



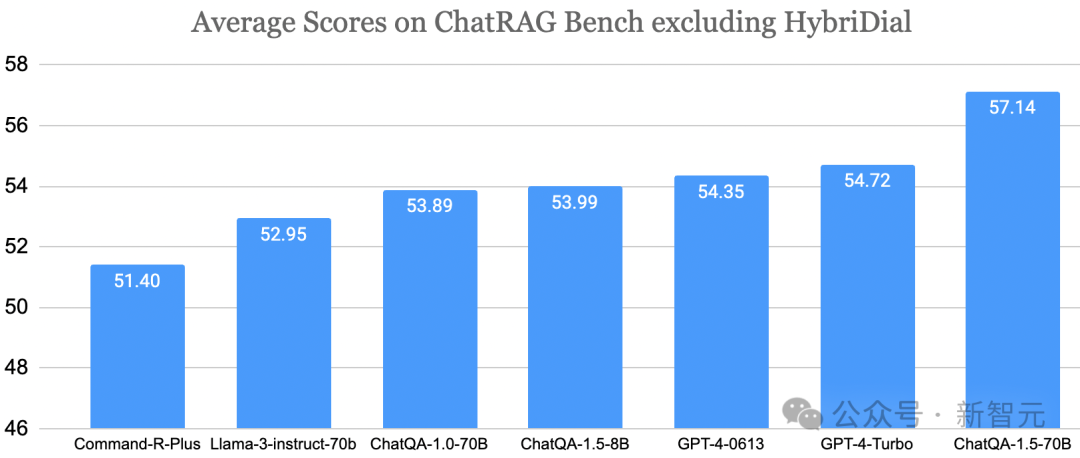
RankRAG微调框架
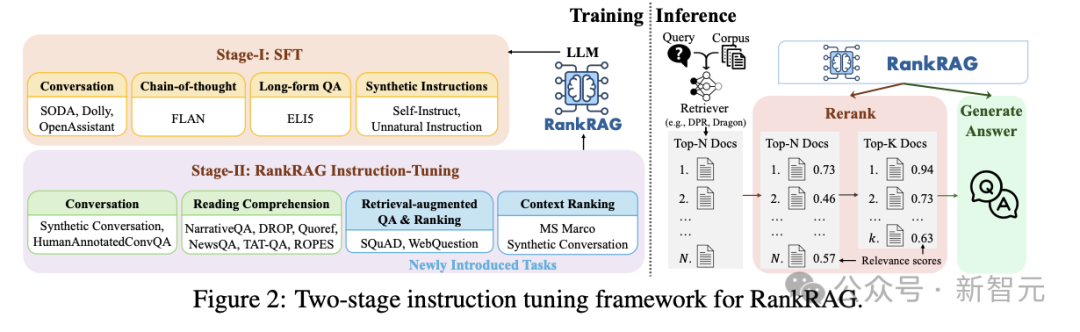
-
第一阶段的SFT数据:用于维持指令跟随能力
-
上下文丰富的QA数据:涵盖了DROP、NarrativeQA、Quoref、ROPES、NewsQA、TAT-QA等数据集,每条数据包含问题、黄金上下文(golden context)和答案
-
会话QA数据集:如Synthetic Conversation和HumanAnnotatedConvQA,同时包括对话内容以及一份背景文档
-
