
为何用公司数据做微调训练
- 操作:基于预训练好的模型(如DeepSeek-R1),使用公司内部的办公数据(如会议纪要、邮件模板、审批流程等标注数据),对模型进行二次训练。
- 目的:使模型适应特定任务或领域。让模型更贴合办公场景的专业术语、流程或风格(例如生成符合公司规范的报告、自动分类内部工单)。
-
需训练资源和时间,但远低于预训练。
微调流程大致包括:
-
确定任务和目标:
-
首先需要明确微调的任务是什么,比如文本分类、问答系统等,以及希望模型达到什么样的效果。 -
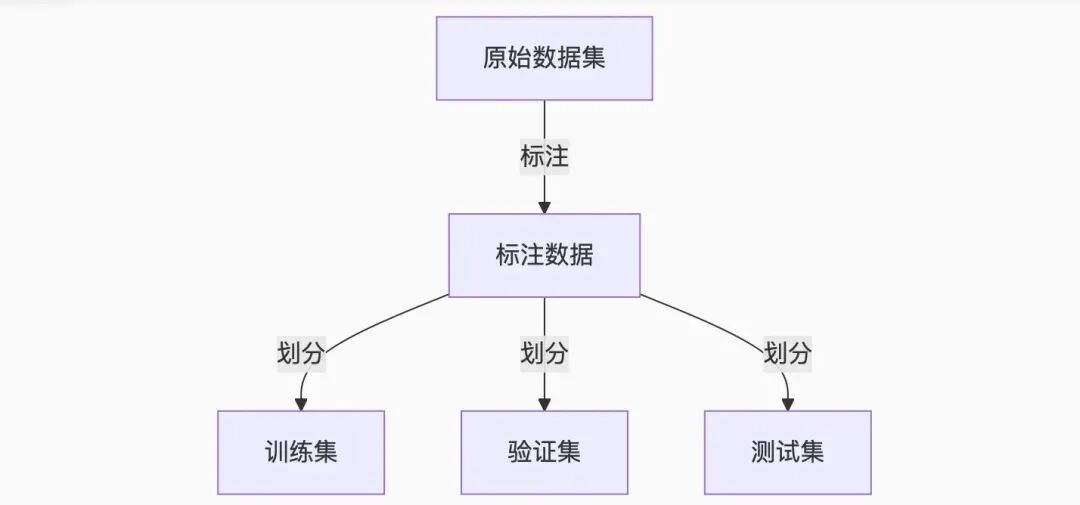
准备数据:

-
数据预处理:
将数据转换成模型可以接受的格式
-
选择预训练模型: 根据任务选择合适的预训练模型,如BERT、GPT、T5等。
-
调整模型结构:可能需要在预训练模型的基础上添加一些任务特定的层,比如分类任务加一个全连接层。
-
设置训练参数:确定学习率、批次大小、训练轮数(epochs)、优化器(如AdamW)、权重衰减、学习率调度等超参数。
-
训练过程: 在训练数据上进行微调,同时监控验证集的损失和指标,防止过拟合
-
评估与验证: 使用测试集评估模型性能,分析结果,可能需要调整超参数或数据
-
部署与应用: 将微调后的模型部署到生产环境,持续监控性能,可能需要迭代优化。
微调的其他知识点
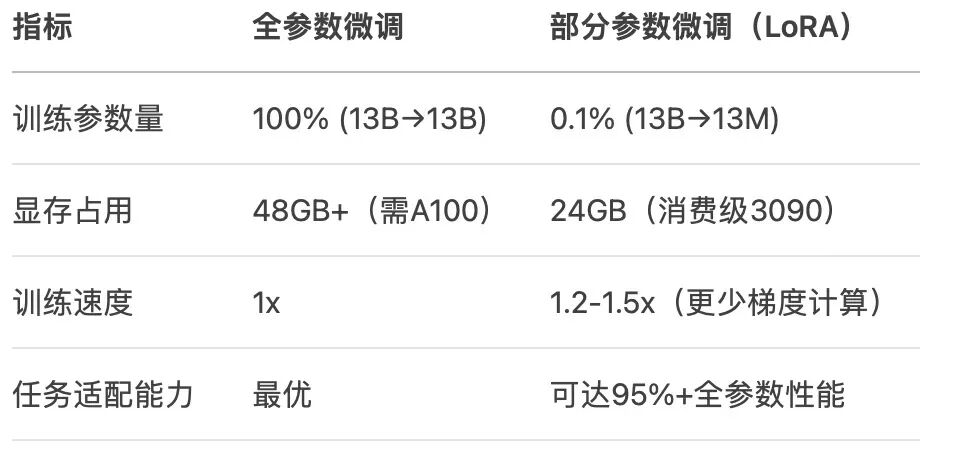
分为2种:全参数微调 和 部分参数微调
-
全参数微调/Full Fine-Tuning(更基础)
-
部分参数微调/PET(更高效)
以 LoRA、QLoRA、Adapter 为代表的PEFT方法成为主流,实现 <1%参数量微调 即可接近全参数性能。
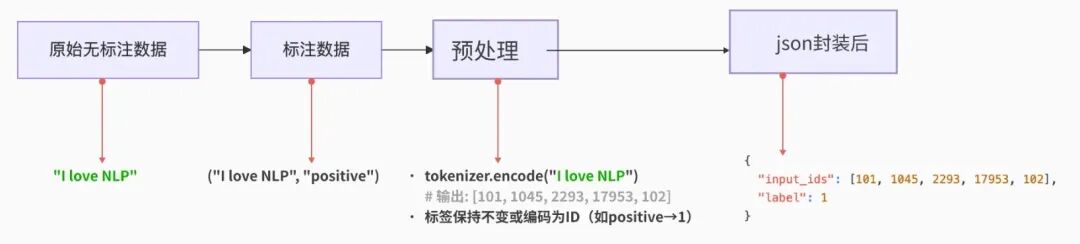
数据处理:
-
数据预处理:清洗、标准化、增强原始数据,使其适合模型输入。 -
json格式数据集:将预处理后的数据按特定结构(如json)组织,便于模型读取。(json格式,后端常用,通常为:key:value) -
