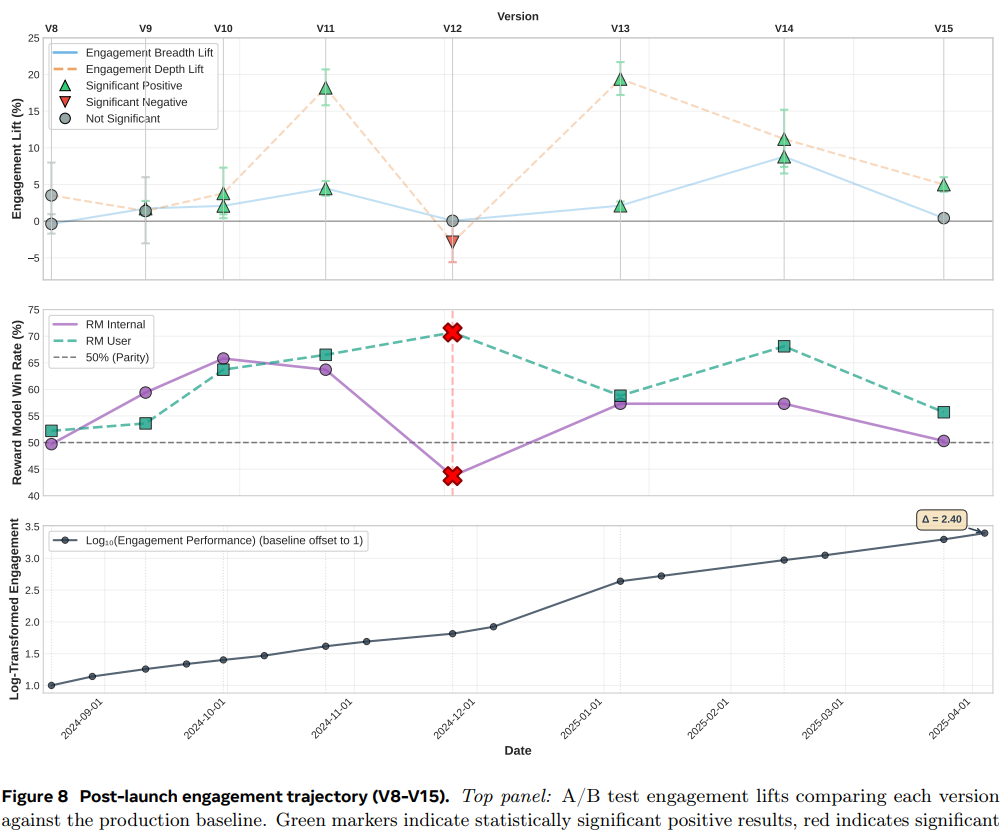
上图:A/B测试参与度提升
-
V11: +4.47% 广度, +18.2% 深度 ✅ -
V14: +8.8% 广度, +11.2% 深度 ✅ -
V12: +0.05% 广度, -2.9% 深度 ❌ (关键失败案例)
中图:奖励模型胜率
-
V12的RM User胜率飙升至**70.7%**,而RM Internal胜率跌至43.7% -
信号发散警告:当RM User > 65% 且与RM Internal差距过大时,表明过拟合
下图:累计参与度增长
-
尽管有V12的挫折,整体呈明显上升趋势(9个月增长约2.4倍)
七、关键发现与最佳实践
7.1 图像生成的影响
-
V9显式图像生成:+1.7% 参与度广度 -
V10隐式图像生成:额外+2.1% 参与度广度
隐式生成(AI自主决定何时生成图像)比显式生成更有价值,因为它能主动丰富对话而无需用户提示。
7.2 On-policy vs Off-policy
使用近策略提示(最新模型流量)vs 离策略提示(早期版本流量):
|
|
|
|
|---|---|---|
|
|
+10.6% |
|
|
|
|
|
核心洞察:要在策略空间中持续"爬山",必须使用能准确估计当前策略附近地形的样本。
7.3 基于方差的困难样本采样
标准启发式:选择RM平均分最低的提示("困难样本")
问题:RM分数未正则化,受风格因素(长度、轮数)影响大。长轮对话分数系统性地低,导致角色扮演/浪漫类提示过度采样4倍。
解决方案:方差采样
-
对每个提示采样多个回复,计算RM分数方差 -
困难提示会产生质量分布更宽的回复 -
方差是比均值更稳健的困难度信号
7.4 用户信号模型的局限性
虽然p(continue)和p(thumb up)与偏好RM高度相关,但直接用于RL优化会导致奖励黑客:

结论:用户信号模型适合拒绝采样排序(约束RM胜率<65%),不适合直接RL优化。
7.5 历史轮次的偏见传递
发现:即使从RM输入中移除所有表情符号("去偏见"),RL训练后表情符号使用率仍从0.2上升到0.48。
原因:自回归策略模型强烈模仿前几轮的风格,偏见直接来自对话历史而非RM。
解决方案:在训练提示中进行预处理,实施偏见监控和缓解。
https://arxiv.org/pdf/2603.01973
CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production