检索增强的QA数据:不仅包括SQuAD和WebQuestions中的问题和答案,还用BM25将黄金上下文和检索到的top结果组合起来,确保每条数据都有5个上下文,其中有些上下文可能不包括问题答案,甚至是hard-negative,这是为了重点提高LLM对不相关上下文的鲁棒性
-
上下文排名数据:使用流行的MS Marco语义相关性数据集,将其中的黄金样本视为相关的查询-段落对 (?,?+),BM25挖掘的hard negtive (?,?−)则被视为不相关,让LLM对这些样本的相关性进行二元分类(True或False)
-
检索增强的排名数据:同样使用QA数据集SQuAD和WebQuestions,以及BM25检索到的上下文,训练LLM的对相关性进行排名的能力

实验
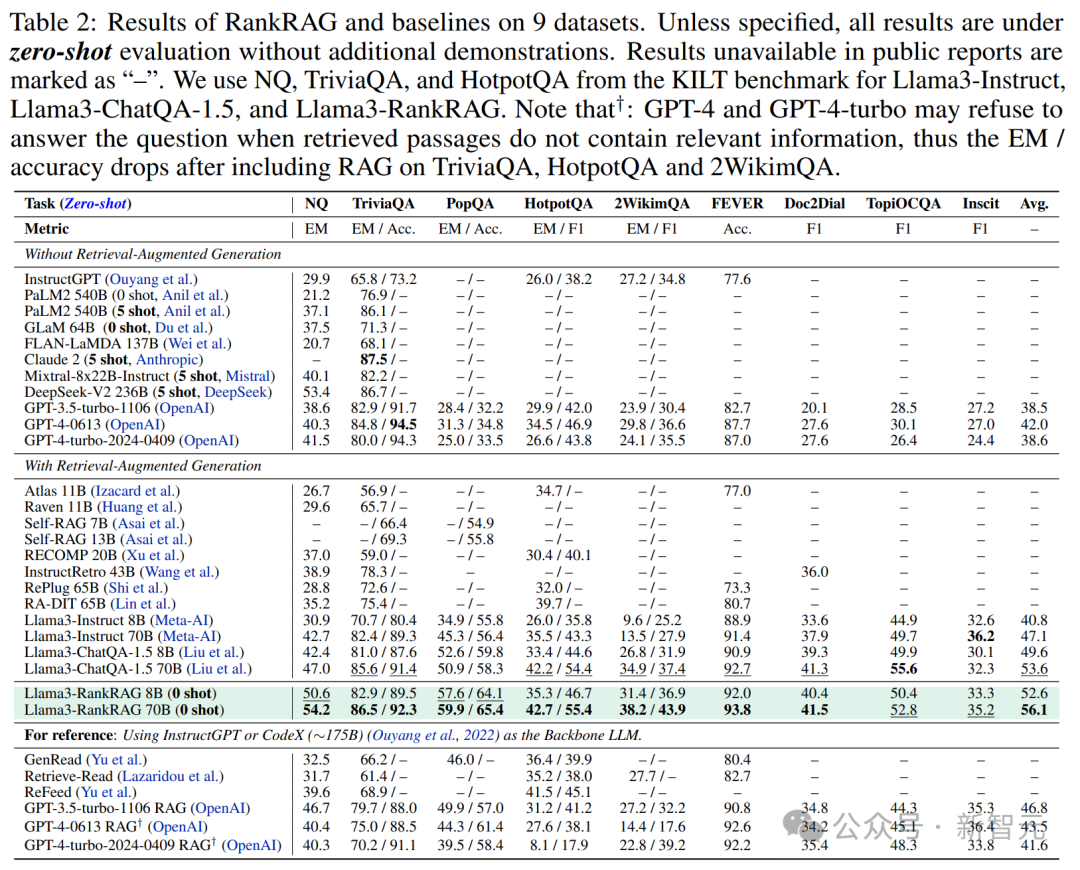
