

#Unsloth AI 制作了一份 #LoRA 超参数掌握指南,做到正确微调大语言模型,学会使用更少幻觉训练更智能的模型、选择最佳学习率和参数配置、避免过拟合与欠拟合等关键技术。
关注公众号 #极客开源 👆 获取最新一手#AI大模型 #开源项目信息,如果这篇文章对你有用,可以点个“♥️推荐”,听说会影响公众号推荐算法。
Low-Rank Adaptation (LoRA) 是一种高效微调#大语言模型(#LLM)的技术。要训出高质量的 LoRA 模型,关键在于理解并合理配置其超参数。本文将深入探讨 LoRA 的核心超参数,解释它们如何影响训练过程,并提供一套解决常见训练问题(如#过拟合 与 #欠拟合)的实用策略。
最终的目标是训练出一个具备良好泛化能力的#模型,即模型不仅能在见过的任务上表现优异,也能在未见过的新任务上举一反三,而不是一个只会死记硬背训练数据的"书呆子"模型。
核心超参数解析
1. 学习率 (Learning Rate)
学习率定义了模型在每次训练迭代中更新自身权重的幅度。它可能是微调中最关键的超参数之一。
🌟推荐范围:对于 LoRA #微调,1e-4 (0.0001) 到 5e-5 (0.00005) 是一个常见的有效区间。通常可以从 2e-4 开始尝试。
2. 训练周期 (Epochs)
一个 Epoch 指的是模型完整地学习了一遍所有的训练数据。
🌟推荐值:对于大多数指令微调任务,1-3 个周期是黄金法则。训练超过 3 个周期,模型性能的提升会越来越小,而过拟合的风险却越来越大。
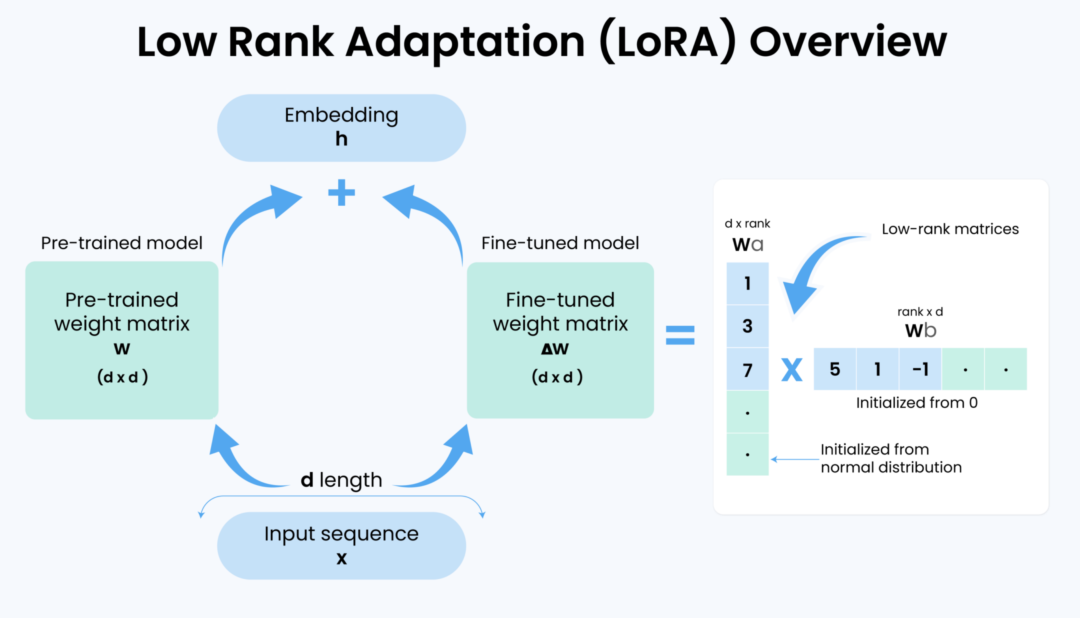
3. LoRA 秩 (Rank / r)
Rank (r) 控制 LoRA 适配器矩阵的大小,直接影响了为微调而新增的可训练参数量。
r 值:意味着模型有更大的容量去学习复杂的模式,但相应地会消耗更多显存、拖慢训练速度,并且也更容易导致过拟合。4. LoRA Alpha
Alpha 是一个缩放因子,用于调节 LoRA 矩阵对原始模型权重的影响强度。可以把它理解为微调效果的"音量"调节旋钮。
lora_alpha 的值等于 r。另一个流行且有效的技巧是将其设置为 r 的两倍 (lora_alpha = r * 2)。这会放大 LoRA 带来的调整,让模型更"专注"于学习新知识。5. 批次大小 (Batch Size) & 梯度累积 (Gradient Accumulation)
