


-
数据分块与嵌入作业:通常需要将数据分块和嵌入代码抽象出来,并作为一个作业部署。有时,这个作业需要按计划运行,或者通过事件触发,以保持数据的更新。 -
查询服务:生成查询答案的代码需要封装在一个 API 服务器中,如 FastAPI,并作为服务部署。该服务应能够同时处理多个查询,并在流量增加时自动扩展。 -
大型语言模型/嵌入模型部署:如果我们使用的是开源模型,通常会在 Jupyter 笔记本中加载模型。在生产环境中,这需要作为独立的服务托管,并且模型需要作为 API 被调用。 -
向量数据库部署:大多数测试是在内存或磁盘上的向量数据库上进行的。然而,在生产环境中,数据库需要以更可扩展和更可靠的方式部署。
-
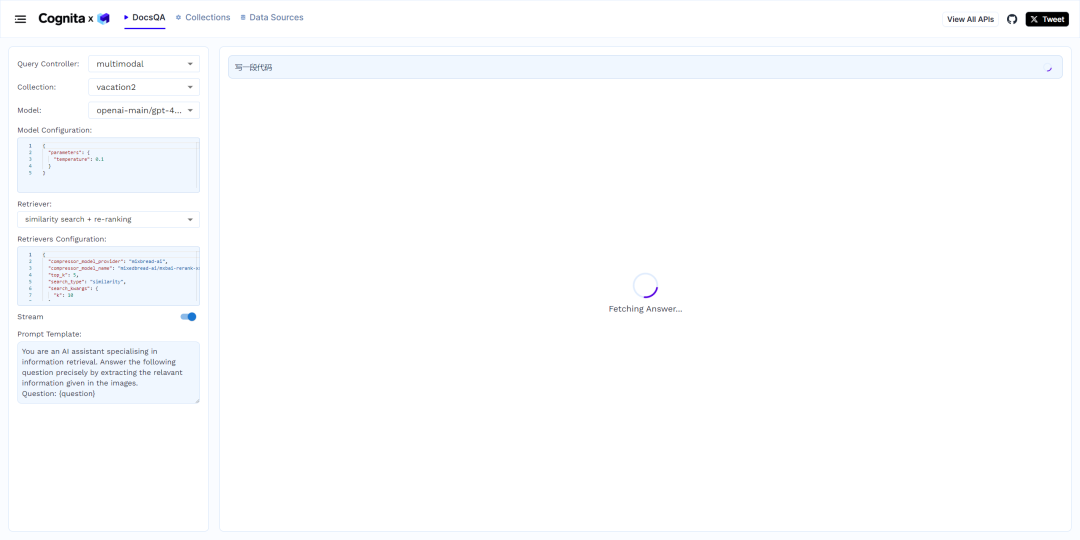
一个集中可复用的解析器、加载器、嵌入器和检索器库。
-
非技术用户可以通过用户界面进行操作——上传文档并使用开发团队构建的模块执行问答。
-
完全由 API 驱动——这允许与其他系统集成。
-
如果将 Cognita 与 Truefoundry AI 网关一起使用,您可以为用户查询获得日志记录、度量指标和反馈机制。
-
支持多种利用相似性搜索、查询分解、文档重排等功能的文档检索器。
-
支持使用 mixedbread-ai 提供的最先进的开源嵌入技术和重排技术。
-
支持使用 Ollama 技术利用大型语言模型(LLMs)。
-
支持增量索引功能,能够批量处理整个文档(减轻计算负担),跟踪已索引的文档,并防止这些文档的重复索引。
参考:
1.https://github.com/truefoundry/cognita?tab=readme-ov-file
2.https://cognita.truefoundry.com/