消融研究
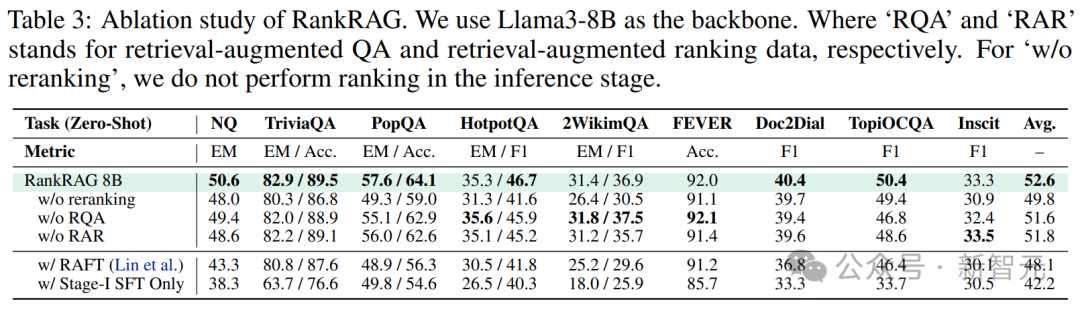
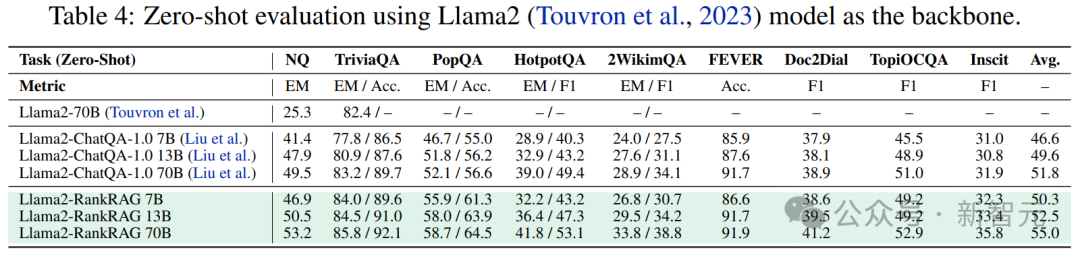
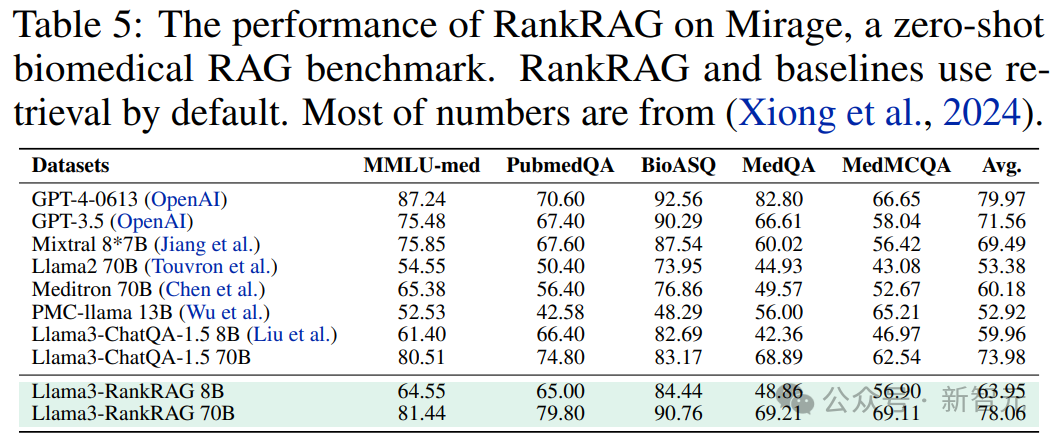
特定领域的RAG基准
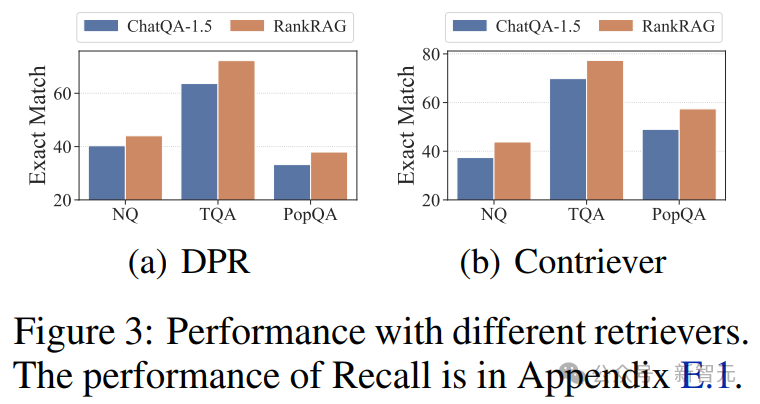
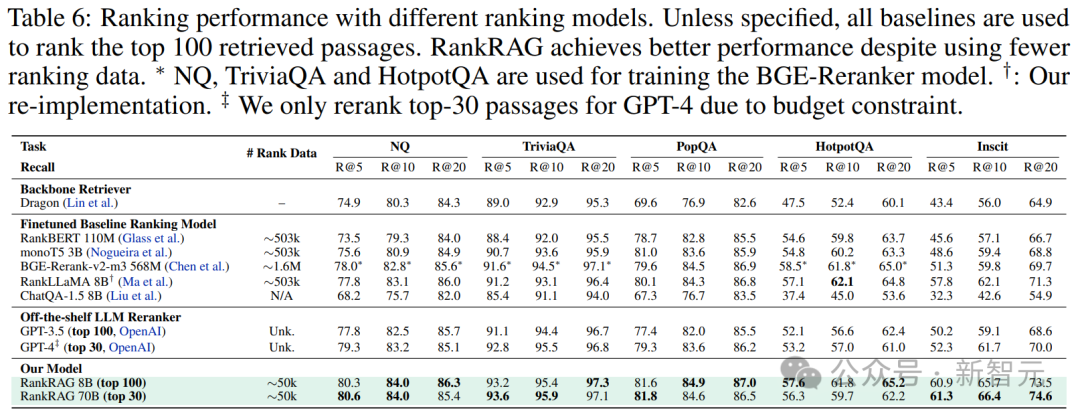
排名模块
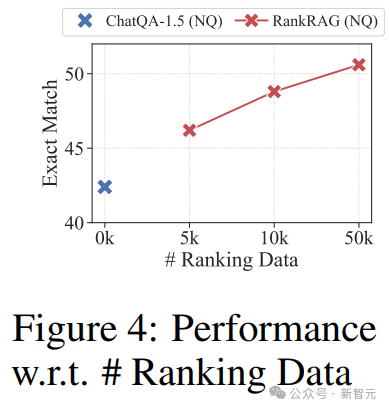
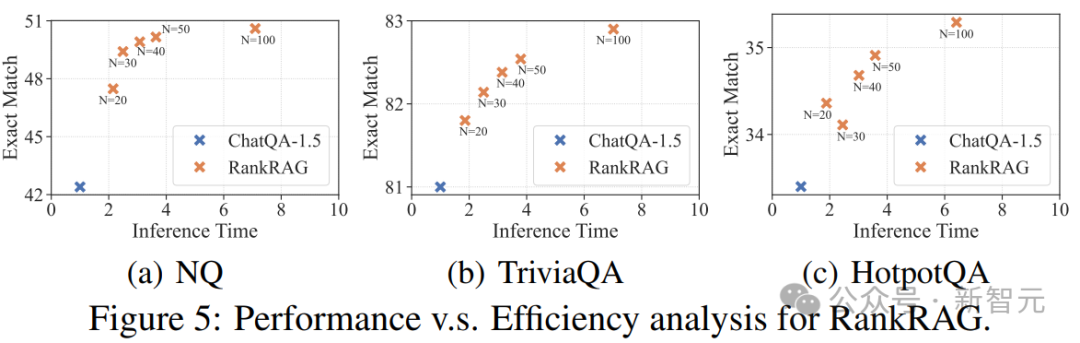
案例研究