Batch Size 指的是模型每次更新权重前"看"多少个样本。而梯度累积是一种技巧,它允许用较小的 Batch Size 模拟出大 Batch Size 的训练效果。
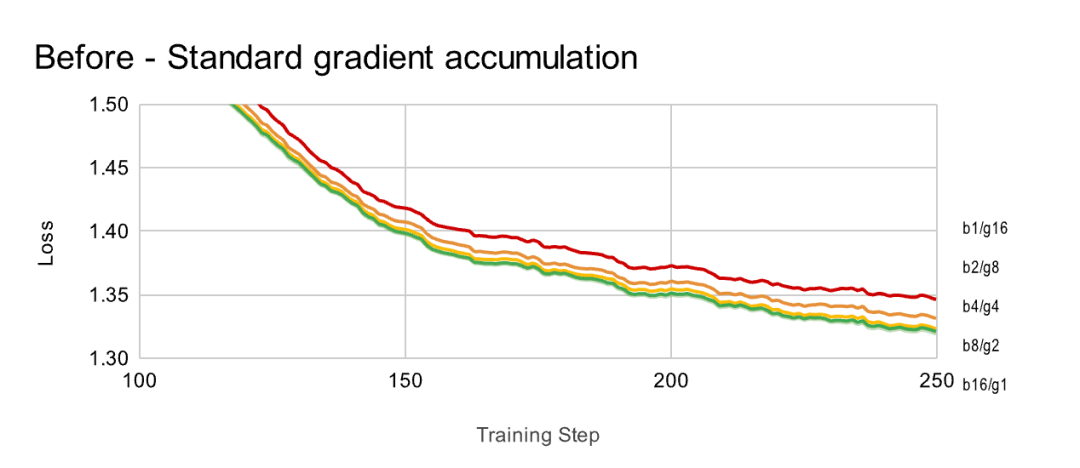
Batch Size × Gradient Accumulation StepsBatch Size 时,可以保持一个较小的 Batch Size (如 1, 2, 4),同时增加梯度累积步数,以此来间接实现大批次训练,这有助于稳定训练过程并减少过拟合。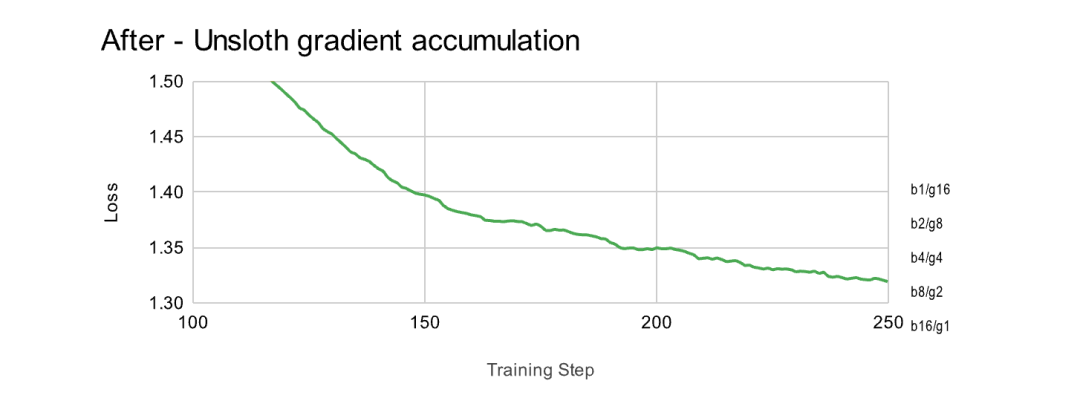
高级超参数速查
|
|
|
|
|---|---|---|
| LoRA Dropout |
|
0
0.1。如果怀疑模型过拟合,可以尝试设为 0.05 或 0.1。 |
| 权重衰减 (Weight Decay) |
|
0.01
0.1 是一个不错的起点。不宜设置过大。 |
| 调度器 (Scheduler) |
|
linear
cosine (余弦退火) 是最常用的选择。 |
| 随机种子 (Seed) |
|
42 或 3407。 |
诊断与解决常见问题
1. 如何应对"过拟合" (Overfitting)
当模型在训练集上表现完美,但在新数据上表现糟糕时,就发生了过拟合。
weight_decay 或 lora_dropout 的值。Batch Size 或梯度累积步数。lora_alpha 除以一个大于 1 的数,可以减弱微调的效果。2. 如何应对"欠拟合" (Underfitting)
当模型过于简单,连训练数据中的基本规律都没能学会时,就发生了欠拟合。
r 和 lora_alpha 的值。Unsloth 优化说明
不同的训练框架可能存在细微差异和独有的优化。
Batch Size 和 Gradient Accumulation 的组合效果在数学上是等效的。这意味着开发者可以放心地用增加梯度累积步数的方式来模拟大批次训练,以节省显存。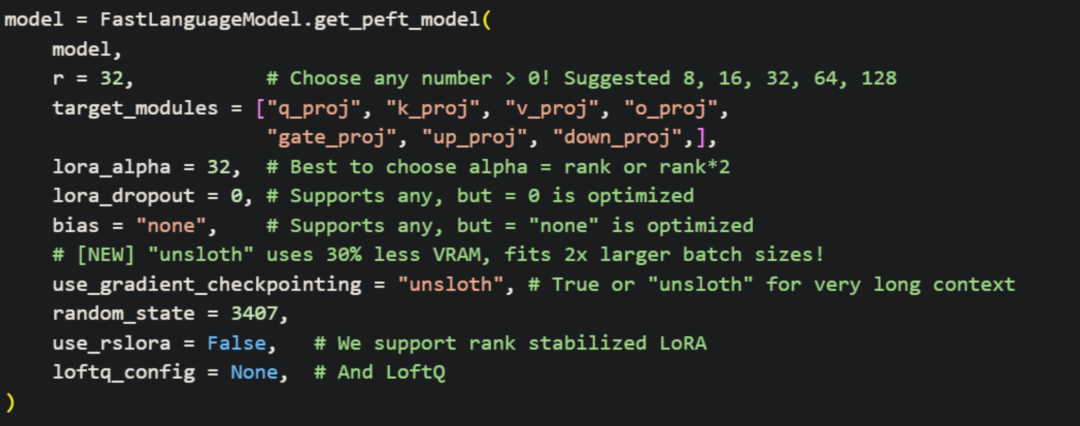
lora_dropout 设为 0、bias 设为 "none",或使用 use_gradient_checkpointing = "unsloth",都可以在保证性能的同时,加快训练速度并减少内存占用。在进行微调时,了解并利用这些框架特性,可以事半功倍。