将传统的“输入-输出”标注数据(如 (图像, 标签)或(文本, 答案)),转化为任务指令+输入+输出的形式,以增强模型对任务意图的理解和泛化能力。
instruction data/ 带明确任务指令的标注数据
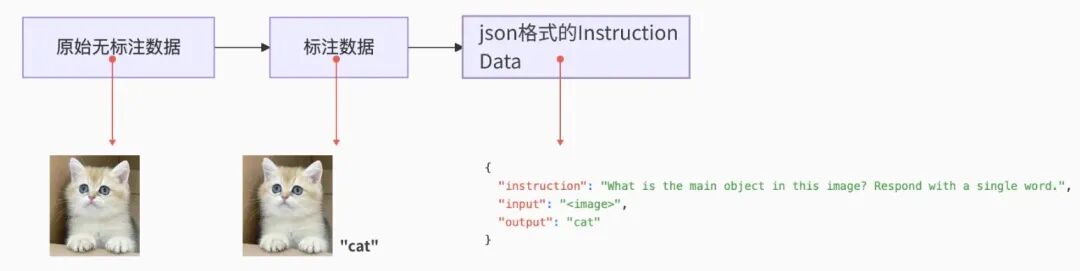
-
在微调时,不一定非要用 Instruction Data,取决于任务类型和模型类型。
-
必须用 Instruction Data:
情况1:任务需要模型理解复杂意图;
情况2:微调的是指令优化模型
-
可不用 Instruction Data:
情况1:任务本身简单直接;
情况2:模型本身不依赖指令
-
对比:
普通数据和instruction data对比 任务 普通数据格式 Instruction Data 格式 情感分类 {"text": "很好", "label": 1}{"instruction": "判断情感", "input": "很好", "output": "正面"}机器翻译 {"en": "Cat", "zh": "猫"}{"instruction": "翻译成中文", "input": "Cat", "output": "猫"}客服对话 {"user": "退款怎么操作?", "bot": "请登录网站申请..."}{"instruction": "作为客服回答用户问题", "input": "退款怎么操作?", "output": "请登录网站申请..."}
微调 & RAG & 蒸馏
-
Tunning 和Alignment都改变模型参数
-
微调本质上是一种训练,属于迁移学习:在预训练模型的基础上,通过继续训练使模型适应新任务。
-
微调技术是一个快速发展的领域,新的高效微调方法不断涌现。
-
RAG本质上不属于微调,它的核心在于不修改LLM本身的参数,而是通过外部知识检索与生成协同来提升模型表现。
-
蒸馏不是微调,尽管两者都属于迁移学习技术。蒸馏将大模型知识迁移到小模型,训练新模型(学生模型);微调是适配预训练模型到特定任务

